内存墙之痛:为什么AI加速不能只靠堆计算单元?
本文介绍了为什么AI加速不能只靠堆计算单元。 很多人一说起AI加速,第一反应就是堆算力、堆更多浮点计算单元。 错了, 现在的瓶颈根本不是计算本身,是数据搬运、通信和不规则算子,峰值算力再高也没用。 举个最直观的例子,大语言模型推理的时候,每个新生成的token都要读写一遍已经存起来的KV缓存,这玩意儿根本不怎么缺计算,缺的是内存带宽——你带宽不够,就算计算单元堆得再多,也得等着数据慢悠悠从内存运
关于「内存墙」的技术文章、设计资料与工程师讨论,持续更新。

本文介绍了为什么AI加速不能只靠堆计算单元。 很多人一说起AI加速,第一反应就是堆算力、堆更多浮点计算单元。 错了, 现在的瓶颈根本不是计算本身,是数据搬运、通信和不规则算子,峰值算力再高也没用。 举个最直观的例子,大语言模型推理的时候,每个新生成的token都要读写一遍已经存起来的KV缓存,这玩意儿根本不怎么缺计算,缺的是内存带宽——你带宽不够,就算计算单元堆得再多,也得等着数据慢悠悠从内存运
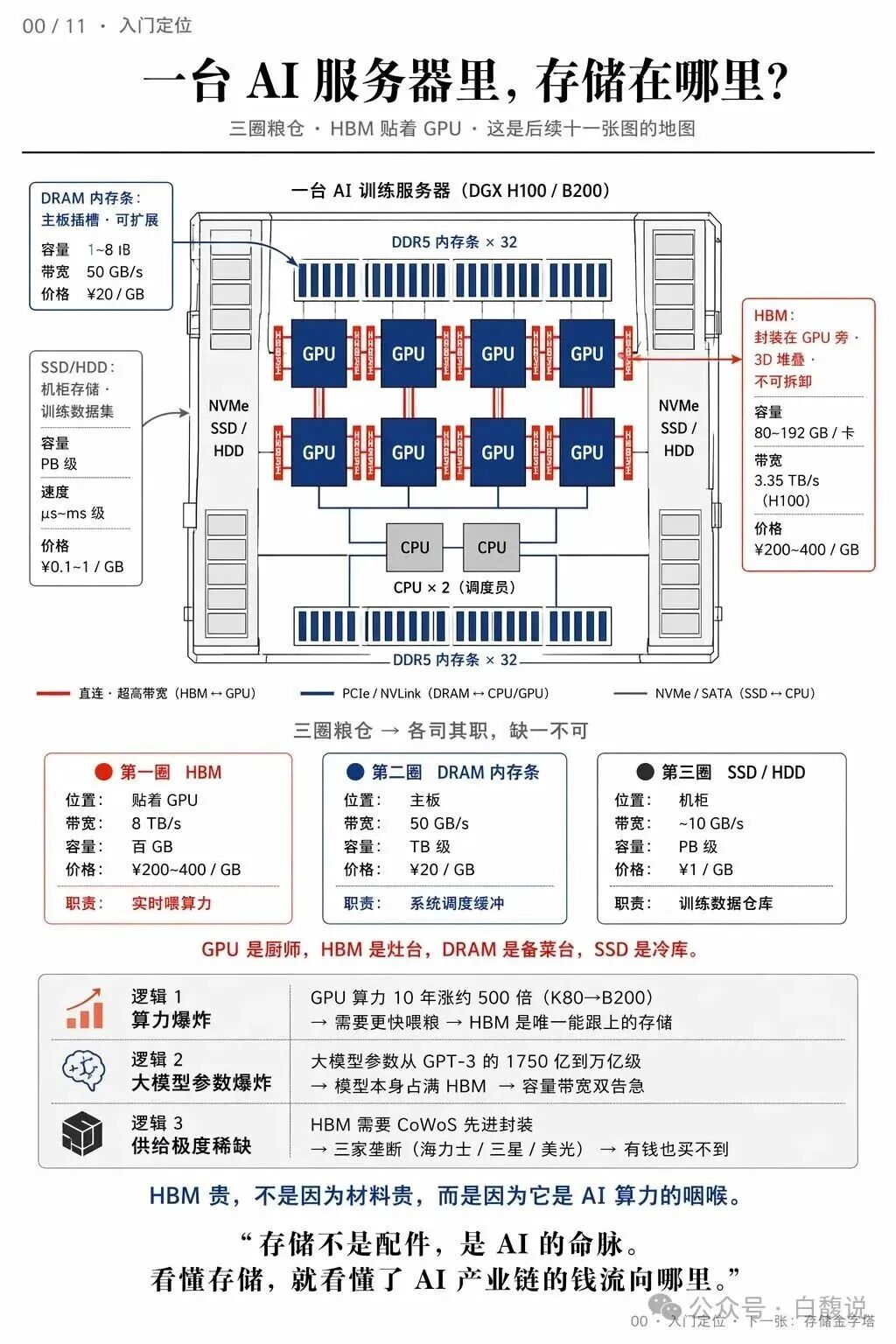
AI服务器的存储并非单一设备,而是分为“三圈粮仓”:HBM紧贴GPU,负责实时喂算力;DRAM内存条位于主板,承担系统调度缓冲;SSD/HDD在机柜中,存放PB级训练数据。三者的带宽、容量、价格差异巨大——HBM带宽可达TB/s级,但容量仅百GB;SSD容量大但速度慢。GPU算力十年涨500倍,HBM是唯一能跟上的存储,成为AI算力的“咽喉”。 从寄存器到硬盘,存储呈现“速度越快、容量越小、价
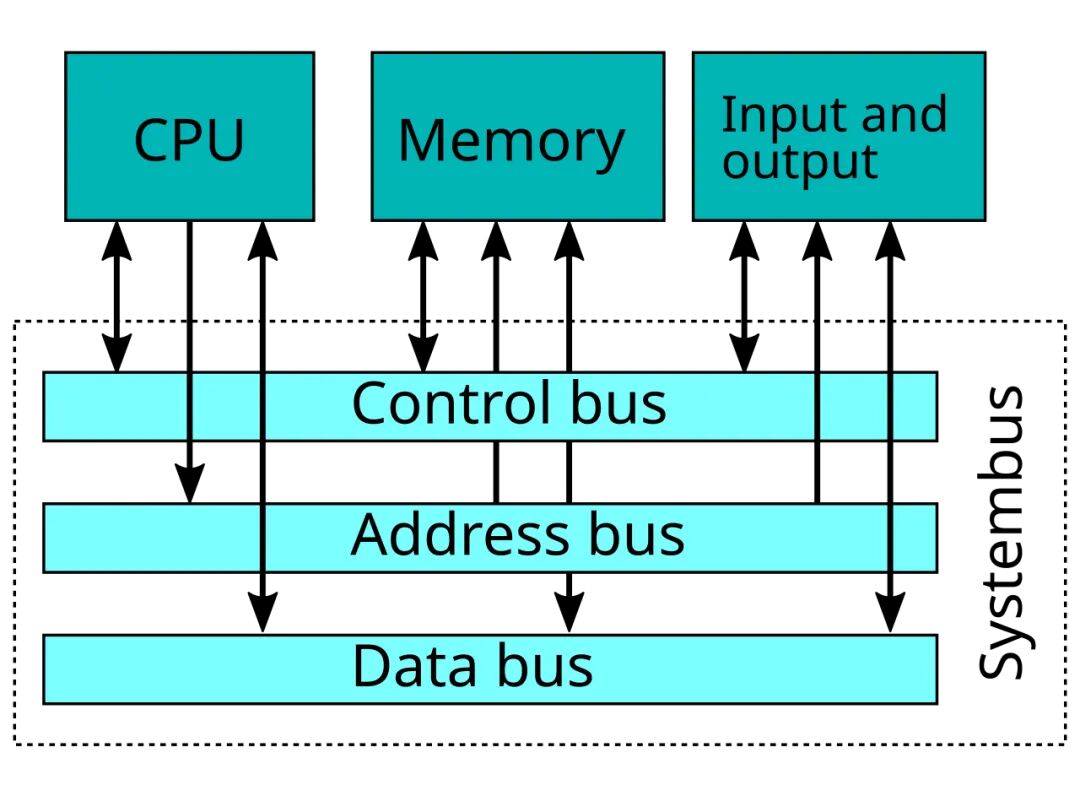
“内存墙”一词最早出现于20世纪90年代中期,当时弗吉尼亚大学的研究人员William Wulf和Sally McKee合著了“Hitting the Memory Wall: Implications of the Obvious”(撞上内存墙:显而易见的影响)一文。该研究揭示了由于处理器速度与动态随机存取存储器(DRAM)性能之间的差距而导致的内存带宽瓶颈问题。 这些发现指出了工程师们在过

当AI加速器陷入“算力过剩、数据饥渴”的怪圈,决定性能上限的早已不是计算核心的数量,而是内存带宽与互联架构。本文带你跳出“堆算力”的误区,重新审视AI硬件的真正战场。 现在跑大模型,大家都在喊算力不够,要堆更多核心。 但现在AI加速器的性能瓶颈,早就不是计算单元本身,而是内存和互联架构。 AI加速器到底是怎么进化到今天的 AI硬件的发展路线其实非常清晰,就是从通用到专用一步步走过来的。 最早大家都

| 端侧AI元年:千亿赛道的机遇与挑战 2025年被业界公认为“端侧AI元年”,随着AI手机、人形机器人、可穿戴设备等终端产品的爆发式增长,端侧大模型正从技术概念走向规模化应用,催生了对低功耗、高性能端侧AI芯片的海量需求。据测算,全球端侧AI市场将从2025年的3219亿元增长至2029年的1.2万亿元,复合年增长率高达39.6%,千亿赛道已然浮出水面。但繁荣背后,端侧大模型的落地始终被三大核心