
从5亿条互联网视频中炼出全球最大的开源 GUI 操作数据集,让7B 模型在 ScreenSpot-Pro 上准确率提升38%;3B 参数的小模型做时序推理,干掉专用大模型还省了71%的 Token。这不是 PPT 愿景,而是小米 AI 团队研究成果的真实体现。
近日,ICML 2026(International Conference on Machine Learning)公布了论文录用结果。小米及合作单位共有11篇最新研究成果入选。入选论文不是孤立的学术发表,而是一套完整的 AI 能力进化拼图。底座层有 MoE 训练稳定性(R3)和神经架构自动搜索(SPARK);能力层有推理增强(LED、VeriTime)和多模态理解(Visual Para-Thinker、Video-OPD、MECAT);应用层有 GUI Agent 全栈,从数据(Video2GUI)到评测(GUIEvalKit)到推理架构(CoME),再到视觉内容生成(GAD)。从训练到部署,各技术环节均有论文背书,体现了小米在 AI 技术研发上的长期投入与落地能力。
ICML 是全球机器学习领域历史最悠久、影响力最大的顶级国际会议之一,与 NeurIPS、ICLR 并称机器学习三大顶会。会议由国际机器学习学会(IMLS)主办,聚焦机器学习理论、算法及跨领域应用的前沿突破,汇聚全球顶尖学者与工业界专家,长期引领行业技术演进方向。ICML 2026为第43届,将于2026年7月6日至11日在韩国首尔 COEX 会展中心举办。
01
GUI Agent,从“能演示”到“真能用”
从 OpenAI 的 Operator 到 Google 的 Project Mariner,从 Manus 到各家“AI 帮你操作手机”的 demo,都成为行业重点关注方向。值得关注的是,现阶段 demo 与日常可用上存在一定差距。我们近期发布的论文,覆盖“数据-评测-推理”全链路,旨在推动 GUI Agent 从实验室搬向真实场景。
**▍**Video2GUI: Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining****
合作者单位:北京大学
论文作者:熊伟民,谷舒豪,叶博文,岳子豪,李磊,宋非凡,李素建,田昊
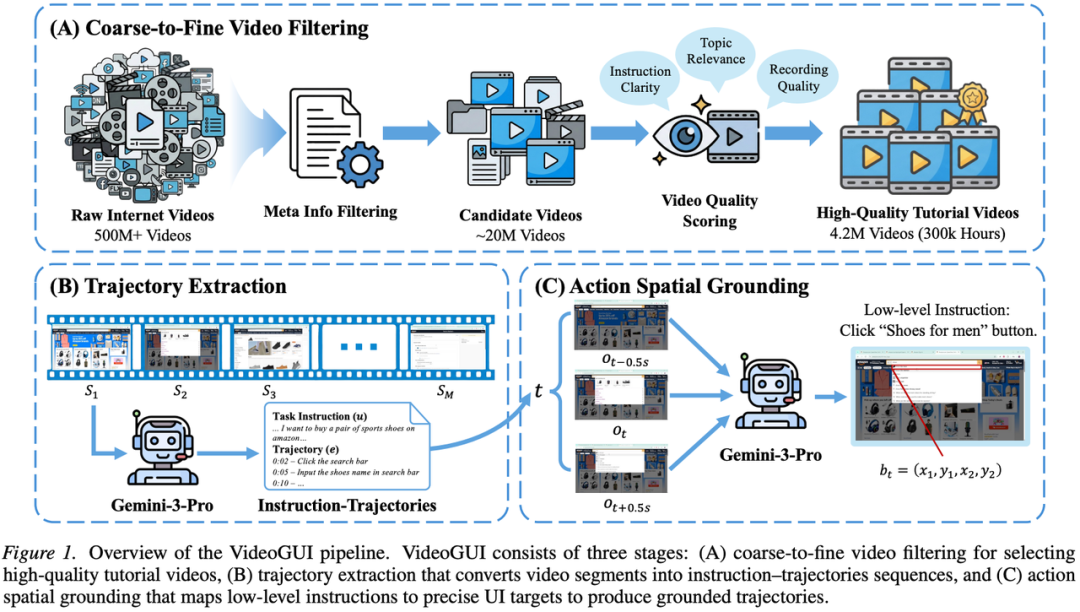
训练 GUI Agent,最大的瓶颈不是模型架构,而是数据。人工标注成本高昂且局限于单一平台,仿真环境覆盖有限。互联网上5亿条教程视频里明明藏着海量操作示范,但如何从“看视频”变成“可训练的结构化轨迹”?
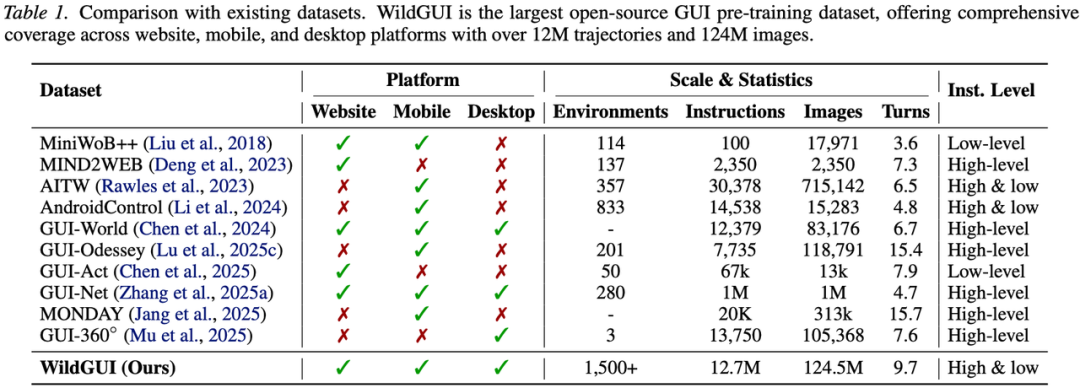
Video2GUI 构建了“元信息粗筛+视频内容细筛”两阶段流水线,从5亿条视频中筛选出420万条高质量教程,再用 Gemini-3-Pro 将视频转为带任务指令、动作时间戳和屏幕坐标的结构化轨迹。最终产出 WildGUI,目前规模最大的开源 GUI 预训练数据集,包含1270万条轨迹、1.245亿张截图,覆盖1500余个应用与网站、五大平台。
效果说话:利用 WildGUI 预训练后,MiMo-VL-7B 在 OSWorld-G 上取得67.6分,超越 Qwen3-VL-32B 与 Seed1.5-VL;在 ScreenSpot-Pro 上准确率从41.2提升到56.9,提高近38%。Scaling Experiments 表明,性能随预训练 token 数增加持续提升,扩展至200B Token 时仍未出现饱和迹象。
Video2GUI 的核心价值,在于提供了一套可大规模 scale up 的数据生产配方:从互联网海量视频中自动提炼 GUI 操作知识,无需人工标注、不受平台限制,数据规模的天花板理论上等于互联网上所有 GUI 教学内容的总和。这套 pipeline,是通用 GUI Agent 迈向真正规模化的一块重要基石,也是一条充满想象空间的路径。
▍Scaling, Benchmarking, and Reasoning of Vision-Language Agents for Mobile GUI Navigation
***表示共同第一作者**
论文作者:屈恒*,刘怡珂*,金任任,张问宗,高鹏至,刘伟,栾剑
项目链接:https://github.com/xiaomi-research/guievalkit
GUI Agent 到底行不行?之前的评测存在三大盲区:训练数据规模有限且以英文为主,缺乏中文移动应用覆盖;评测工具碎片化,模型之间缺乏统一比较标准;数据规模、训练范式与推理能力对 Agent 表现的影响尚未被系统研究。
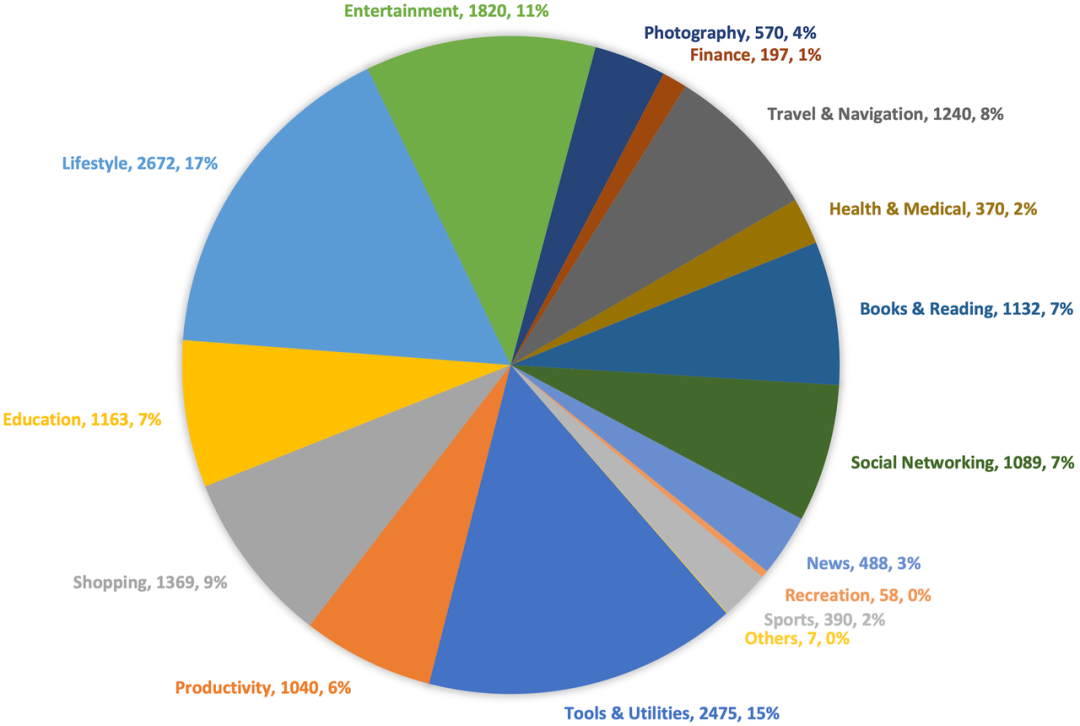
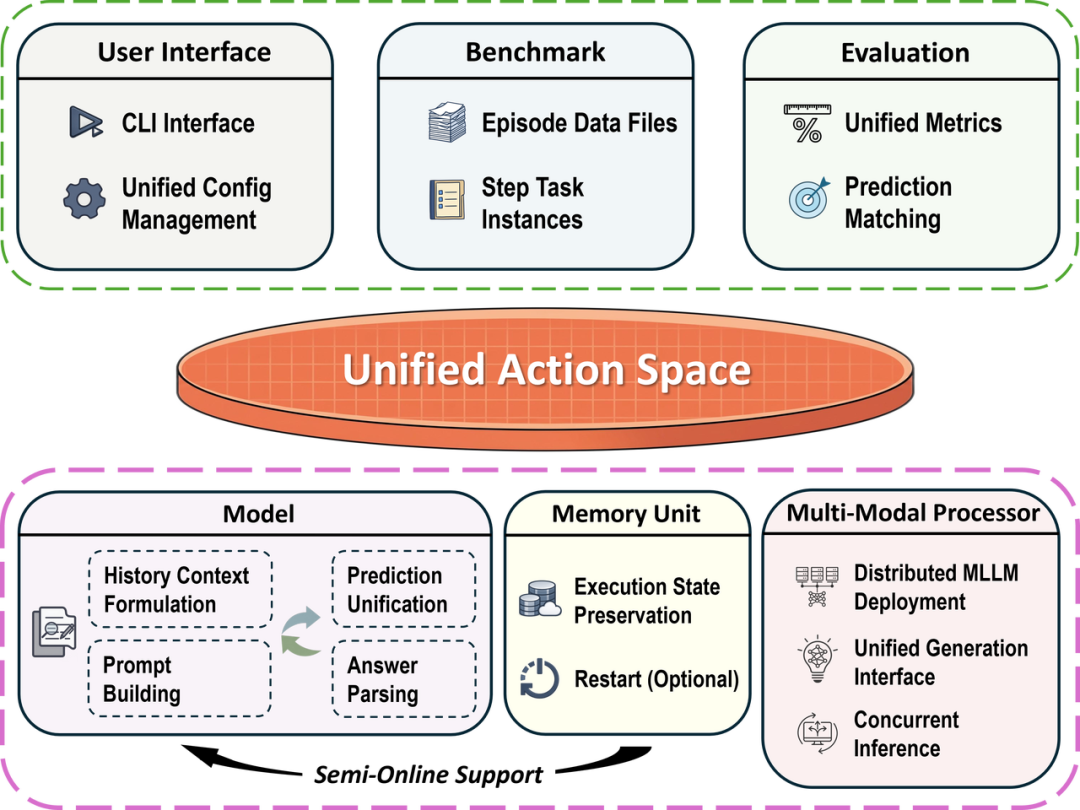
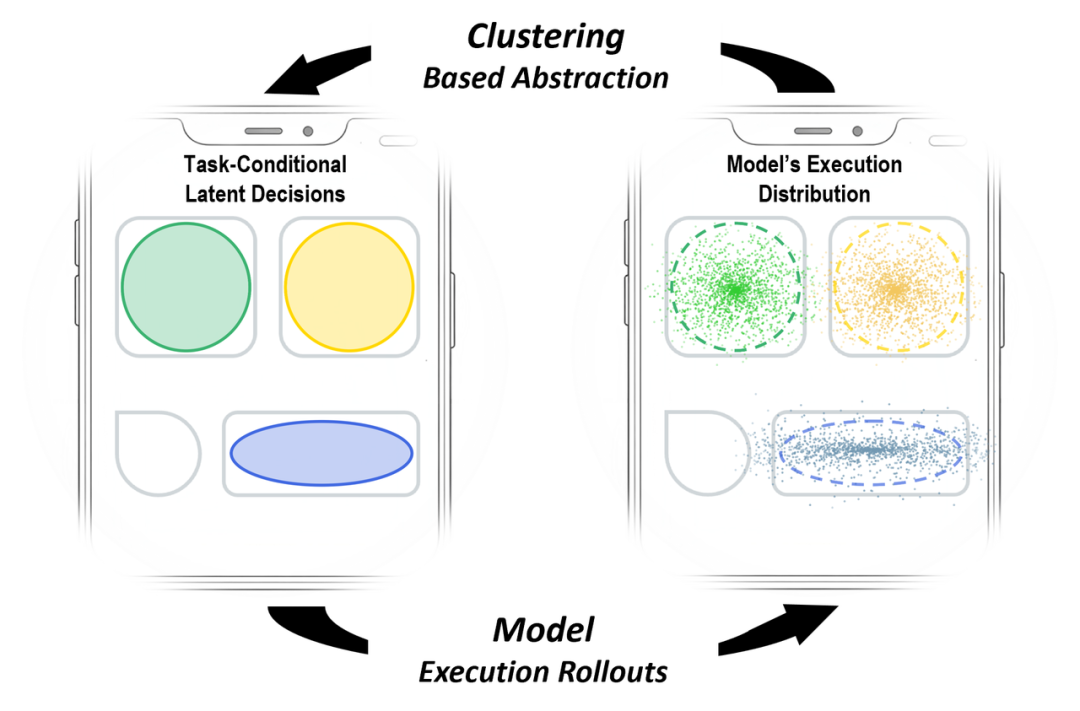
本文从数据规模化(Scaling)、统一评测(Benchmarking)和推理分析(Reasoning)三个维度展开系统研究。数据层构建了 HyperTrack,目前规模最大的中文移动 GUI 导航数据集,超过16000条真实任务轨迹,覆盖674款中文 Android 应用的17个类别。评测层开源了 GUIEvalKit 统一评测工具包,集成五大主流基准,支持超过30个模型的统一离线评测与半在线评测。分析层提出决策级评估框架,首次将 GUI Agent 的评估从“执行正确率”提升到“行为分布模式”。
核心发现:模型性能随训练数据量对数近似线性增长,且基于 GRPO 的强化学习微调在相同数据规模下始终优于监督微调。更关键的是,推理模式扩展了可行决策空间但降低了稳定性,这为小米手机 Agent 的工程优化提供了精准的调参方向。
HyperTrack Statistics
GUIEvalKit Framework
Decision-Level Evaluation
▍CoME: Empowering Channel-of-Mobile-Experts with Informative Hybrid-Capabilities Reasoning
合作者单位:中国人民大学、武汉大学、南洋理工大学、香港中文大学
论文作者:刘宇轩,徐伟恺,黄琨,陈畅与,赵健坤,高鹏至,刘伟,栾剑,商烁,杜博,文继荣,严睿
论文链接:https://arxiv.org/abs/2602.24142
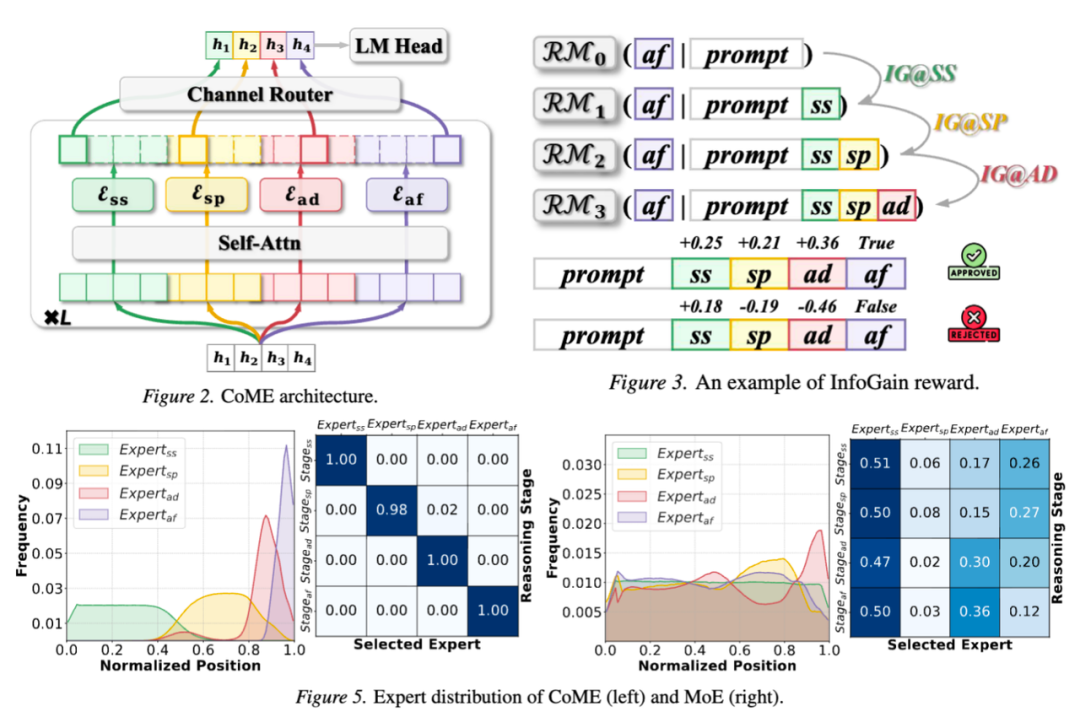
让 AI 操作手机,模型需要同时具备“看懂屏幕、规划任务、决定动作、调用函数”四种能力。传统 MoE 用面向输入的专家激活,无法精确匹配推理不同阶段所需的能力,导致专家激活与真实推理过程存在错配。
CoME(Channel-of-Mobile-Experts)提出面向 GUI Agent 的多专家推理架构,将推理过程显式划分为屏幕总结、子任务规划、动作决策和函数调用四个阶段,并为每个阶段配置专门专家。通过面向输出的专家激活,使模型在生成不同阶段输出 Token 时激活对应能力的专家。针对多阶段推理中的错误传播问题,引入信息增益来衡量每个中间推理步骤对最终动作预测的贡献,自动筛选更有效的推理轨迹。
实验表明,CoME 在使用更少的激活参数和训练数据的条件下优于 Dense GUI Agents 与 Sparse MoE Models。这验证了“能力解耦+阶段对齐”是 GUI Agent 推理效率提升的关键路径。对小米而言,这意味着端侧 Agent 可以用更小的模型、更少的算力,实现更稳定的多步操作。
02
让大模型“更会想”,推理能力增强
DeepSeek-R1、OpenAI o 系列掀起了“推理模型”热潮。但当前推理模型存在一个隐秘问题:强化学习训练后,模型虽然会“深度思考”,却丧失了“探索多条路径”的能力。以下论文,分别从“恢复推理时的探索多样性”与“专攻时序数据推理”两个方向展开,推动推理模型走向实用。
▍Restoring Exploration after Post-Training: Latent Exploration Decoding for Large Reasoning Models
合作者单位:中国人民大学、Unimore
论文作者:谭文辉,Fiorenzo Parascandolo,Enver Sangineto,鞠建忠,罗振波,曹乾,Rita Cucchiara,宋睿华,栾剑
论文链接:https://arxiv.org/abs/2602.01698
项目链接:https://github.com/AlbertTan404/LED
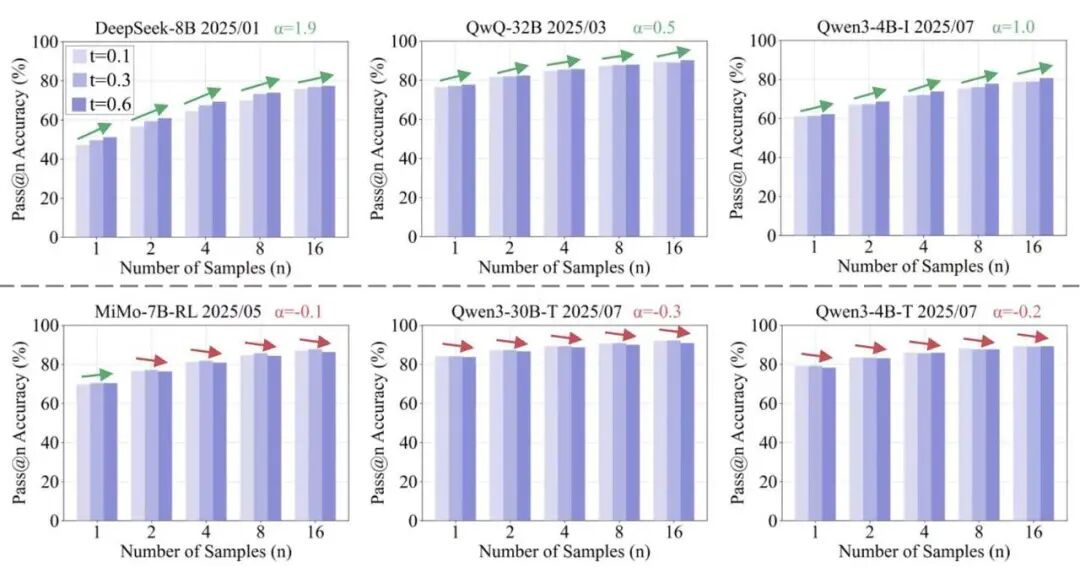
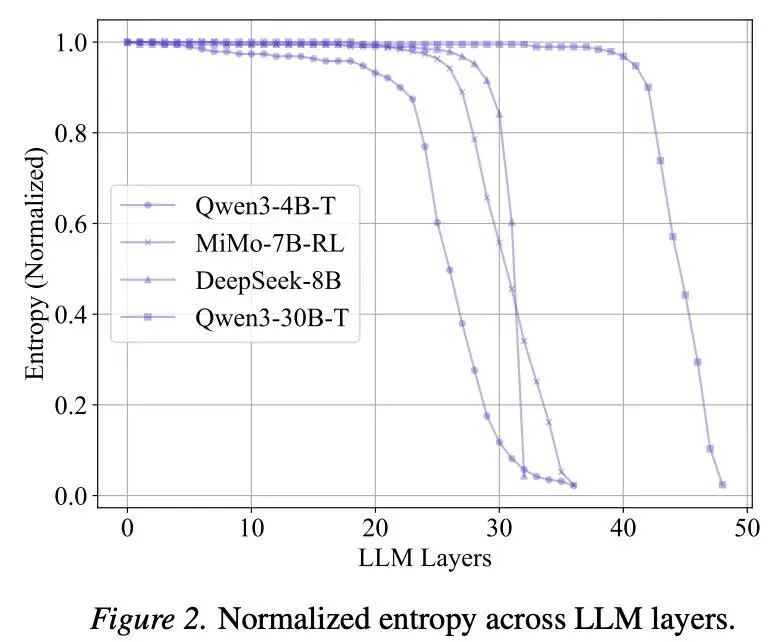
你有没有发现,给 DeepSeek-R1 提高采样温度,pass@k 反而不涨了?这不是个例。几乎所有 RL 训练后的推理模型都出现了 entropy collapse:输出层已经“塌缩”,提高温度只制造噪声,无法产生真正有意义的多样性路径。
但好消息是,模型内部的 hidden states 依然保留了丰富的 uncertainty。LED(Latent-Exploration-Decoding)正是基于这一发现:不改模型、不加参数、不需训练,仅在解码时利用模型内部多层隐状态的聚合概率分布进行采样,就能恢复推理模型的测试时探索能力。
在五个模型、六个测试基准上验证了 LED 的有效性。更强的测试时探索能力不仅提升了 pass@k,也同样带来了更优的 RL 训练效果。
通俗地说,RL 训练后的推理模型就像一个考试只会用“标准解法”的学生,答对率高但遇到新题就卡住。LED 让它重新学会“试试别的思路”,而且不需要重新训练。对小米 AI 助手而言,这意味着面对用户的开放性问题时,模型能探索更多解题路径,而不是只会一种固定套路。

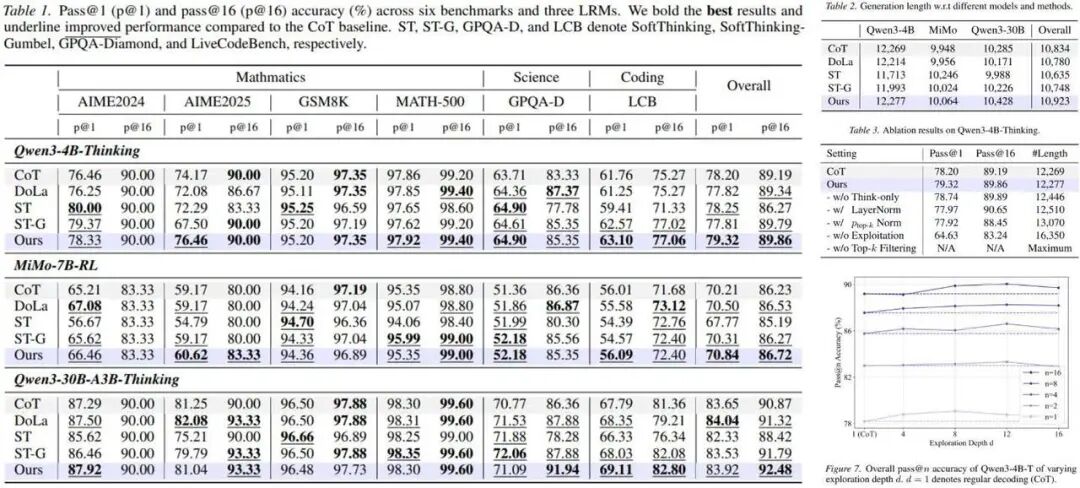
▍Time Series Reasoning via Process-Verifiable Thinking Data Synthesis and Scheduling for Tailored LLM Reasoning
合作者单位:中山大学,新加坡国立大学
论文作者:周加慧,李丹,李铂鑫,张霄,孟二利,李林,陈卓敏,娄坚,See-Kiong Ng
论文链接:https://arxiv.org/pdf/2602.07830
项目链接:https://anonymous.4open.science/r/VeriTime-E017
时间序列数据无处不在:物联网设备、新能源汽车电池监控、智能家居传感器、工业能源管理。让大模型真正具备时序推理能力,是端侧 AI 从“聊天助手”进化为“智能管家”的关键。但问题是:缺乏精心构建的时序 CoT 训练数据,且没有专门针对时序数据的强化学习算法。
VeriTime 从数据合成、数据调度、强化学习训练三个维度出发。构建了自动化数据合成流水线 TSRgen,生成首个带有过程可验证标注的时序-文本多模态推理数据集 TSRBench;设计了数据调度机制,根据难度和任务分类安排训练样本;开发了两阶段强化微调方法,通过细粒度、多目标的过程级奖励监督中间推理步骤。
结果:推理 Token 消耗平均降低71%,使 3B-4B 模型的推理能力达到甚至超越更大规模专有 LLM 的水平。
对小米智能家居和车载系统而言,这意味着一个小模型就能在端侧完成“判断电池是否异常”“预测空调何时该开”“分析驾驶模式变化”等时序推理任务,无需调用云端大模型,推理更快速。
03
多模态理解,让 AI 真正“看懂”图片、视频和声音
大模型不只需要会读文字。看懂图片细节、定位视频中的关键片段、理解复杂音频场景,这些能力决定了 AI 产品的体验。我们近期发布的论文,覆盖了视觉推理、视频时序定位、图像生成和音频理解。
▍Visual Para-Thinker: Divide-and-Conquer Reasoning for Visual Comprehension
合作者单位:浙江大学,湖南大学
论文作者:许浩然,王鸿裕,李佳泽,陈顺鹏,童子钊,鞠建忠,罗振波,栾剑
论文链接:https://arxiv.org/pdf/2602.13310v1
现有推理模型靠“想得更深更长”来提升能力(如思维链、强化学习)。但垂直扩展在视觉领域容易陷入固定思维模式。并行思维(Parallel Thinking)能够缓解探索范围的收窄,但将这一范式扩展到视觉领域仍然是一个开放的研究问题。
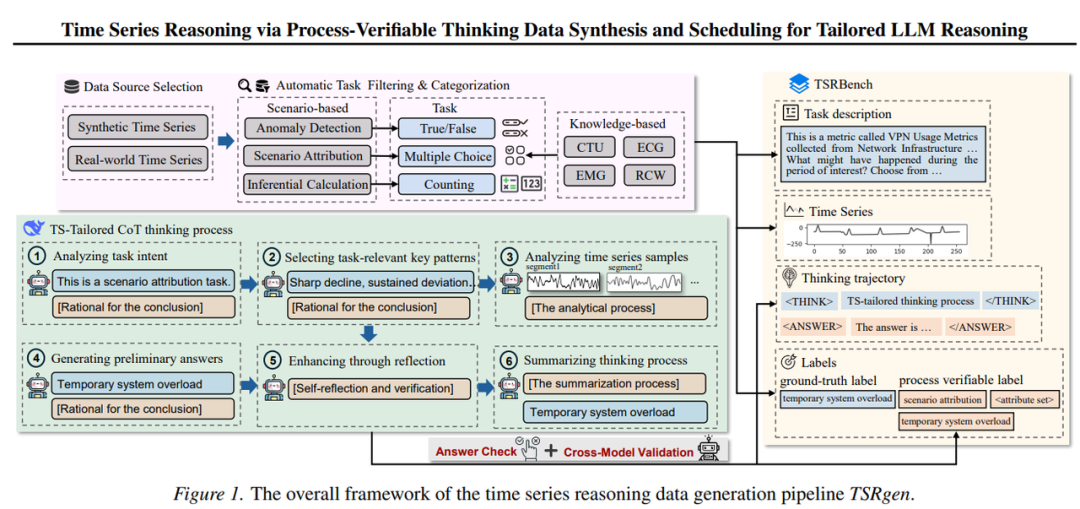
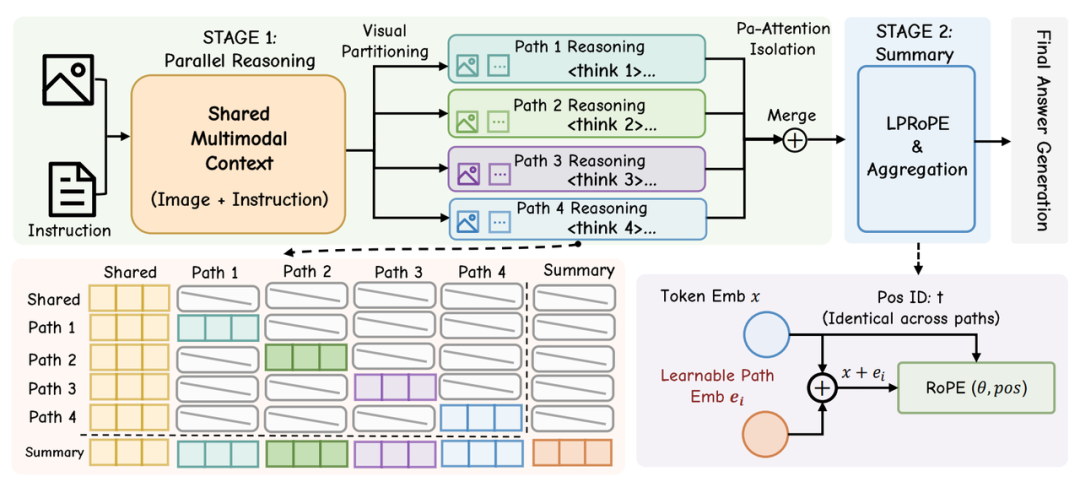
Visual Para-Thinker 是首个面向大型多模态模型的并行推理框架。核心在于研究视觉分区在并行化推理中的作用,并基于此提出两种不同的策略:基于块的分区和基于扫描顺序的分区。为了确保并行推理路径的独立性,提出了路径感知注意力机制和可学习并行旋转位置编码。
在 V*、CountBench、RefCOCO 系列和 HallusionBench 等多个基准上,方法在3B 和7B 模型规模上均持续超越原始模型、顺序推理以及多数投票等基线方法。
通俗地说,以前 AI 看图是”盯着一个点使劲想“,Visual Para-Thinker 让它学会”分区并行看、最后汇总“,就像人类面对一张复杂图片时,会同时扫视不同区域再综合判断。这对小米相册智能搜索、AR 导航中的场景理解等功能有直接价值。
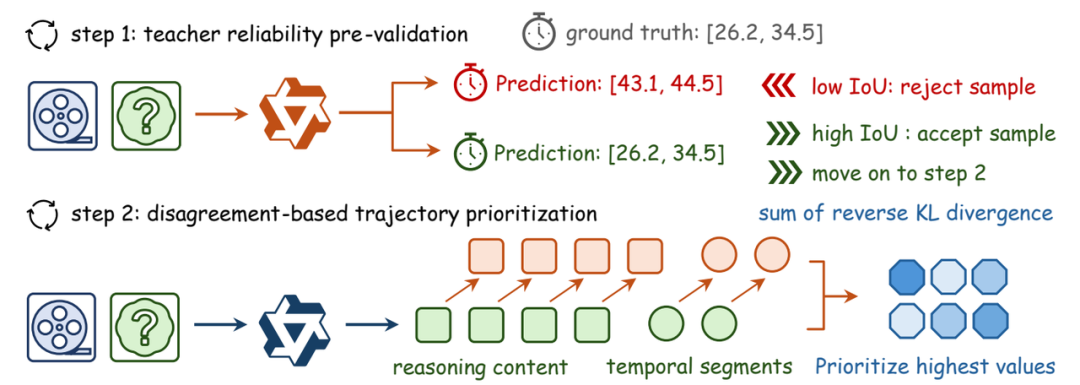
▍Video-OPD: Efficient Post-Training of Multimodal Large Language Models for Temporal Video Grounding via On-Policy Distillation
合作者单位:浙江大学,中国人民大学
论文作者:李佳泽,殷皓,许浩然,许博深,谭文辉,何泽文,鞠建忠,罗振波,栾剑
论文链接:https://arxiv.org/pdf/2602.02994
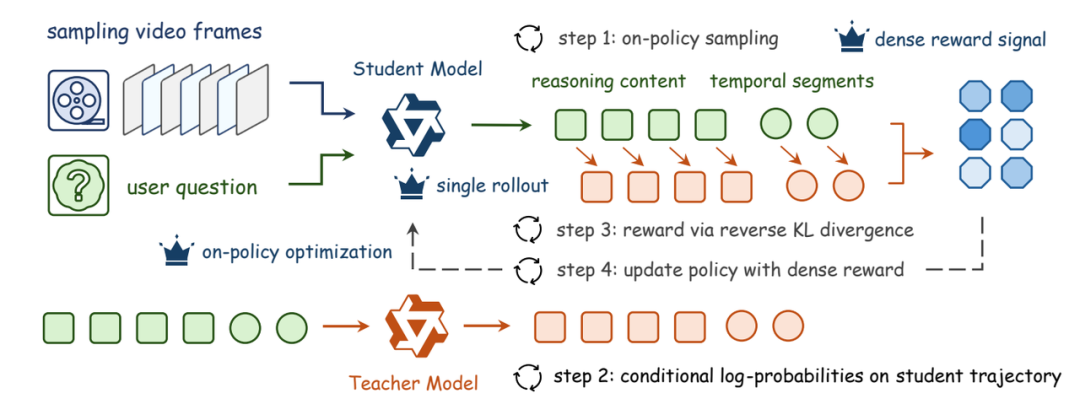
“帮我找到这个视频里他开始跑步的那个片段”,视频时序定位(Temporal Video Grounding)是视频 AI 最核心的能力之一。强化学习是当前提升此能力的主流后训练范式,但现有基于分组相对策略优化的方法面临两大瓶颈:稀疏的序列级奖励信号导致信用分配困难;多轮策略采样带来巨大计算开销。
Video-OPD 将稀疏的序列级奖励替换为来自教师模型的细粒度、逐词元的监督信号,同时严格保持策略在线的优化特性。进一步提出教师验证差异聚焦的训练课程策略,优先选择教师可靠验证且与当前学生策略存在最大差异的训练轨迹。
结果:显著超越现有 GRPO 方法,平均性能提升超过17%,且在多个更广泛的视频理解基准上展现了强大的泛化能力。计算开销大幅降低,实现了更优越的效率-性能权衡。
这对小米的视频编辑、智能监控回放、车载行车记录仪检索等场景意味着:AI 能更快、更准地帮你在长视频中定位关键时刻。
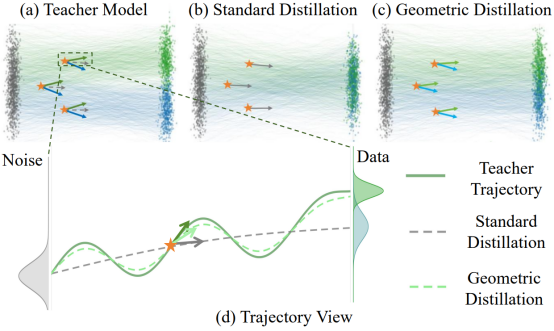
▍Restoring Initial Noise Sensitivity in Text-to-Image Distillation through Geometric Alignment
合作者单位:武汉大学,巴黎综合理工学院
论文作者:黄华洋,王若瑜,赵锦晖,邓巍,周代国,栾剑,武宇,竺烨
Stable Diffusion 等扩散模型通过蒸馏将多步采样压缩为少步生成,大幅提升了推理效率。但一个被普遍忽视的问题浮出水面:蒸馏后的模型对初始噪声失去了敏感性,不同随机种子生成的结果趋同,多样性下降,布局控制等下游能力也随之减弱。
本文指出根源在于主流蒸馏目标采用点对点对齐,在匹配输出的同时”抹平“了模型对输入扰动的响应能力。GAD(Geometry-Aware Distillation)从”对齐输出“转向”对齐响应“,通过 Jacobian 响应对齐恢复局部敏感性,且作为正则项无缝集成于多种蒸馏范式,无需额外推理成本。
在多个生成架构与蒸馏方法上均提升了功能一致性与生成能力;在布局/低级控制任务中显著恢复教师性能;同时有效缓解多样性与保真度之间的权衡。
通俗地说,蒸馏后的图像生成模型变成了“千篇一律的画师”,你给不同的灵感它画出来都差不多。GAD 让它重新变回“有想象力的创作者”,同一个提示词能画出风格迥异的作品。对小米手机影像 AI 编辑、壁纸生成等功能,这意味着 AI 创作更有惊喜感。
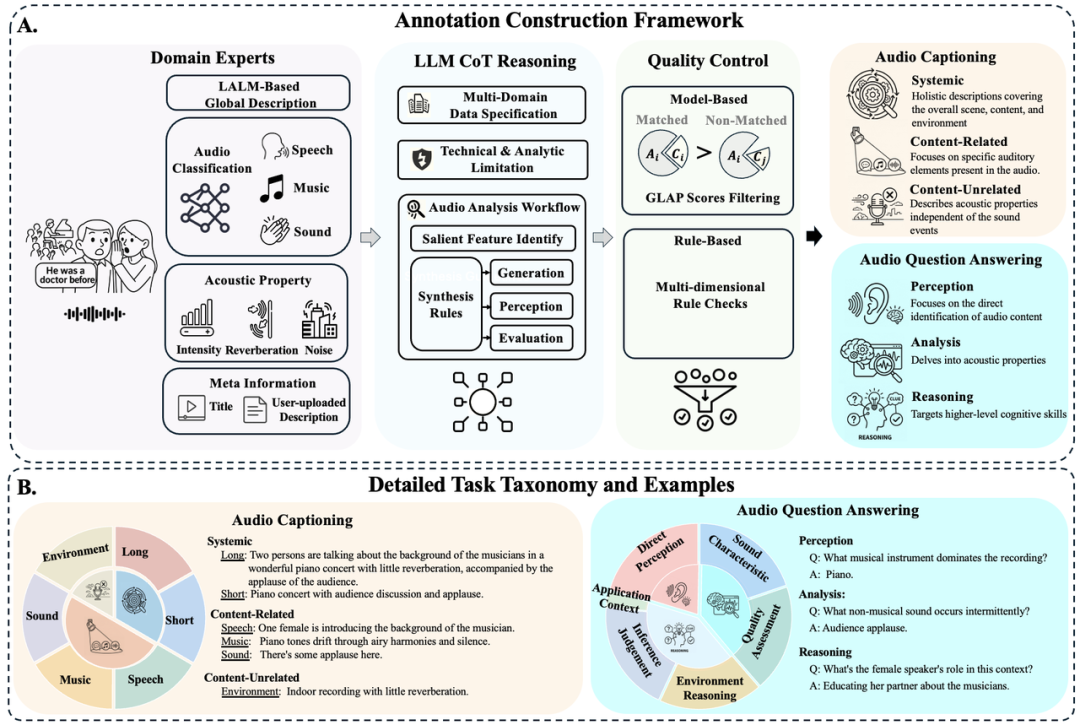
▍MECAT: A Multi-Experts Constructed Benchmark for Fine-Grained Audio Understanding Tasks
合作者单位:香港中文大学
论文作者:牛亚东*,王天资*,Heinrich Dinkel,孙兴伟,周嘉豪,李罡,刘继忠,刘循英,张俊博,栾剑
论文链接:https://arxiv.org/abs/2507.23511
项目链接:https://github.com/xiaomi-research/mecat
GPT-4o 能听懂语音了,但它真的能“听懂”一段复杂音频吗?语音、音乐、环境声同时出现时,即使是最强的 Gemini 系列模型,在细粒度音频描述任务上得分也仅为53.1%。
MECAT 针对此问题提出了一条完整解决路径。数据侧,构建了“多领域专家模型+LLM Chain-of-Thought 推理+多级质量控制”的自动化标注流水线,产出约20000条覆盖8个音频域的高质量标注。指标侧,提出 DATE(Discriminative-Enhanced Audio Text Evaluation),首次可量化地区分“泛泛之谈”与“精准描述”。
对17个主流模型的系统评测清晰地揭示了:从“事件级感知”到“细粒度语义理解”之间仍存在显著差距。这为小米小爱同学的音频理解能力升级(比如精准识别“谁在说话、背景是什么音乐、环境噪声来自哪里”)提供了明确的优化方向和评测标尺。
04
训练底座,让大模型训得更稳、搜得更准
模型再强,若训练过程不稳定,则难以落地;架构设计再精巧,若检索效果不准确,将无法使用。我们聚焦“基础设施级”问题,为大模型研发提供坚实底座支撑。
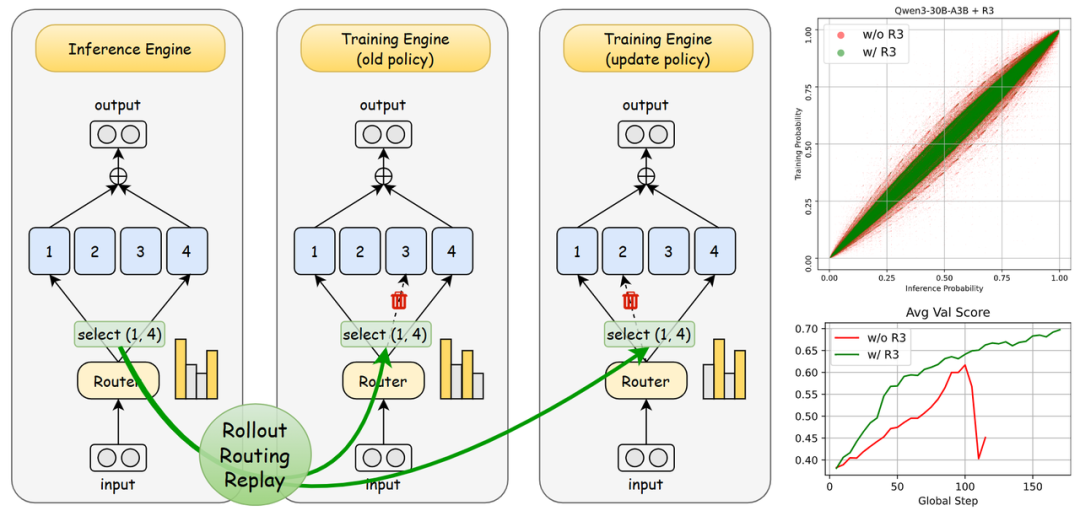
▍Stabilizing MoE Reinforcement Learning by Aligning Training and Inference Routers
合作者单位:北京大学
论文作者:马文晗,张海林,赵亮,宋一帆,王昱栋,穗志方,罗福莉
论文链接:https://arxiv.org/abs/2510.11370
MoE 架构在各家旗舰大模型中被广泛采用,其优势已成为行业共识。但一个棘手问题仍然存在:MoE 模型做强化学习训练时极其不稳定,动不动就崩。原因在于精度问题导致 MoE 的路由器在训练和推理阶段可能做出不同的专家选择,策略分布不一致,引发训练不稳定甚至崩溃。传统的重要性采样方法仍难以完全稳定训练。
本文提出的 Rollout Routing Replay(R3)通过在推理阶段记录路由分布,并在训练阶段重放这些分布,增强了训推的一致性。这不仅显著降低了训练与推理策略的 KL 散度,还能精准优化生成当前 Token 所需的专家,避免对未使用专家产生不必要的梯度噪声。
R3 在多个 MoE 模型族(Qwen3-MoE、DeepSeek-V2-Lite)的强化学习任务上均显著提高了训练稳定性,避免了训练崩溃。性能分析表明,R3 仅带来约 3.45%的训练速度下降和可控的内存开销。
直观来说,MoE 模型的训推不一致,本质上是“参与生成的专家”和“接收反馈的专家”可能并非同一批。R3 坚持“谁干活,谁收反馈”的原则,有效缓解了这一问题。这是小米为行业提供的一套切实可行的稳定性解决方案。
▍Structured Progressive Knowledge Activation for LLM-Driven Neural Architecture Search
合作者单位:西安交通大学,北方工业大学,中关村学院
论文作者:刘振*,刘雨涵*,王进军,宋伟,刘剑毅,付靖文
论文链接:https://arxiv.org/abs/2605.04057
项目链接:https://github.com/AIM-ResearchLab/SPARK
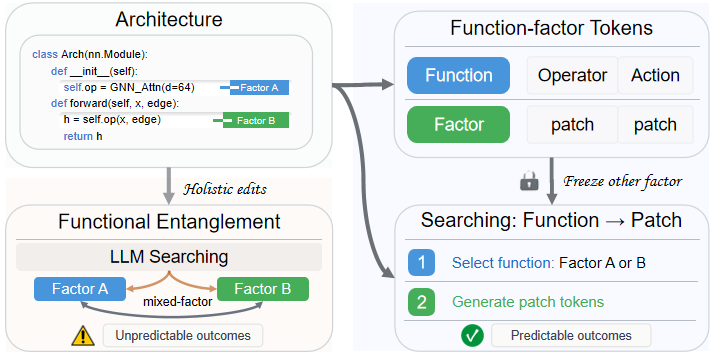
从 DeepMind 的 AlphaEvolve 到开源的 OpenEvolve,“让 AI 自己设计 AI”正在成为研究热点。让大模型充当“代码进化引擎”自动搜索神经网络架构(NAS)正在成为新范式。但 LLM 看似“局部修改”,却常常牵一发而动全身,候选架构频繁报错,导致评估预算浪费在无法运行的代码上。
本文将这一现象命名为“功能纠缠”(Functional Entanglement),架构代码中的“算子”和“调用方式”本该是两件独立的事,却被 LLM 同时改动。SPARK 提出“先定位、再修改”的结构化编辑范式:把代码切成 Operator 和 Action 两块互斥区域,每轮只动其中一块,让每个候选都能跑通。在相同的计算量下,计算成本更低,**准确率**更高。
通俗地说,过去用 LLM 搜架构像一个急性子的程序员“想到哪改到哪”,改一处坏三处;SPARK 让它像有经验的工程师,先想清楚“改算子还是改调用方式”,再只动那一块。这也为小米在端侧 AI、智能汽车、智能家居等场景下持续打磨更小、更快、更省的专用模型,提供了一条低成本、可规模化的底层技术路径。
从底层训练稳定性到模型推理增强,从 GUI Agent 全链路到多模态感知理解,这些研究成果勾勒出一幅清晰的图景:小米 AI 正在从“单点突破”迈向“体系化能力建设”。当你让小爱帮你订外卖、让手机自动整理相册、让汽车读懂行车记录仪,背后支撑的正是这些正在从论文走向产品的技术。ICML 2026,首尔见。











评论区
登录后即可参与讨论
立即登录