语音技术正在经历这样的变化:从“能听能读”,迈向“精准理解与灵活表达”。在真实的创作与交互场景中,机器不仅要穿透复杂的口语环境——方言口音、环境噪音、多人同时说话——还要能用声音塑造角色、拿捏情绪,让表达不再只是传递字词,而是传递感受。
无论是创作者,还是依赖语音技术的业务,真正需要的,是一个能被语言自由调度的语音系统:输入一段嘈杂的会议录音,它能准确转写;输入一句“这儿要低沉愤怒”的导演笔记,它便能生成恰如其分的演绎。 听懂一切,更能表达一切。
为此,我们今天正式发布 MiMo-V2.5-TTS Series 与 MiMo-V2.5-ASR —— 一套面向 Agent 时代的全链路语音模型系列,覆盖识别与合成两大核心能力,让语音的输入与输出都可以被语言自由调度。
-
MiMo-V2.5-TTS Series 包含三款模型,现已登陆小米 MiMo 开放平台,并且限时免费。三者共享统一的风格指令遵循、音频标签控制与文本理解能力,让声音表现可以被语言精细调度,分别覆盖三种典型创作需求:
-
MiMo-V2.5-TTS:内置多款高质量精品音色,支持语速、情绪、语气等精细化控制,开箱即用,满足多场景表达。
-
MiMo-V2.5-TTS-VoiceDesign:一句话快速定义并生成全新音色,让音色创作更直观、更高效。
-
MiMo-V2.5-TTS-VoiceClone:少量样本高保真复刻目标音色,同时保持稳定的风格指令遵循与音频标签控制能力。
MiMo-Studio 快速体验地址:**https://aistudio.xiaomimimo.com/#/c**
- MiMo-V2.5-ASR 正式开源。模型在中英双语、中文方言、Code-Switch、强噪音、多说话人等复杂真实场景下的语音识别性能达到业界领先水平,为 Agent 提供清晰可靠的语音转写,确保每一次交互都建立在精准的理解之上。
MiMo-V**2.5-TTS:让声音,成为每个人的创造力**
核心能力
-
精准的风格指令遵循能力
从简短的单句指令,到一整份导演笔记,模型都能稳定理解并遵循,覆盖情绪、语气、语速、发声方式、语言风格等多个维度。指令不必写成结构化参数——像给演员说戏一样把想要的感觉描述出来,模型就会落到对应的演绎之中。
对于一致性要求更高的场景——有声剧、游戏 NPC、角色化对话等——模型还支持导演剧本级的结构化输入:把人物、场景、详细指导分层描述,各层按自己的节奏独立更新、自由组合。这种分层既让角色的音色身份贯穿始终,也让每一句话的表演都能被单独控制。
case 1:

case 2:

-
灵活的音频标签控制能力
除了段落级的自然语言指令,模型还支持行内音频标签,用于在文本特定位置精准控制情绪、状态或风格。标签支持中英双语和开放文本描述,允许在同一段文本中灵活混用。从简单的情感标注,到多标签叠加、细粒度排布的复杂编排,模型都能稳定表达,在标签的表达力和组合稳定性上均有出色表现。
Text:
(调侃) 老张你当时不是说这条航线稳得很吗……
(模仿自信,提高音量) “系统全绿,放心走。”
(突然停顿) ……现在呢?
(爆发,愤怒压不住) 现在整艘船都在报警!你管这叫“放心”?!
(声音变轻) 不过……你看那外面,裂开的星云像在呼吸一样。
(急促|呼喊) 别断通讯!喂!再撑十秒!十秒!!
(低声|情绪塌陷般平静) ……算了。
(轻笑|带点释然) 也挺好,至少是一起看的。
-
丰富的文本理解能力
即便没有任何 prompt,也没有任何标签——就是一段最普通的文本——模型也能直接表现出其中的韵律与情感。标点的停顿、句式的起伏,会被自然呈现;文本中暗藏的情感弧线,从平静叙述到激烈转折,模型能主动捕捉;甚至连字里行间透露出的说话人身份(年龄、气质、角色类型),也会自动落到声音里。换句话说:最朴素的纯文本,交给它,也能还你一段有血有肉的演绎。
Text:
Ten... nine... eight... seven... six... five... four... three... TWO... ONE... ZERO! LAUNCH! LAUNCH! WE HAVE LIFTOFF! GO GO GO! SHE'S CLIMBING! ALTITUDE 1,000... 5,000... 10,000 FEET AND CLIMBING! BEAUTIFUL! AB-SO-LUTE-LY BEAUTIFUL!
模型系列
-
MiMo-V2.5-TTS
内置多种精品音色,涵盖多种使用场景,每个音色都经过专业调优,发音自然、情感贴合,开箱即享高质量语音合成。
欢迎大家到Xiaomi MiMo Studio 进行音色试听:
https://aistudio.xiaomimimo.com/#/c
-
MiMo-V2.5-TTS-VoiceDesign
音色设计面向的是"我心里有一个声音,但世界上还没有"的场景:游戏 NPC、动画角色、虚拟主播、品牌 IP、有声剧的非典型嗓音——这些都很难直接从音色库中挑选,也不适合用真人克隆。
该模型支持通过自然语言描述从零生成一款全新音色,无需任何参考音频。用户可以自由使用年龄、性别、口音、音质、发声方式、性格气质等任意描述维度——比如"一位年迈的东欧裔学者,低沉、略带嘶哑,说话节奏缓慢"或"元气满满的少女,声线清脆,语尾带一点上扬"——模型即可合成对应的角色音色。
得益于大规模预训练,模型对复杂、模糊、甚至相互矛盾的描述也能合理解读,而不局限于"男/女/青年/老年"这类粗粒度标签。这让音色设计不仅能生成真人不易提供的独特嗓音,也能精确复现某一类型化的角色声线。
Case 1:
音色描述: 一位中年男性,说标准普通话,嗓音低沉有磁性,带有轻微的沙哑质感,像纪录片旁白解说员,沉稳而有感染力。
Case 2:
音色描述: 一位年迈的老先生,说带北方口音的普通话,语速缓慢而沉稳,嗓音略带沙哑和沧桑感,仿佛一位饱经风霜的老爷爷在讲故事,充满岁月的智慧。
-
MiMo-V2.5-TTS-VoiceClone
音色克隆用于让模型用你指定的声音说话——复刻一位真人播客、配音演员、品牌代言人,或者用户本人。
只需提供一段短至数秒的参考音频,无需任何额外的训练、标注或微调过程,模型就能直接复刻出说话人的音色并立即可用。复刻后的声音不仅保留了原始说话人的音色身份,也保留了气息、节奏、习惯性停顿等个人特征。
克隆得到的音色可复用本系列模型的全部控制能力——自然语言指令、音频标签、导演剧本级脚本都能继续叠加使用。复刻的声音不仅"像原人",也能按你给定的风格与情绪去演。
Voice Prompt
Instruct: 用尖锐刻薄的嗓音,带着狐假虎威的得意感说话,在提到大人物的身份时故意放慢语速并加重语气,营造压迫感。
Text: 你以为我是谁,也敢在这儿跟我耍横?我告诉你,站在我身后的那个人,说出来吓死你——是当今的——万岁爷!你今天要是不给我个说法,我让你这铺子明天就开不了门。
MiMo-V2.**5-ASR:听懂你的每一次表达,无论多复杂**
如果说 TTS 是在“输出”端让声音成为创作工具,那么 ASR 就是在“输入”端为这一切打开大门。在真实场景下,语种切换、背景噪声、说话人带着浓重的方言口音,在这样的环境里还能听清、听准,才是真正好用的语音识别。
MiMo-V2.5-ASR 作为全链路语音模型系列的听觉基座,在中英双语、中文方言、Code-Switch、强噪音、多说话人、高知识密度等复杂真实场景下均达到业界领先水平。它不只是为了把清晰的语音转成文字,更是让 Agent 在嘈杂的真实声音里,抓住每一个值得被理解的字词。
核心特点
-
中文方言:支持吴语、粤语、闽南语、四川话等方言
-
英文复杂场景:在 AMI 等复杂英文场景 Open ASR Leaderboard 上达到领先水平
-
Code-Switch:中英 Code-Switch 语音转录自由流畅,无需预设语种标签
-
歌曲识别:中英文歌曲歌词识别,在伴奏与人声混合场景下保持高精度
-
强噪音场景:在高噪音、远场拾音等复杂声学环境中保持鲁棒识别
-
多说话人:支持多人交叉对话场景的准确转录,如会议场景
-
强知识关联:古诗词、专业术语、人名、地名等知识密集型内容的精准识别
-
原生标点:结合语音韵律与语义原生输出标点,转写结果即拿即用,无需后处理
性能表现
MiMo-V2.5-ASR 在中英文通用、中文方言、Code-Switch 及歌词识别等多个维度上均取得当前最优或极具竞争力的结果,展现出跨场景、跨语种的稳定优势。以下为代表性评测结果:
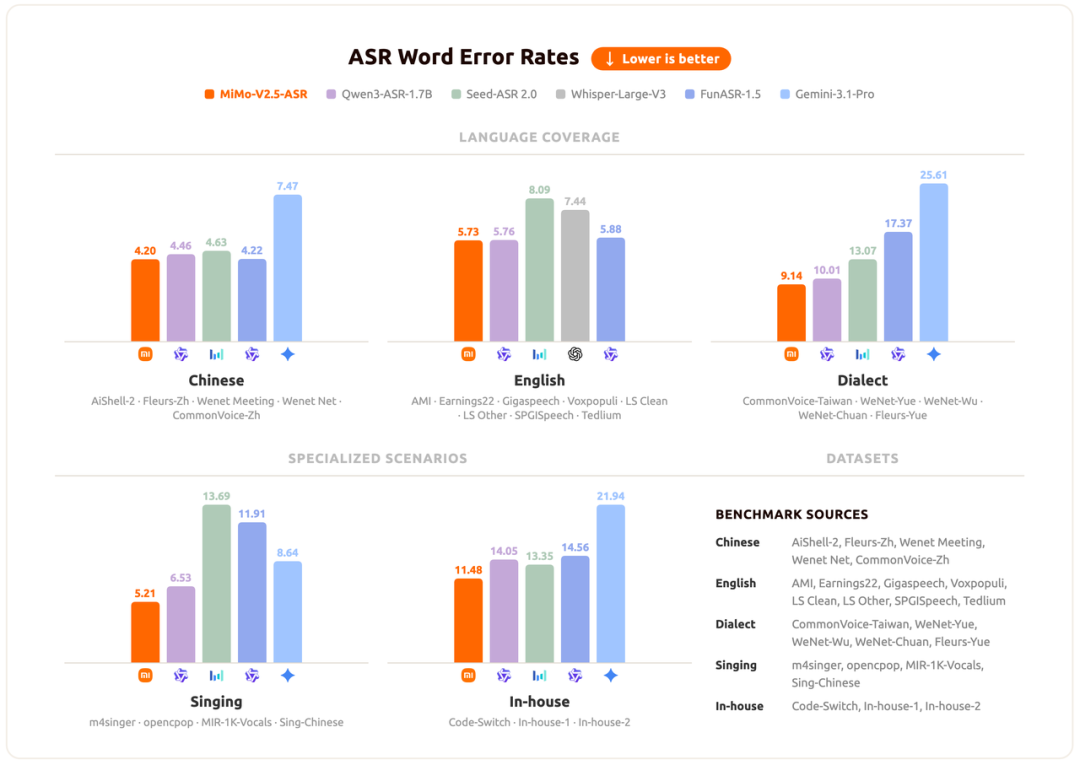
对于 Agent 应用、内容创作工具、会议系统、语音交互产品而言,这是一个真正在复杂真实世界语音中经过验证的听觉基座。
如何使用
MiMo-V2.5-TTS 系列
为助力开发者探索更多场景,MiMo-V2.5-TTS、MiMo-V2.5-TTS-VoiceDesign、MiMo-V2.5-TTS-VoiceClone 均在 Xiaomi MiMo API 开放平台限时免费**:**
https://platform.xiaomimimo.com/docs/usage-guide/speech-synthesis-v2.5
同时,欢迎大家到Xiaomi MiMo Studio进行快速体验:
https://aistudio.xiaomimimo.com/#/c
更多case请见:
https://mimo.xiaomi.com/mimo-v2-5-tts
MiMo-V2.5-ASR
MiMo-V2.5-ASR 目前已开源模型权重和代码,支持开发者和研究者直接使用或二次开发。
Demo page:
https://mimo.xiaomi.com/mimo-v2-5-asr
项目开源地址:
https://github.com/XiaomiMiMo/MiMo-V2.5-ASR
权重开源地址:
https://huggingface.co/XiaomiMiMo/MiMo-V2.5-ASR
Huggingface space:
欢迎大家使用!
Agent 工具调用支持
为方便大家将语音能力快速集成至 Agent 应用中,我们已将 MiMo-V2.5-TTS 相关模型的接入 Skill 全面开源。欢迎前往仓库拉取使用:
https://github.com/XiaomiMiMo/MiMo-Skills
声音,只是起点
在 MiMo-V2.5-TTS Series 之外,我们更想回答一个问题:
当 MiMo-V2.5-TTS 懂“表达”、MiMo-V2.5-Pro 懂“规划”、MiMo-V2.5 懂“聆听”,音频创作会变成什么样?
答案是:一条完整、可闭环的 Agent 式创作链路。
-
MiMo-V2.5-Pro —— 规划与编剧,拆任务、写剧本、排节奏、决定剪辑顺序。
-
MiMo-V2.5-TTS Series —— 音色与素材,Voice Design 生成音色、Voice Clone 合成内容。
-
MiMo-V2.5 —— 听回与评价,听角色一不一致、节奏对不对、有没有跟用户初衷偏离。
一个例子:
做一段 2 分钟左右的夏日午后场景。爷爷(70 多岁,北京胡同味儿,嗓门哑、说话拖长音、下棋专注时压低声、笑起来哈哈一声拍桌)在槐树下对弈。5 岁小孙子蹲旁边看蚂蚁,不时冒出奶气问题打断(清脆、尾音上扬、兴奋时拔高、咬字偶尔不清)。爷爷动真格时语气沉、被孙子打断时立刻松下来笑骂。
用户只给一句话,成品自己出来:
会说是门槛,会听、会想、会协作才是价值。
Next step
更大规模的语音**预训练与强化学习**后训练:
MiMo-V2.5-TTS-Series 证明了大规模预训练与后训练的巨大收益,扩大这两者的规模:通过更多的数据、更大的模型、更强的算力,让更强大的语音智能从规模中涌现;更加精细的奖励建模与强化学习算法,推动模型迈向更高阶的语音表达智能。
通用**音频生成**:
语音只是第一步。我们正在将能力扩展到更广义的音频生成:环境音效、动作声、氛围铺底,乃至短乐句与旋律片段——逐步建模出一个完整的声音世界。我们相信,真正的通用音频模型,不是把语音、音效、音乐简单拼在一起,而是让它们在同一套空间里彼此理解、协同创作。
上下文**理解能力:**
语音表达从来不是孤立的句子游戏。人之所以能“读对”,是因为理解上下文——知道前面发生了什么,明白当前这句话在整个叙事中处于什么位置。上下文理解意味着模型不再只是一个“逐句执行的工具”,而是一个懂得故事语境的表达者。这是我们迈向真正通用语音智能的关键一步。
通用语音理解能力:
我们的目标是,让方言、噪音、中英混杂这些“真实世界的常态”不再成为语音识别的短板。未来,我们将持续扩展更多方言覆盖、并深化上下文感知能力,让语音识别从“转写”走向“理解”。









评论区
登录后即可参与讨论
立即登录