[
因为有AI的加成,强调AI能力的工作站出货量今年预计会增长65.2%(数据来源:IDC)。恰好,最近Intel面向工作站和边缘服务器发布了至强600处理器和Arc(锐炫)Pro B70显卡。
和以往的工作站处理器发布会相比,今年的至强600和Arc Pro B70发布会AI浓度全面拉满:从头到尾都是AI...那么在AI尤其是智能体AI大火的当下,面向工作站的CPU和GPU,与过去会有什么不同?至强600和Arc Pro B70的诸多AI特性,或许能提供个参考…
强调智能体AI的工作站CPU,长这样…
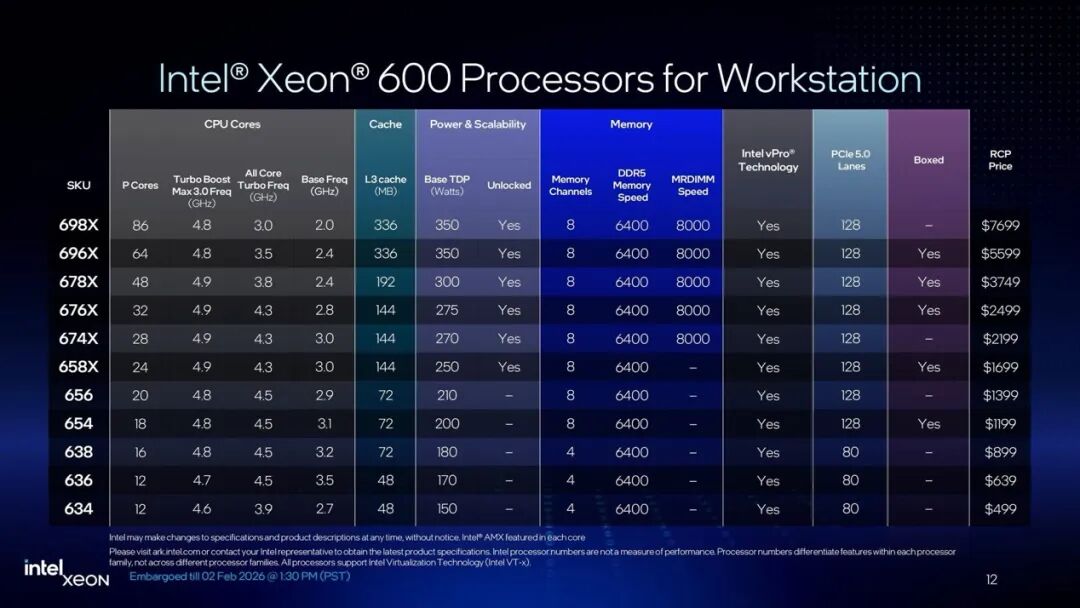
目前Intel官网可以查到的至强600系列处理器,从12核、48MB L3 cache的至强634,到86核、336MB L3 cache的至强698X总共11个型号(如下图)。至强600和面向服务器的至强6的P-core版一样,同属Granite Rapids家族,所用CPU核心为Redwood Cove;
用于作为至强w-2500/w-3500系列(Sapphire Rapids)的迭代款,直接竞对应该是隔壁的Ryzen Threadripper Pro 9000系列。
了解至强6的读者对于这代芯片的系统架构应该不会陌生:和P-core版至强6700系列的最高配一样,芯片封装内总共2片采用Intel 3工艺的计算die(实际上应该是compute tile叠在有源base tile之上),通过EMIB硅桥连接;
计算die的旁边还有两片基于Intel 7工艺的IO die。电子工程专辑此前介绍至强6的文章对此已经有了比较详细的介绍——2.5D/3D封装也是至强6/6+能堆出明显更大L3 cache的技术支撑之一。

Intel在媒体活动上强调了至强600的几个关键特性:(1)最多86个P-core;(2)128个PCIe 5.0通道,支持最多8个PCIe 5.0 x16扩展;(3)支持CXL 2.0,可扩展CXL内存池;(4)内存方面对MRDIMM DDR5 8000做出支持;(5)RAS能力强化平台稳定性(“4大类别,48项RAS功能,包括会上特别强调的ADDDC相比传统ECC可以做到"double device"纠错),及借助Intel OpenBMC实现了更自动化的运维;
(6)搭配W890芯片组,可扩展Wi-Fi 7/6E, 1/2.5GbE LAN, USB 3.2 20G, SATA 3.0, PCIe 4.0, eSPI, SPI, SMBus, 高清音频等扩展...(7)型号尾缀带X的产品(至强698X/678X等)还支持超频,用以满足“对时延非常敏感的任务要求”,“如高频量化交易”。
按照惯例此处列出其中最高端型号至强698X与其上代(至强w9-3595X)的规格对比:
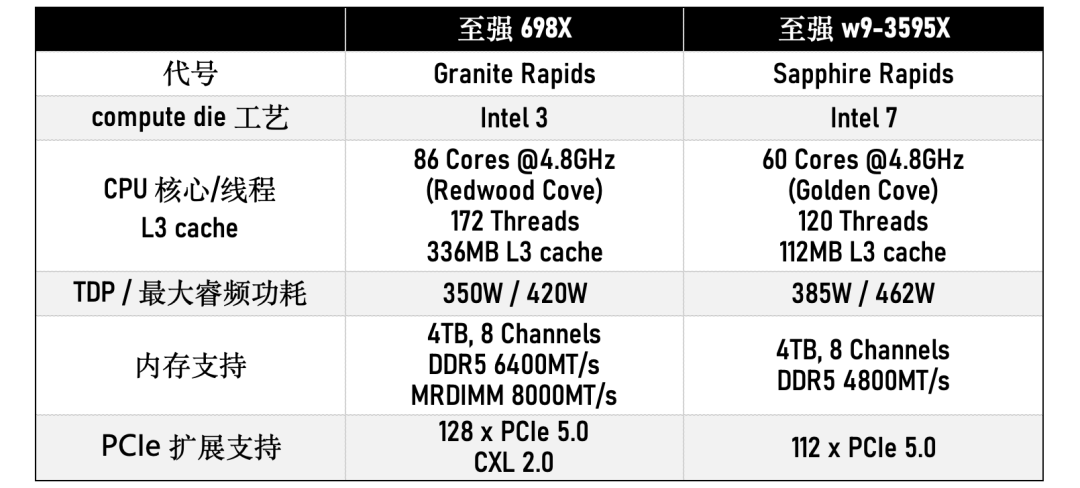
Intel给出的性能提升数据为,至强698X相比至强w9-3595X单线程性能提升9%,多线程性能提升61%;以及“更快的线性代数计算性能”(↑24%),“更快的大数据集分析(↑18%)”。
至强600系列和AI加速挂钩的部分自然是重点。首先是核心层面的AMX与AVX512指令集加速,配合OpenVINO与oneAPI工具套件,“可以实现CPU对AI的直接推理加速”;以及支持8张PCIe 5.0 x16 GPU,令至强600平台成为目前“AI工作站的最佳选择”;
其次是对MRDIMM内存的支持——MRDIMM(Multiplexed Rank DIMM)支持对2个rank同时操作,因此单次传输也就能给CPU喂128B的内存数据,是传统DDR5 DIMM的2倍。

高宇(英特尔中国区技术部总经理)解释说,MRDIMM模组藉由内置的data buffer支持同时激活两个rank,传输吞吐提升2倍,内存加载延迟降低40%;是AI等类型负载“突破内存墙非常有利的手段”,也令至强600平台+MRDIMM“更加适合AI大模型推理、高性能计算、大数据分析等场景”。
另外对CXL 2.0技术的支持——“至强600第一次将这项技术带到工作站平台”,尤其新增Type 3设备即内存扩展的支持,得以让平台支持“直接在PCIe槽上插入内存扩展卡来扩展内存容量,在AI工作站上可作为KV cache的高速缓存加速AI推理”。
系统性能方面,王巍巍(英特尔中国区AI技术方案总监)给出了几组数据:SPECworkstation 4.0基准测试(但活动上没提具体搭配了什么显卡),至强698X相比至强w9-3595X,AI与机器学习性能提升17%,能源性能提升22%,金融服务性能提升61%,生命科学性能提升19%,媒体和娱乐性能提升10%。

而真实HPC与AI场景中:传统科学计算应用领域,Intel谈到了基于WRF的天气研究与预测应用,至强698X运行行业标准的CONUS-2.5km基准测试,速度提升约87%(26分钟 vs 14分钟);
如果是跑AI相关的AlphaFold 3,“对于中等大小的生物分子进行32个并行预测时”,“凭借更多的核心数量、更大的L3缓存容量”,至强698X的每日可预测数达到783,相比至强w9-3595X推理吞吐提升44%;
另外,还有基于OIDN(Open Image Denoise)AI降噪库的图片降噪测试,至强698X能把降噪速度提升5倍——这个测试主体应该是Intel为了特别展示至强600系列的AMX-FP16加速。因为OIDN工具的核心就是一个FP16函数,则通过AMX指令集新增的FP16数据格式支持,就实现了5倍提速。
提到AMX,值得一提的是:除了完全跑在CPU上的AI应用(如对内存容量有高要求的AlphaFold 3),在大部分人的认知中,对于高性能与高token吞吐需求的AI计算场景而言,CPU的核心角色都在于编排器和控制器,AMX指令集层面的加速意义可能并不太大;但实际上,就整个系统的角度而言并非如此。
王巍巍在采访中说,“较重的矩阵加速运算的确都跑在GPU上,但这类AI负载有不少前处理、后处理操作,完全可以放在CPU上借助AMX指令集去跑,通过这样的offload来大幅提升整体吞吐——不少CSP都有这方面比较惊喜的数据结果”。
高宇则提到与趋境科技合作的案例,由于显存容量限制,跑MoE模型时“让热专家跑在GPU上,冷专家可以扔回GPU主存;运算时,就算点中冷专家也不用将其转移到GPU,直接通过AMX推理,节省了数据来回搬运的时间——我们实测也有相当好的效果。”

目前对至强600系列处理器做出系统级硬件支持的已经包括了8家OEM/ODM厂商、7家主板厂商;
推理工作站显卡,要追求长上下文、高并发
相较Granite Rapids对于Sapphire Rapids的换代,本次发布的面向AI工作站/服务器的Arc(锐炫)显卡就属于同代演进了。同属Battlemage家族,Arc Pro B70/B65应该可以视作B60的规模扩大版——对B60熟悉的读者应该知道,它被Intel定位为“AI推理工作站”显卡。
整理两款新卡规格如下:
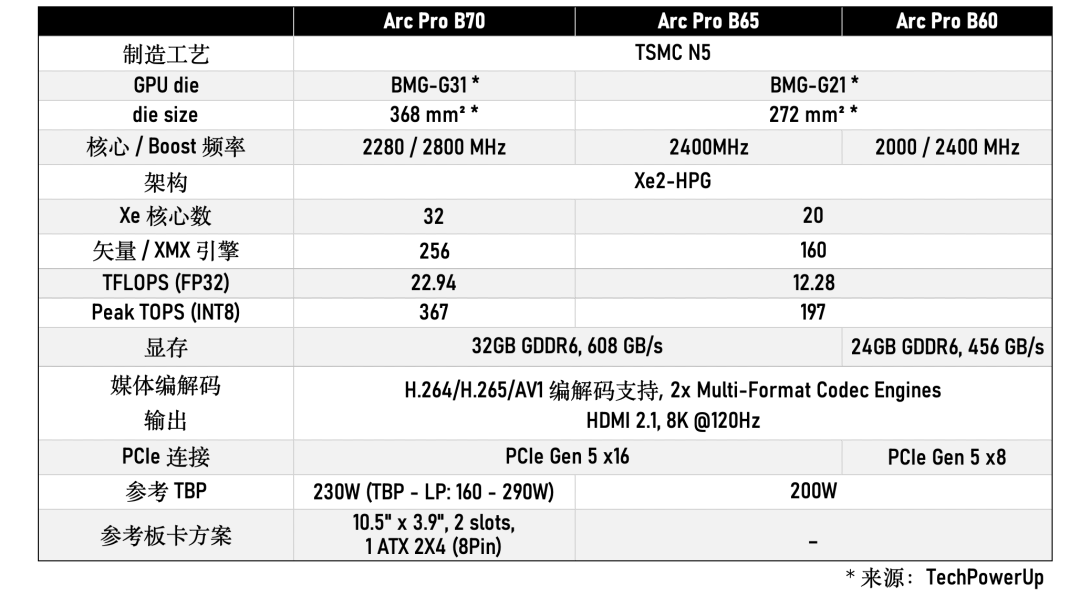
Arc Pro B65基本上可以认为是B60的VRAM增大版(24GB → 32GB);而从可查的公开信息来看,Arc Pro B70用上了一颗新die(BMG-G31,传言未来的Arc B770也会用上这颗die),尺寸更大,Xe核心更多——对应的XMX矩阵扩展引擎也更多,标称AI峰值算力367 TOPS。
对Xe2核心架构感兴趣的读者可查看前年电子工程专辑的解读文章,本文不再赘述。
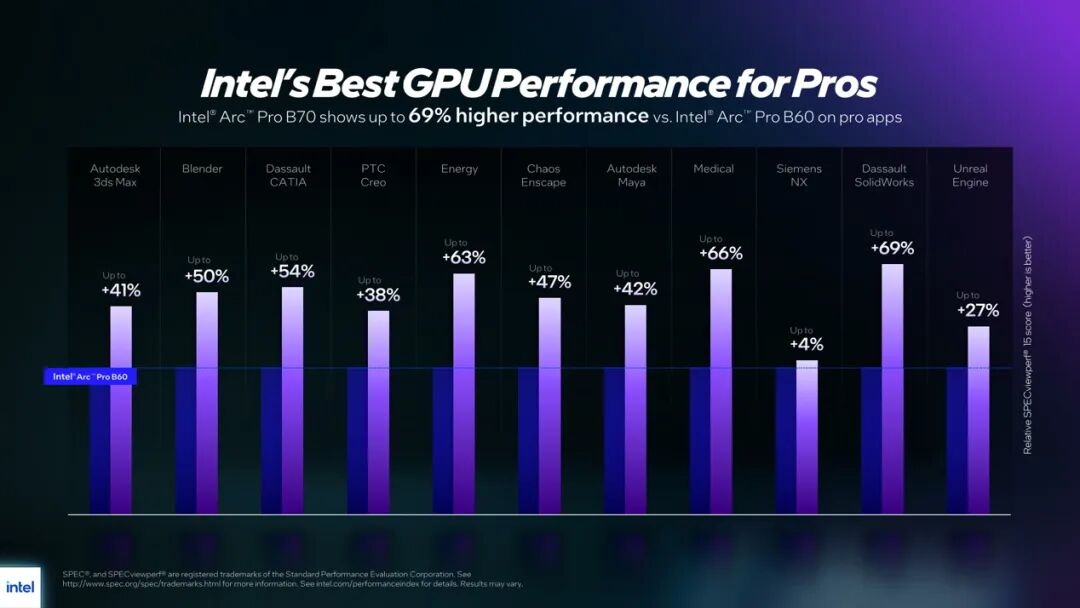
Intel对于这两张Battlemage新卡的目标市场定位主要有三:(1)专业设计市场;(2)视觉处理和AIGC;(3)各类AI应用。上面这张图从3D涉及、工程CAD,到专业仿真等不同应用之中,Arc Pro B70相比B60的性能提升,从虚幻引擎27%到SolidWorks 69%,应该说是比B60高出一个身位的。
而在针对AI应用场景时,另外更大的VRAM显存——也是Intel Arc Pro显卡面向工作站和边缘服务器时,有底气说自己性价比更高、是低成本部署方案的根源之一。在更追求更大显存的智能体AI时代,自然也是要强调单卡32GB VRAM的价值,所以下面这张图对比的应该是绿厂的A4000…
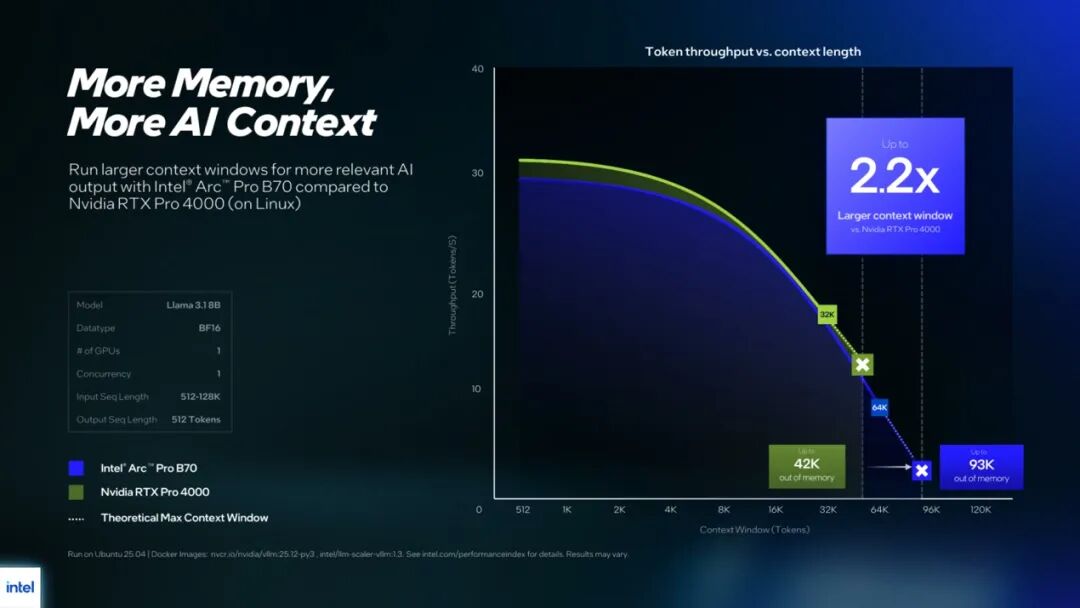
单卡跑Llama 3.1 8B,对应不同上下文窗口和吞吐量(Tokens/s),更大的显存令B70支持的上下文长度多出了2.2倍,算是单卡跑龙虾的实现基础了…
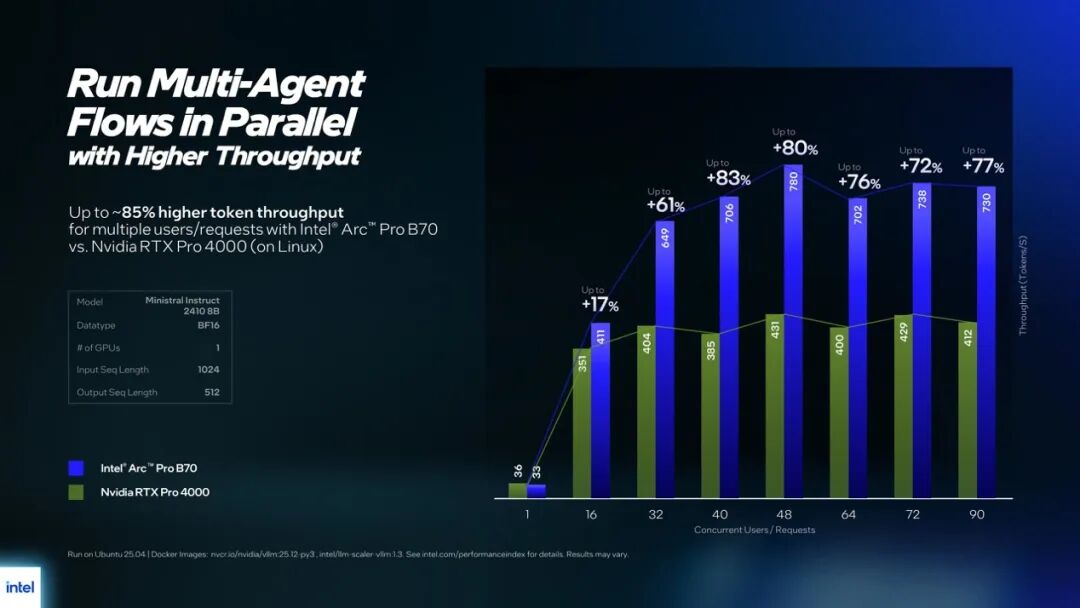
单卡跑Mistral Instruct2410 9B,横轴为并发用户数(或请求数),纵轴为吞吐(tokens/s),故而Intel给出数据:在面向多用户/多请求场景时,B70的token吞吐量最高可提升约80%...另外这里没有放出首token时间对比,Intel的数据是在不同并发数下,B70相比竞品的响应速度优势最多有6.2倍…
单纯从GPU芯片用料来看,现阶段的Arc Pro显卡和Arc游戏卡还是基本相似的;面向专业视觉应用或AI推理加速的关键,其实就在于更大的VRAM和全栈验证过的软件解决方案。
所以软件部分,高宇强调Arc Pro B70完成了针对诸多主流专业软件(如上图与B60做性能对比的仿真与设计类应用)的适配和认证,确保工作站与边缘服务器场景所需的稳定性与可靠性;

Arc显卡对主流的、最新的AI模型的及时支持,涵盖生图、生视频、多模态、LLM等类别7b-100b以上参数量模型的支持情况,包括最新的Qwen3.6-27B…
同时面向AI应用的边缘系统用户群时,除Arc对主流AI模型的快速支持;Intel提供容器化全栈交付,“我们会将Intel所有相关patch、软件组件的正确版本打包在一个容器内,并做全栈验证;并持续分阶段发布和更新功能,对模型、kernel第一件时间做出支持”——这类软件或解决方案交付方式,也算是当代AI芯片企业的必修了,我们也在相关B60行业应用的历史文章中做过阐释。

媒体活动上能够看到至少已经有4家AIB厂商推出了Arc Pro B70和B65显卡,包括铭瑄、蓝戟、Sparkle、ASRock等;从单槽位到双槽位、涡轮散热到被动散热…
活动现场,Intel和合作伙伴用了大量篇幅去谈Arc Pro B70在专业设计、视觉处理、AI这三个方面的应用。比如有视频制作者分享B70的媒体编解码能力出色,10-20轨4K 60素材并行剪辑无压力,30分钟视频输出速度比旧方案快了将近5倍;将3PB视频素材完全交给4卡B70工作站做AI OCR,便于未来视频内容的索引;
单卡B70生一张1024x1024的图片用时3.9秒(Z-Image-Turbo, BF16);单卡B70生成5秒480p视频92秒(Wan2.2-I2V-14B, FP8, 4 step lora加速)等等;这些都只能说是寻常——实际上更偏行业与企业应用的展示中,高宇总结Arc Pro B70的特点是“非常适合长上下文、多并发场景”。
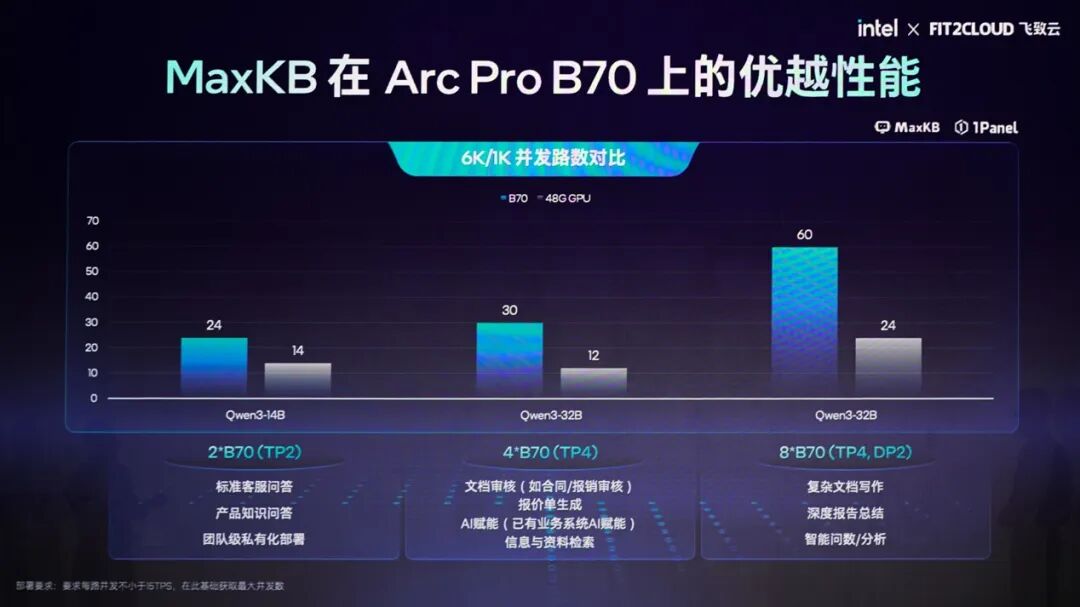
飞致云的MaxKB企业级智能体开发平台上,飞致云也谈到了B70“并发性能有非常好的表现”,“8卡配置轻松应对50以上的并发”(Qwen3-32B,6K输入长度、1K输出长度)——如标准客服场景、复杂或深度文档处理,每路用户也能获得15 tokens/s的解码速率…
有关这一点,给我们留下深刻印象的是B70在AI医疗领域的应用:东华医疗在谈及其电子病历智能体AI解决方案,具体到病历内涵质控与辅助生成(基于采集到诸如医嘱、病历、用药、用书等信息,实现电子病历自动生成与质量的智能审查),8卡B70相比8卡B60,病历辅助生成的并发性能提升8倍,病历内涵质控并发性能提升了67%,而且是在“整机价格没有特别大变化的情况下”。
在并发性能显著提升这一点上,几个案例均有倍数级提升,一方面自然与VRAM容量与带宽提升息息相关;另一方面在GPU架构并无大变的情况下,算力单元(Xe核心)堆料增加实际也就86%,再考虑多卡运行无法达成线性性能提升,则自B60至今的这段时间,推测Intel应该是有在软件方面下工夫的——即便上述案例可能只是个例。这对小型企业或部门级边缘AI系统而言,自然成为足够有性价比的方案。
从个人龙虾,到龙虾池…
既然聊到大显存、高并发、长上下文这些全面看齐智能体AI时代的要素,以龙虾应用为代表的智能体AI自然是一定要被端上桌的。王巍巍在做AI应用场景演示时,有3个演示都给到了龙虾。
其一是酷睿Ultra处理器+Arc Pro B70构成的个人龙虾工作站——前几天Intel在发布“智能体PC”概念时就提到过用酷睿Ultra养龙虾,搭配上B70构建龙虾工作站自然不是什么问题:基于Qwen3.5-35B A3B Q4量化模型这一主脑,现场演示了128K/256K长文本输入输出支持能力,和32GB VRAM依然是分不开的。
而上到至强698X,单颗就能容器化部署86个龙虾,构成“企业智能体Farm”,在农场构建“龙虾池”,来共同完成复杂的智能体任务——虽然演示的实际也就是数据科学前沿领域的问答。

至强600+四卡Arc Pro B70“企业智能体一体机”
最有意思的演示,应该是至强698X + 四卡Arc Pro B70构建起“智能体一体机”,基于Qwen3-Coder-Next-80B模型,部署24只龙虾——并行监控24支股票,并每隔10秒完成一次迭代,“只需要小时级别的时间,就能将整个市场的所有个股全部分析完毕”……
从介绍来看,这个过程是由“本地虾脑”“高并发智能市场分析和策略代码生成,实时观测多个市场模块,在量化交易场景下完成快速、准确的自动决策”。虽然不知道可靠性怎么样,至少它呈现了为企业实现隐私可控、低延迟、相对低成本的高密度代码生成智能辅助。

感知型AI、生成式AI、智能体AI(以及Intel眼中我们正走向“混合AI”),改变的还真的不只是工作站或边缘服务器,也不只是企业与行业的发展;连Intel的CPU、GPU新品发布会,都从以前强调制造工艺、封装技术、核心数与频率、缓存容量、系统性能对比,走向了大半时间在谈软件和应用——这还真是相当的“不Intel”…
虽然可能也是因为至强600系列CPU和Arc Pro B70显卡用的都是既有架构和工艺,让Intel有更多的机会去谈软件与生态。郭威(英特尔市场营销集团副总裁、中国区总经理)在开场致辞时就说,芯片产品最终都是要“携手各行业伙伴,深耕金融、制造、科研、创意等领域,助力千行百业智能化转型”的,这一点在智能体AI时代可能显得尤为突出:
一方面是通过软件与应用触达更多行业和领域,另一方面是这些涉及上层的解决方案更大程度地需要Intel插手。当然芯片作为承载上层应用的算力底座仍然是重要的,依旧是达成高性能与高效率的基础;但这一两年的Intel发布会,让Intel看起来更加不像是过去那个明显只专注“硅”和“半导体”前沿技术的企业;这或许也是AI时代背景下,半导体企业谋发展的一种写照。









评论区
登录后即可参与讨论
立即登录