在生成式人工智能以万亿参数模型重塑产业格局的当下,算力基础设施正在经历一场前所未有的极限测试。国际能源署预测,到2026年,全球数据中心电力消耗将升至 650—1050TWh;与此同时,单机柜功率密度也正从传统 IDC 时代的 10kW 级,快速跃升到 132kW、600kW,并继续向 MW级机柜 逼近。面对这一变化,整个行业几乎在本能地寻找“特效药”:液冷、SST、800V HVDC、中压直入、集装箱式智算中心,成为最热的技术关键词。
这些方向都对,也都重要。但问题在于,今天行业对 AIDC 的理解,仍然存在一个根本性偏差:把它看成了一个单一散热问题,或者单一供电效率问题,这正是判断失焦的起点。
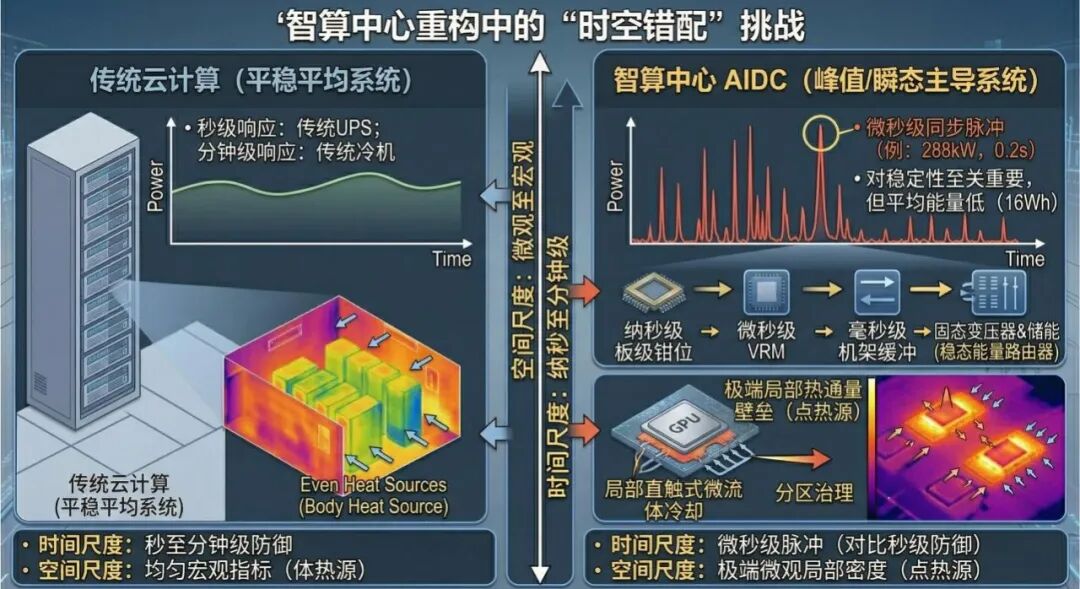
如果进入 IT 设备的电能,绝大部分仍被低效降压网络、无效数据搬运、瞬态冲击和热节流所吞噬,那么即便把 PUE 做到极致,也不过是在建造一座效率更高的“废热焚烧炉”。AIDC 的真正矛盾,已经不是“热能不能带走”,而是算力负载释放功率与热量的方式,已经变了;而基础设施仍在用上一代平稳负载思维去承接它。这就是本文要讨论的第一性问题:时空错配。
一、PUE没有错,但单独讲PUE已经过时了
必须先澄清一个容易引发误解的问题:严格说,PUE并没有“死”。它依然是衡量数据中心总能效的重要指标。问题不在 PUE 本身,而在于继续把 PUE 当成 AIDC 的第一核心指标,已经不够了。
原因很简单。PUE 只能回答“机房总电能里有多少进入了 IT 设备”,但它无法回答以下更关键的问题:
第一,进入 IT 设备的电,最终有多少真正变成了有效算力,而不是在板级供电网络和无效数据搬运中变成热。
第二,GPU 在高同步训练和推理负载下,是否因为瞬态电压跌落和热点失控而发生热节流、降频或中断。
第三,为了对抗这些高频冲击,数据中心究竟冻结了多少本来可以上线的容量。
第四,系统是否具备持续、稳定、可交付的“有效 GPU 小时”,而不仅是名义上的上电能力。
也就是说,在传统 IDC 时代,PUE 是一个足够有代表性的总量指标;但到了 AIDC 时代,仅盯住 PUE,就会把问题看成“总电耗分配问题”,而忽略真正致命的“局部电热耦合失稳问题”。这就是为什么今天很多机房即使总能效看起来不错,仍然会在高密度 AI 负载下表现出热节流、掉压、容量死区和业务中断等一系列“看不见的结构性损失”。
二、液冷很重要,但它只解决了热问题的一半
液冷必须上,这一点在今天已经没有争议。无论是冷板液冷、单相浸没,还是两相相变浸没,其底层逻辑都很直接:液体的热导率和比热容显著高于空气,因此能够以更低热阻、更高热通量,把热量从芯片与板级器件中更快地带走。在高热流密度时代,液冷已经从“增强型散热方案”变成“基础能力”。
但液冷的物理边界同样必须看清。液冷解决的是热移除,不是热生成。
输入服务器的电能,除了极少部分转化为信号输出外,几乎最终都会变成热。也就是说,只要计算架构、互连方式、供电方式和板级转换路径不变,液冷本质上是在更高效地搬运已经产生出来的热,而不是从源头减少热量本身。它不能自动降低芯片因多级电力转换、无效数据搬运、板级 VRM 损耗和高频负载波动所产生的绝对热量。更重要的是,液冷系统作为宏观流体系统,天然存在热惯性,它无法在微秒级时间尺度上干预芯片内部局部热点的形成,也无法阻止瞬态功率冲击通过板级供电网络传导成热点温升。
因此,液冷是一条必须建设的“高效热通道”,但绝不是根解。 它回答的是:“热怎么带走?” 却没有回答:“为什么会有这么多热,为什么热会在同一时间、同一位置突然爆发出来?”
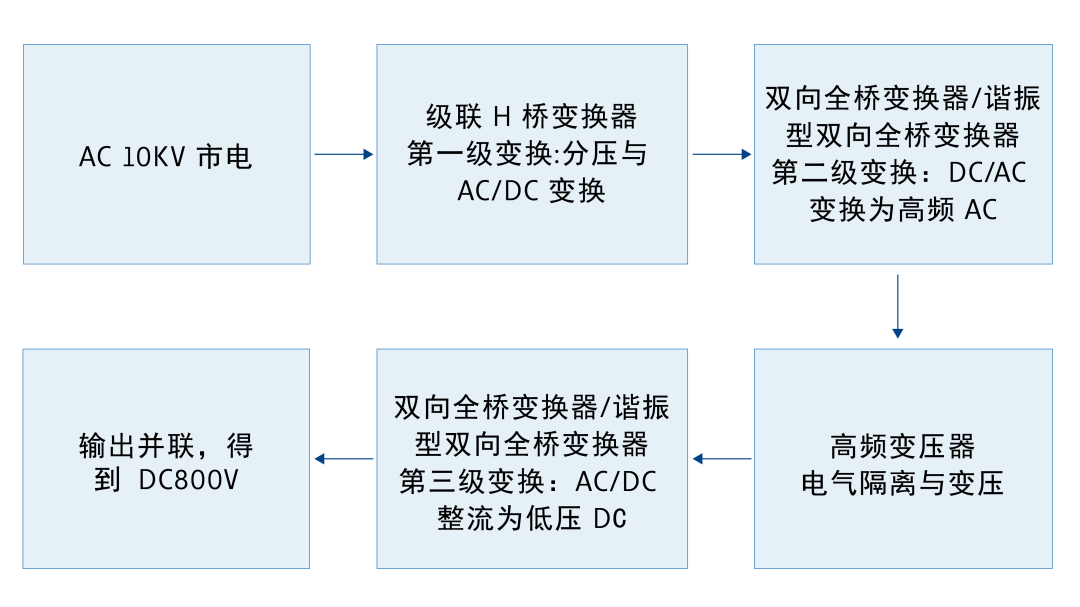
三、SST很先进,但它也只解决了稳态入口问题
与液冷类似,SST 和 800V HVDC 也是正确方向,而且是必须方向。施耐德提出的数据中心供电三步路线,本质上就是从传统 48V 低压直流 过渡到 800V 高压直流,再进一步走向“中压交流直接入局、SST一步变换、直流原生”的架构;台达则用集装箱式 SST 直流移动智算中心,把这种路线推向工程化落地,采用 800V直流供电架构,宣称全链路转换效率超过 98.5%,并支持 24小时内部署上线。
更重要的是,西电公开资料给出了可量化的对比:其数据中心供电方案中,SST 路径全链路效率可达 90.8%,高于 HVDC 的 88.9% 和 UPS 的 85.8%;在一个 10MW 数据中心场景下,相比传统 UPS 路径,SST 方案 10 年可节省 2811万kWh。这不是概念优势,而是真实、可计算、可折算为热源消减的工程价值。
但这并不意味着 SST 就是终局。
SST 解决的,是电力入口和稳态主干链路的问题。它通过提升电压等级、缩短 AC/DC 变换链路、减少铜耗和系统体积,把原本臃肿低效的主供电系统改造成更高效、更紧凑、更适合 AI 时代的能源入口。可真正最危险的电力问题,并不发生在 10kV 入口,也不发生在 800V 母线本身,而是发生在服务器内部最后几厘米、几毫米之内:PSU 下游、中间母线、VRM、去耦网络、HBM 与 GPU 供电边界。
AI 集群在 all-reduce、Cache Miss、同步唤醒和 Checkpoint 阶段产生的是微秒级高频瞬态负载;而 SST 的控制环路与大功率功率器件的物理响应,主要优化的是毫秒级到秒级的设施侧稳态供能。把单台 SST 直接暴露在这样高同步、高突变的算力负载之下,寄望它既做高效稳态路由器,又做高频脉冲灭火器,本身就是一种典型的“控制域幻象”。它很强,但它并不负责解决全部问题。
四、AIDC真正的第一性矛盾,是“时空错配”
如果液冷和SST都没有触及根部,那么问题到底出在哪里? 答案不是一个设备名词,而是一个系统性矛盾:算力负载与基础设施之间的时空错配。
所谓“时域错配”,是指AI算力负载已经进入微秒级到毫秒级的脉冲世界,而传统供电与制冷系统仍主要工作在毫秒级到分钟级甚至更慢的响应范式中。
所谓“空域错配”,是指机房层面看到的是机柜总功率,芯片层面承受的却是几毫米尺度上的极端局部热流密度和板级供电扰动。
这不是抽象概念,而是可以直接算出来的物理矛盾。 假设 20 个 120kW GPU 机柜在同步训练时产生一个仅 12% 的功率阶跃,那么瞬时附加冲击功率为:
ΔP = 20 × 120kW × 12% = 288kW
如果这个脉冲只持续 0.2 秒,则它背后的缓冲能量仅为:
E = ΔP × Δt = 288kW × 0.2s = 57.6kJ ≈ 16Wh
这组计算揭示了一个违背直觉却极其关键的真相:AIDC 真正缺乏的,往往不是总能量,而是谁能在极短时间内承接极高瞬时功率。
也正因为如此,今天很多数据中心设计本质上是在用一整套反应迟缓的“大设备”,去对抗一连串极快、极短、极局部的“小脉冲”。结果就是:系统前端被迫预留大量容量冗余,形成长期闲置的“容量死区”;一旦脉冲穿透,就会触发母线暂降、板级供电扰动、芯片热点抬升和热节流降频,最终表现为业务侧的训练中断与推理不稳定。
从这个角度看,AIDC 的危机根本不只是“热太大”,而是: 功率释放太同步、热点形成太局部、控制响应太滞后。
五、吞噬AIDC效率与利润的三大黑洞
在这种时空错配背景下,输入数据中心的电能并不会自然高效地转化为算力,中间至少有三个黑洞在吞噬它。
第一个黑洞,是 48V 低压配电的铜损深渊。 根据最基础的关系式 P = V × I,当机柜功率达到 600kW 时,若仍采用 48V 架构,则电流将达到:I = 600000 / 48 = 12500A
如果未来走向 1MW 机柜,48V 下电流则会达到:I = 1000000 / 48 ≈ 20833A
再看铜损公式:P_cu = I²R = (P² / V²) × R
在同等线路电阻下,48V 相对 800V 的铜损比值约为:(800 / 48)² ≈ 277.8
也就是说,同功率、同电阻条件下,48V 主干配电的焦耳热量级约为 800V 的 278倍。这已经不是“优化空间”问题,而是架构生死线问题。
第二个黑洞,是多级转换形成的等效连续热源。
西电公开资料给出的 10MW 数据中心对比中,SST 路径相对 UPS 路径 10 年节省 2811万kWh。把它折算成年均:2811万kWh / 10 = 281.1万kWh/年
再折算为等效连续功率:281.1万kWh / 8760h ≈ 321kW
这意味着,仅仅通过缩短供电链路、减少 AC/DC 和 DC/DC 冗余变换,一个 10MW 数据中心就能“凭空消灭”一个 321kW 的持续热源。链路损耗从来不只是电费问题,它首先是热源问题。
第三个黑洞,是数据搬运能损。
在传统冯·诺依曼体系下,大量系统能耗并不发生在矩阵计算本身,而发生在 GPU 与 HBM/DRAM、GPU 与 GPU、GPU 与网络之间的数据往返搬运。原文所指出的 62.7% 系统能耗并非真正用于逻辑运算,而是在互连、访存和搬运中变成了热,这一点必须被正视。只要这一黑洞不被解决,AIDC 就会持续在“算力看起来很强、热看起来永远不够散”的悖论中打转。

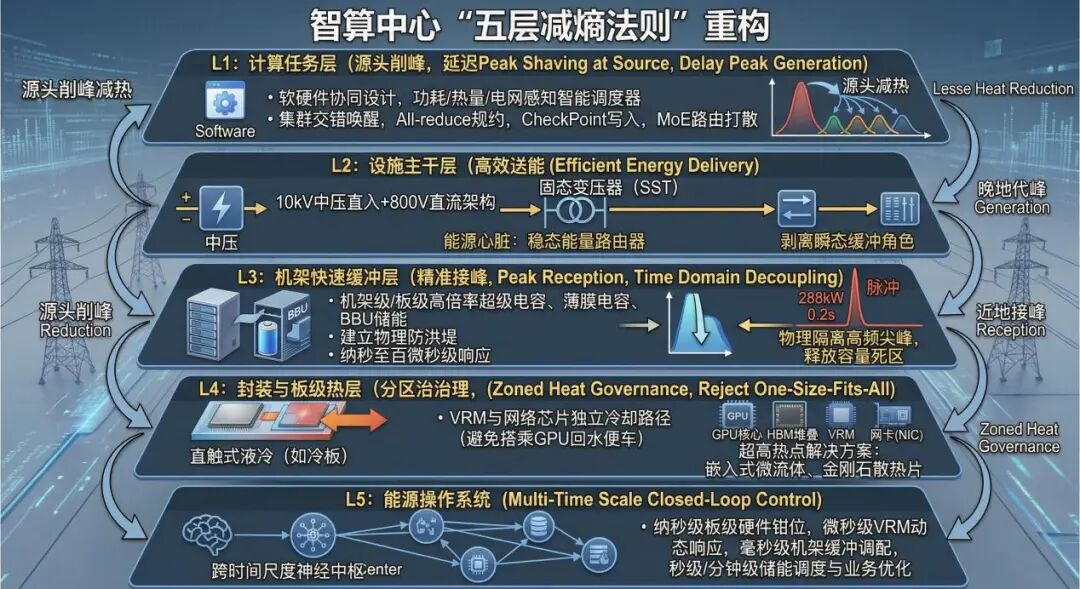
六、根解不是一个设备,而是“五层能源操作系统”
真正的答案,不是更大的冷却塔,也不是更强的单体 SST,更不是某个“神奇储能设备”。根解必须是一套跨层协同的架构,也就是本文提出的“五层能源操作系统”。
第一层,是算力任务层。
先削峰,再谈供电。调度器必须从单纯追求吞吐量和时延,升级为兼顾 功率、热量、电网约束的调度器。通过错开 all-reduce、同步唤醒、checkpoint 和 MoE 激活,把原本尖锐叠加的负载峰值打散为更平滑的功率曲线。只有源头削峰,后续系统才不会永远处于被动追热、被动追压的状态。
第二层,是设施主干层。
SST/HVDC 负责稳态高效送能。它的使命不是对抗全部瞬态,而是作为高效率能量路由器,把中压 AC 尽可能高效地变成 800V 直流,并把光伏、站级储能、BESS 在直流侧原生耦合。这一层的任务,是从根本上消除多级转换损耗和低压主干铜损。
第三层,是机架快速缓冲层。
这是真正的时域解耦层。既然单体 SST 无法在微秒级承接脉冲,就必须在更靠近物理负载的位置——机架侧甚至板级——配置超级电容、薄膜电容阵列或高倍率电池,构成混合缓冲层。它们不负责长时供能,而负责在 100μs–10ms 的尺度上,精准接住高频脉冲,把高峰值功率与主链路解耦。
第四层,是封装与板级热层。
热点必须分区治理,而不能再搞“一刀切液冷”。GPU 核心、HBM、VRM、NIC、光模块的热特性完全不同。真正先进的热管理,不是让所有热源共享同一条冷却路径,而是让热点在哪里、最低热阻路径就到哪里。未来更深度的解法,必然是直触式冷板之外,继续向微流道、嵌入式微流体、封装级冷却推进。
第五层,是多时间尺度控制层。
AIDC 不能只靠一个慢速 BMS 或 DCIM。它必须建立跨时间尺度的闭环控制:
① 纳秒级板级钳位与去耦;
② 微秒级 VRM 动态响应;
③ 毫秒级机架缓冲与整流控制;
④ 秒级到分钟级站级储能与热管理调度;
⑤ 再向上连接业务层的负载编排。
只有这五层全部打通,数据中心才真正从“被动用电者”升级为“主动编排电力与热流的算力能源系统”。
七、AIDC的终局,不是更会搬运热,而是更少产生无效热
当五层能源操作系统逐步落地,一个更深的问题也会浮出水面:未来真正先进的 AIDC,不会只比谁更会散热,而会比谁更少产生无效热。
这就意味着,AIDC 的终局演进不止于机房工程,还会进一步走向更低熵的计算范式,包括:
·逻辑可逆计算,尽可能逼近信息处理中的热耗极限;
·光电融合计算,以光子替代电子完成部分运算和互连,显著降低欧姆热;
·存算一体架构,在存储中完成计算,直接削弱“存储墙”和搬运热。
也就是说,未来真正的竞争,不是“谁的液冷更猛”,也不是“谁的 SST 更大”,而是: 谁能让输入系统的每一焦耳电能,尽可能少浪费在铜损、转换损耗、搬运热和瞬态失配上,尽可能多地变成有效算力。
结语
所以,AIDC 的问题绝不是一句“散热难”可以概括的。 它真正的危机,是算力负载释放功率与热量的方式,已经进入高同步、高脉冲、高局部热通量时代;而基础设施仍在用上一代平均功率思维去设计。
液冷必须上,因为没有它,高热流密度设备跑不起来; SST/HVDC 也必须上,因为没有它,低压主干配电在高功率密度时代已经失去物理可行性。 但真正的终局,不是液冷本身,也不是 SST 本身。
真正的终局,是建立一套贯穿 任务削峰、稳态送能、快速缓冲、热点治理、多尺度控制 的五层能源操作系统,让每一度电更少地变成废热,更高比例地变成可交付算力。
当这一步真正实现,PUE 就不再是信仰,而只是结果;AIDC 也才真正从“装满GPU的机房”,进化为“可编排的智能能量场”。












评论区
登录后即可参与讨论
立即登录