近日,摩尔线程依托旗舰级AI训推一体智算卡MTT S5000与自研MUSA软件栈,基于SGLang 开源推理框架,成功完成DeepSeek-V4的完整运行验证。该成果表明,面向新一代MoE大模型,摩尔线程已构建起从硬件架构核心计算引擎承接、热点算子支持**,**再到端到端部署验证的系统化适配链路,验证了国产GPU平台对前沿大模型“框架级兼容、开箱即落地”的承载实力及工程化落地能力。
随着大模型架构
4月24日,DeepSeek-V4预览版正式发布。DeepSeek自V3起便以高频迭代著称,V4的到来只是节奏延续。
但真正引发行业震动的是:华为昇腾、寒武纪、海光信息、摩尔线程、沐曦股份、百度昆仑芯、阿里平头哥、天数智芯等八家国产AI芯片厂商,在模型发布的同一天,集体完成了全链路适配与性能优化。
(图源:DeepSeek)
Day 0 意味着什么?
Day 0适配,是指在大模型正式发布当天,算
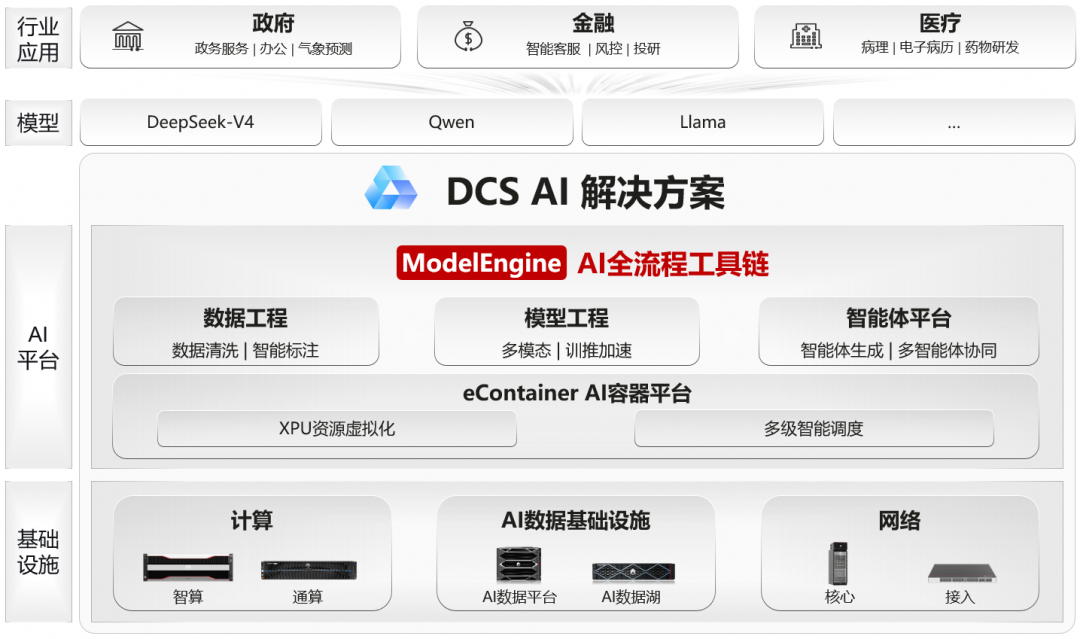
4月24日,DeepSeek-V4预览版正式推出并开源,将模型上下文窗口提升至1M,并引入KV Cache滑窗与压缩算法,有效缓解Attention计算复杂度与访存带宽压力,智能体能力大幅提高,在长序列推理与复杂任务处理中的表现更加高效与稳定,但新模型对基础设施也提出了新的挑战。华为DCS AI解决方案集成华为AI软硬件产品,发挥全栈优势,针对DeepSeek-V4进行深度适配,完成系统级优化和易
4月24日,摩尔线程联合北京智源人工智能研究院,基于旗舰级AI训推一体智算卡MTT S5000与FlagOS全栈软件体系,**完成DeepSeek-V4系列两款模型推理“Day-0”适配,并在魔搭社区正式发布Pro和Flash两个版本的镜像**,为开发者与行业用户带来开箱即用的国产化部署方案。
▼ DeepSeek-V4-Pro镜像地址:
https://modelscope.cn/models/

今日,DeepSeek-V4正式开源发布,将模型上下文窗口提升至1M,使模型在长序列推理与复杂任务链处理中的表现更加高效与稳定。华为AI数据平台深度适配DeepSeek-V4,将进一步推动大模型从实验阶段走向生产级应用。
DeepSeek-V4发布
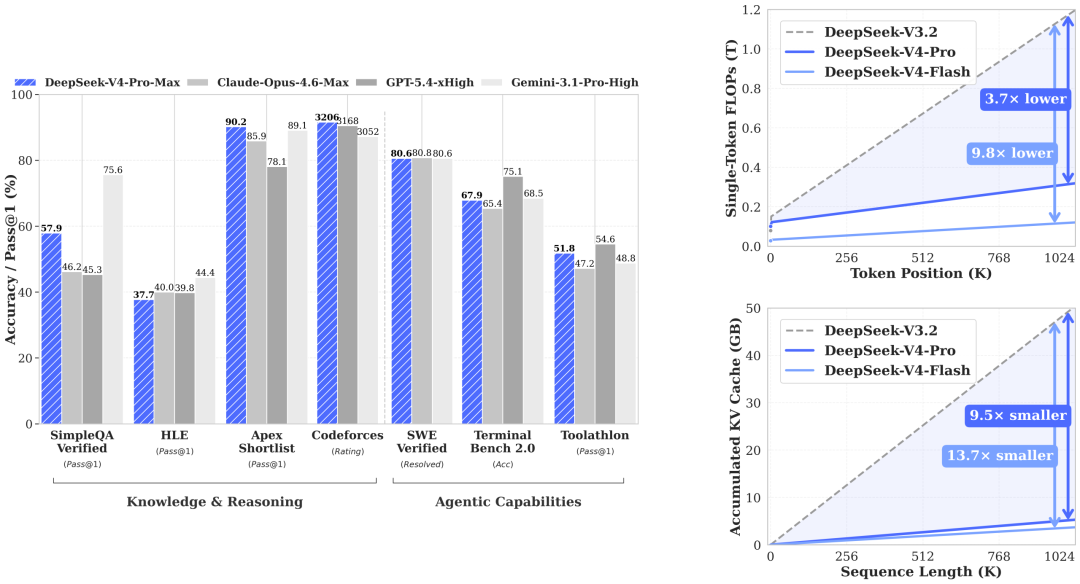
带来KV Cache存储的全新挑战
DeepSeek-V4新版本支持100万Tokens的上下文能力。为提升上下文理解能力同时控制显存占用,DeepS
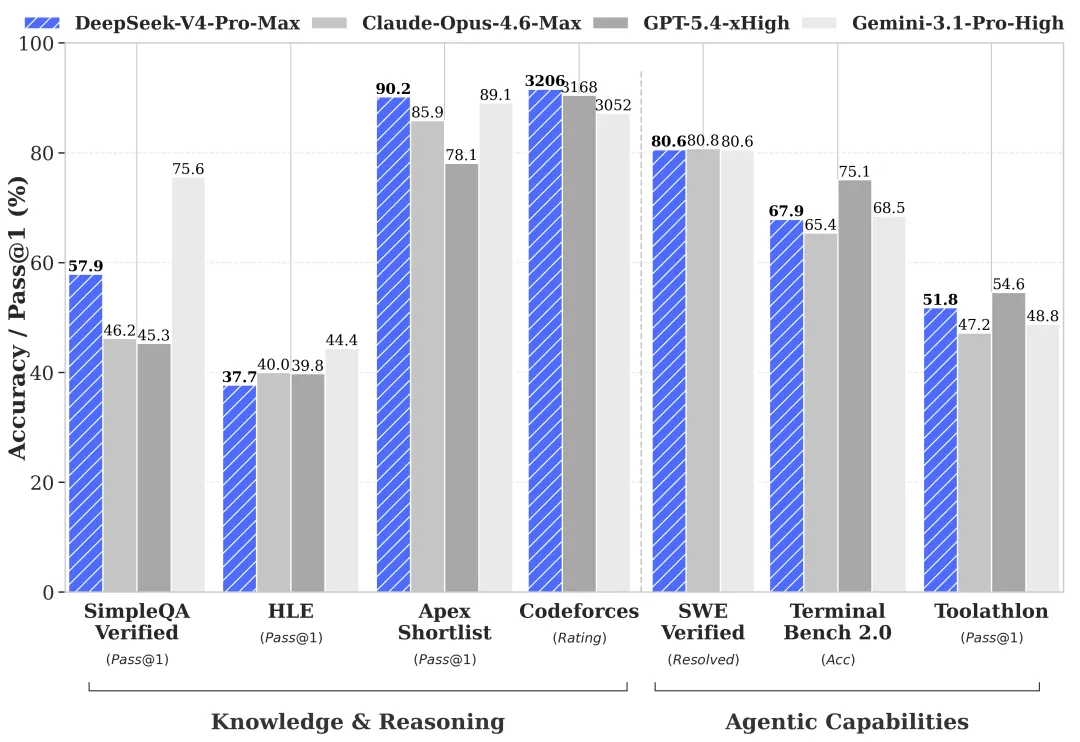
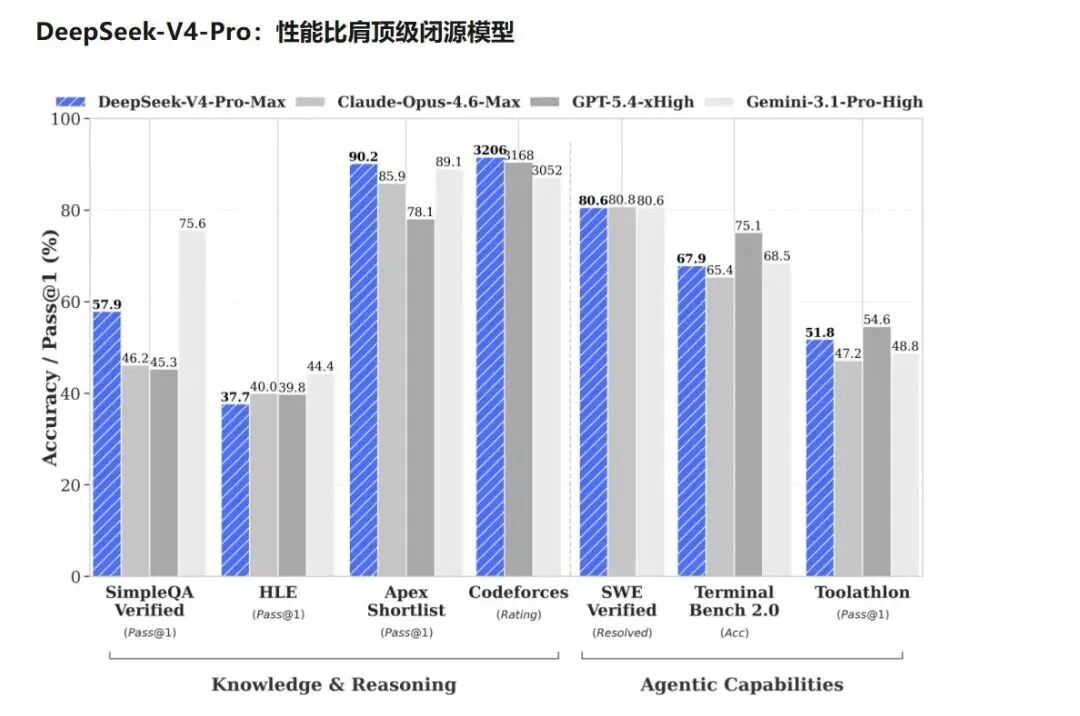
4月24日,中国人工智能公司DeepSeek正式发布并开源全新系列模型DeepSeek-V4预览版。
该系列包含Pro与Flash两个版本,均支持百万字(1M)超长上下文。官方表示,V4在Agent能力、世界知识和推理性能三大维度上达到国内与开源领域领先水平,其中Pro版本性能可比肩世界顶级闭源模型。
双版本矩阵:旗舰对标顶尖,Flash普惠经济
DeepSeek-V4采用MoE(混合专家)架构
4月24日,摩尔线程携手智源众智FlagOS社区,在旗舰级AI训推一体全功能GPU MTT S5000上,率先实现对新一代大模型DeepSeek-V4-Flash的Day-0极速适配,并完成了全量核心算子的深度优化与部署支持。
DeepSeek-V4-Flash 采用混合专家(MoE)架构,总参数量高达284B,激活参数13B,支持百万token上下文长度。其预训练数据超32Ttoken,在最大
4月24日,摩尔线程宣布,其基于TileLang 0.1.8版本深度优化并已成为TileLang官方主线版本的TileLang-MUSA,已率先在国产全功能GPU上,实现对DeepSeek-V4最新TileLang算子库TileKernels的“Day-0”支持,为大模型关键算子的快速迁移、验证与性能优化奠定了可直接复用的工程基础。
▼ TileKernels算子库开源地址:
https://gi
今日,DeepSeek-V4预览版正式发布并开源。摩尔线程携手上海 AI 实验室 DeepLink 团队,通过大模型驱动的智能算子迁移系统 KernelSwift,率先在旗舰级AI训推一体智算卡 MTT S5000 上完成了核心算子的Day-0适配。目前算子通过率已超80%,真正实现了模型发布与国产算力适配的同步落地。这一成果不仅为开发者提供了无缝部署体验,更彰显了 KernelSwift 与 M
4月24日,DeepSeek-V4模型正式发布并开源,华为云首发适配。DeepSeek-V4拥有百万Token超长上下文,在Agent能力、世界知识和推理性能上均实现国内与开源领域的领先。其中,DeepSeek-V4-Flash模型参数下降至284B,推理成本进一步降低,模型参数和激活更小,V4-Flash能够提供更加快捷、经济的API服务,实现百万上下文普惠。当前,华为云MaaS模型即服务平台已