大语言模型(LLM)与多模态推理系统正迅速突破数据中心的局限。越来越多的汽车与机器人领域的开发者希望将对话式 AI 智能体、多模态感知系统和高级规划功能直接部署在端侧,因为在这些场景中,低延迟、高可靠性以及离线运行能力至关重要。
目前主流的 LLM 和视觉语言模型(VLM)推理框架主要围绕数据中心需求设计,例如应对大量并发用户请求并最大化其吞吐量,而嵌入式推理场景则需要一套专用的定制化解决方案。
本文介绍了 NVIDIA TensorRT Edge-LLM——一个用于 LLM 和 VLM 推理的新型开源 C++ 框架,旨在满足日益增长的高性能边缘端推理需求。该框架专为嵌入式汽车平台 NVIDIA DRIVE AGX Thor 及机器人平台 NVIDIA Jetson Thor 上的实时应用而打造。该框架已在 GitHub 上随 NVIDIA JetPack 7.1 版本发布并开源。
TensorRT Edge-LLM 依赖项很少,专为实现量产级边缘端应用部署而设计。其精简轻量化的设计专注于嵌入式场景的特定功能,能够显著降低框架的资源占用。
此外,TensorRT Edge-LLM 所具备的先进功能——如 EAGLE-3 投机采样、NVFP4 量化支持以及分块预填充技术,能够满足高要求的实时应用场景所需的前沿的性能需求。
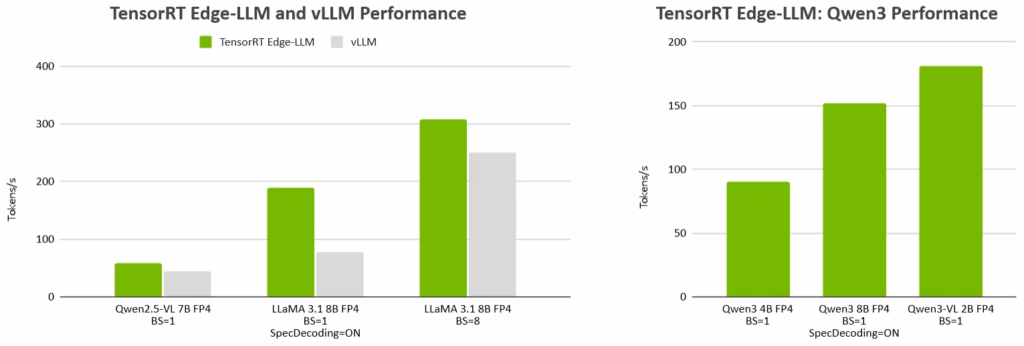
图 1. 与主流 LLM 和 VLM 推理框架 vLLM 相比,TensorRT Edge-LLM 性能表现卓越。
面向实时边缘端应用的 LLM 与 VLM 推理
边缘端 LLM 推理任务和 VLM 推理任务具有以下特征:
请求来自少数或单一用户
批处理规模较小,通常需跨多个摄像头输入
面向关键任务应用的量产级部署
支持离线运行且无需更新
因此,机器人和汽车领域的实时应用提出了以下特定要求:
延迟低且可预测
最小化磁盘、内存和计算资源的占用
符合量产标准
高鲁棒性和高可靠性
TensorRT Edge-LLM 旨在满足并优先处理这些嵌入式场景的特定需求,为嵌入式 LLM 和 VLM 的推理提供坚实基础。
TensorRT Edge-LLM 在汽车行业的落地应用
合作伙伴已开始将 TensorRT Edge-LLM 作为其车用 AI 产品的基础,其中博世、中科创达和 MediaTek 等企业在 CES 2026 上展示了其相关技术。
博世与 NVIDIA 及微软共同开发新一代博世智能座舱,该座舱搭载的车载 AI 助手具备自然语音交互能力。该解决方案集成了嵌入式自动语音识别(ASR)与文本转语音(TTS)AI 模型,并通过 TensorRT Edge-LLM 实现 LLM 推理,从而构建了一个强大的车载 AI 系统。同时,该系统还可通过精密协调器与云端的大型 AI 模型协同运作。
中科创达将 TensorRT Edge-LLM 集成至其即将推出的 AIBOX 平台,该平台基于 NVIDIA DRIVE AGX Orin 架构,旨在为车内提供响应迅速的车端 LLM 及多模态推理能力。通过整合中科创达的汽车软件栈与 TensorRT Edge-LLM 的轻量级 C++ 运行时及优化解码路径,该 AIBOX 能在严苛的功耗和内存限制下,提供低延迟的语音交互与座舱辅助体验。
MediaTek 在其 CX1 系统级芯片中基于 TensorRT Edge-LLM 进行开发,以支持先进的座舱 AI 与人机交互应用。TensorRT Edge-LLM 加速了 LLM 和 VLM 的推理过程,适用于多种应用场景,包括驾驶员和座舱活动监测。同时,MediaTek 通过开发新型嵌入式专用推理方法,持续反哺 TensorRT Edge-LLM 的技术演进。
随着 TensorRT Edge-LLM 的发布,这些 LLM 和 VLM 的推理能力现已面向 NVIDIA Jetson 生态系统开放,可为机器人技术提供基础支撑。
TensorRT Edge-LLM 技术解析
TensorRT Edge-LLM 旨在为 LLM 和 VLM 的推理提供一个端到端工作流。该流程涵盖三个阶段:
将 Hugging Face 模型导出为 ONNX 格式
针对目标硬件构建优化的 NVIDIA TensorRT 引擎
在目标硬件上运行推理任务
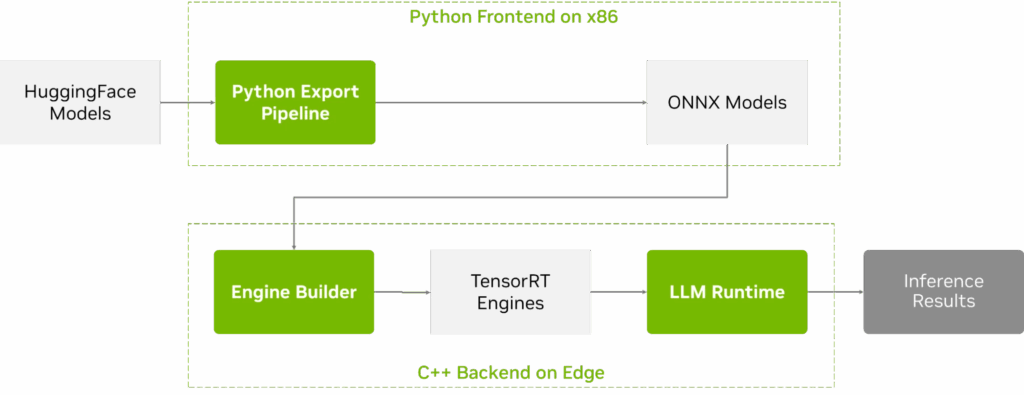
图 2. TensorRT Edge-LLM 工作流及关键组件
Python 导出流程能够将 Hugging Face 模型转换为 ONNX 格式,并支持量化、LoRA 适配器和 EAGLE-3 投机采样(图 3)。
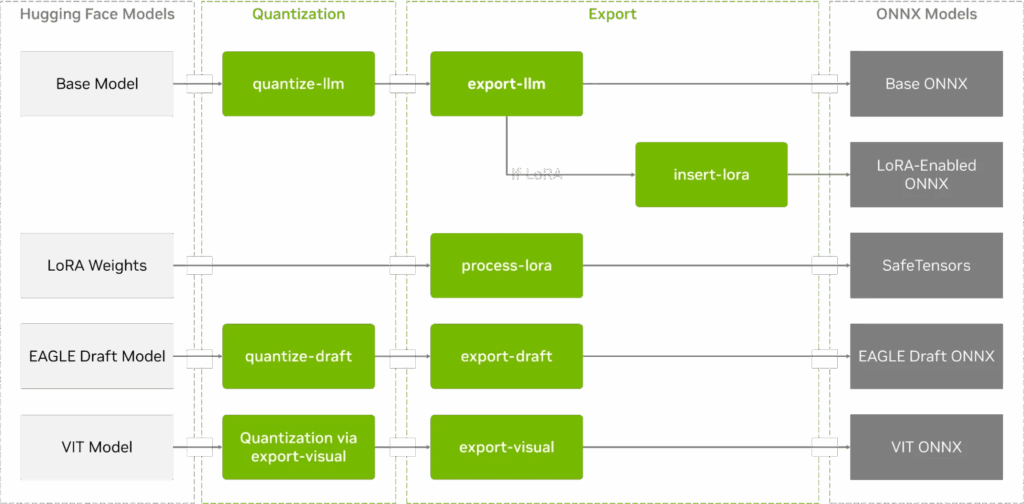
图 3. TensorRT Edge-LLM Python导出流程阶段与工具
引擎构建器负责构建专为嵌入式目标硬件优化的 TensorRT(图 4)。
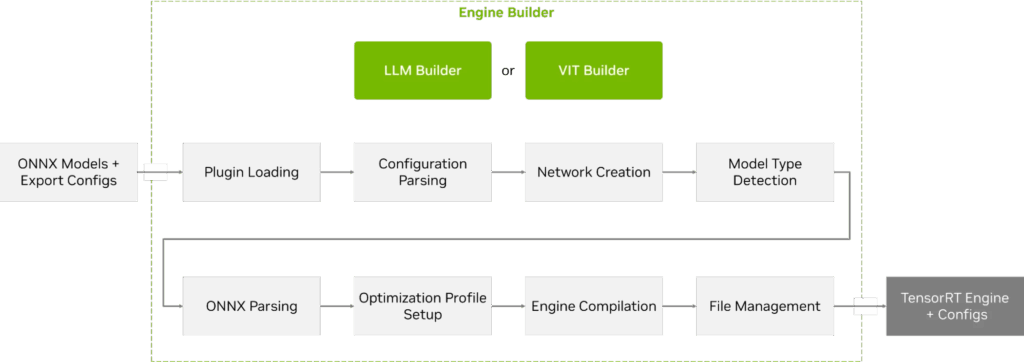
图 4. TensorRT Edge-LLM 引擎构建器工作流
C++ 运行时负责在目标硬件上执行 LLM 和 VLM 的推理任务。它利用 TensorRT 引擎来实现自回归模型解码循环:即基于输入和先前生成 token 进行迭代式的 token 生成。用户应用程序通过与该运行时交互,来处理 LLM 和 VLM 的工作负载。
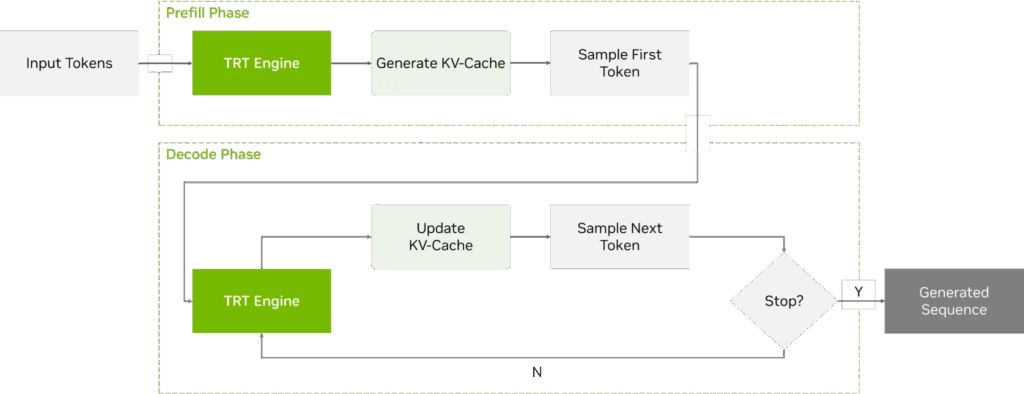
图 5. TensorRT Edge-LLM C++ 运行时的预填充与解码阶段
如需了解上述各组件的更多说明,请参阅 TensorRT Edge-LLM 的完整文档。
开始使用 TensorRT Edge-LLM
准备好在您的 Jetson AGX Thor 开发套件上开始 LLM 和 VLM 推理了吗?
下载 JetPack 7.1 版本
克隆 NVIDIA/TensorRT-Edge-LLM GitHub 仓库的 JetPack 7.1 发布分支:
git clone https://github.com/NVIDIA/TensorRT-Edge-LLM.git
查阅 TensorRT Edge-LLM 快速入门指南,了解如何从 Hugging Face 获取开箱即用的支持模型、并将其转换为 ONNX 格式、为 Jetson AGX Thor 平台构建 TensorRT 引擎,以及最终通过 C++ 运行时进行运行的完整步骤。
参阅 TensorRT Edge-LLM 示例,了解更多特性和功能。
若需根据自身需求定制 TensorRT Edge-LLM,请参阅 TensorRT Edge-LLM 定制指南。
对于 NVIDIA DRIVE AGX Thor 用户,TensorRT Edge-LLM 已作为 NVIDIA DriveOS 发行包的标准组件提供。后续 DriveOS 版本将通过 GitHub 仓库进行发布。
随着 LLM 和 VLM 快速向边缘端迁移,TensorRT Edge-LLM 提供了一条清晰可靠的路径,能够将 Hugging Face 模型直接部署至 NVIDIA 汽车和机器人平台,实现实时、量产级落地。
探索工作流,充分测试模型效果,并着手构建下一代智能端侧应用。了解更多信息,请访问 NVIDIA/TensorRT-Edge-LLM GitHub 仓库。
致谢
感谢 Michael Ferry、Nicky Liu、Martin Chi、Ruo Cheng Jia、Charl Li、Maggie Hu、Krishna Sai Chemudupati、Frederik Kaster、XiangGuo、Yuan Yao、Vincent Wang、Levi Chen、Chen Fu、Le An、Josh Park、Xinru Zhu、Chengming Zhao、Sunny Gai、Ajinkya Rasani、Zhijia Liu、Ever Wong、Wenting Jiang、Jonas Li、Po-Han Huang、Brant Zhao、Yiheng张和 Ashwin Nanjappa,感谢你们对 TensorRT Edge-LLM 的贡献和支持。
关于作者
Lin Chai 是 NVIDIA 的高级产品经理,负责领导 TensorRT 和 TensorRTEdge-LLM,这是 NVIDIA 跨数据中心和嵌入式平台深度学习的 AI 推理平台。凭借在自动驾驶和汽车原始设备制造商 (OEM) 方面的背景,她受到启发,想要构建生产级推理系统,为数据中心、边缘和物理 AI 应用中的深度学习工作负载提供一流的性能,使系统能够在现实世界中感知、推理和行动。
Felix Friedmann 是 NVIDIA DRIVE 平台的产品和工程主管,涵盖 NVIDIA 嵌入式 AI 推理和 NVIDIA DriveWorks。他将嵌入式视觉语言模型等最新技术创新与汽车软件平台所需的可靠性和安全性相结合。自 NVIDIA DRIVE 平台问世以来,Felix 一直在前一个职位上与之合作,当时他在奥迪将早期的深度学习模型引入嵌入式应用程序,并为 atVW 的 AID 智能汽车和后来的 Argo AI 设计了感知和系统架构。
Luxiao Zheng 是 NVIDIA 的高级系统软件工程师。他是 TensorRT 一般性能团队的成员,专门从事大语言模型推理工作流程。他从事 x86_64 和 aarch64 平台的端到端 LLM 软件开发、性能测量、分析和改进。陆晓持有理科硕士学位。计算机科学专业,理学学士学位。计算机科学和理学学士学位。华盛顿大学化学工程专业的博士学位。
Fan Shi 是 NVIDIA TensorRT 团队的高级系统软件工程师,专门负责在边缘平台上高效部署先进的 AI 模型。他的工作重点是优化深度学习推理的性能和可用性。风扇拥有 M.S。卡耐基梅隆大学计算数据科学博士学位和理学学士学位。来自伊利诺伊大学的统计学和计算机科学博士学位。
Amber Liu 是 NVIDIA 的高级系统软件工程师,专注于边缘 AI 和大语言模型应用。她与中国的客户和合作伙伴密切合作,在自动驾驶、AI 驾驶舱和机器人领域实现 LLM 用例,帮助团队构建生产就绪型边缘 AI 系统。作为 TensorRT Edge™ LLM 的核心贡献者,她致力于开发高性能推理解决方案,将先进的大语言模型引入嵌入式平台。
原文标题:CES 2026 | NVIDIA TensorRT Edge-LLM 加速汽车与机器人领域的 LLM 和 VLM 推理
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。







评论区
登录后即可参与讨论
立即登录