[
当英伟达CEO黄仁勋在2026年GTC大会上抛出"The Inference Inflection Has Arrived"(推理拐点已至)这一论断时,整个半导体产业都感受到了范式转换的震感。从2023年的GPT模型到当下,用于推理的token数量正以每年十倍的速度疯狂增长——火爆的OpenClaw(小龙虾)、Anthropic的Claude引发的AI Agent热潮,正在将token推向一种新型"商品"的地位。
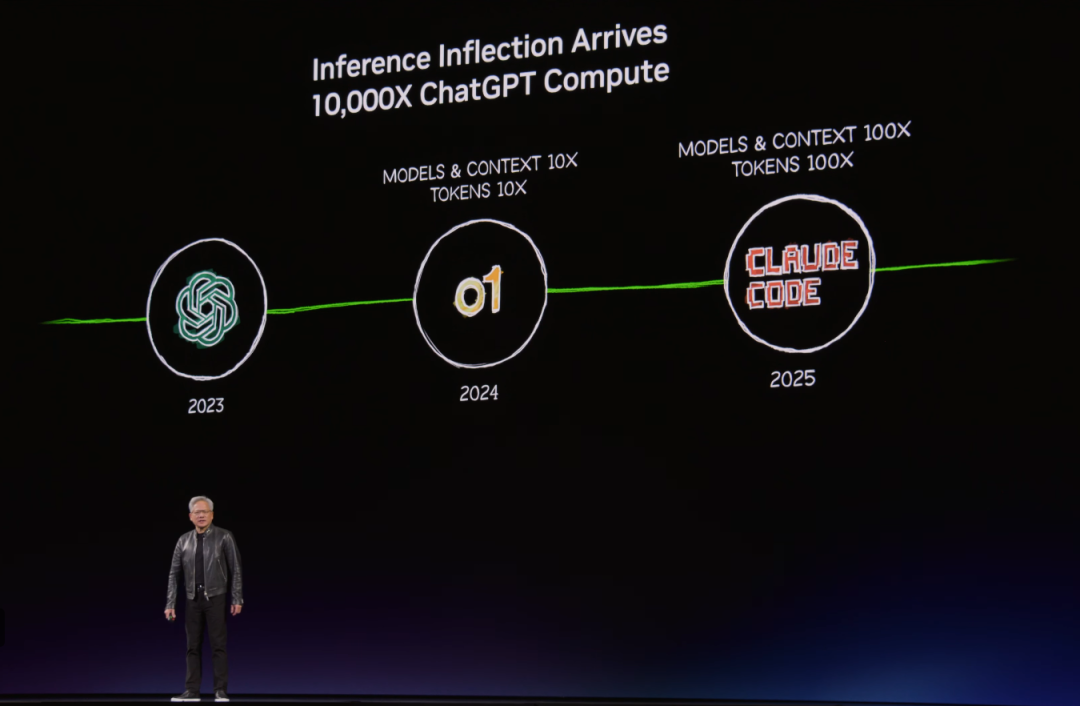
"我们过去强调算力,现在则更注重如何将算力转化为token经济,即衡量单位功耗产生的token以及每美元能产生的token数量。"日前,奎芯科技联合创始人兼副总裁王晓阳在由Aspencore举办的EETalk直播中指出——这一转变绝非简单的技术迭代,而是整个AI芯片竞争逻辑的根本重塑。
奎芯科技联合创始人兼副总裁 王晓阳
推理时代来临:AI芯片竞争范式的历史性跃迁
回顾AI芯片的发展轨迹,我们可以清晰地看到两条截然不同的路径。上半场是训练主导的"单芯片霸权"时代——比拼的是单个GPU的FLOPS算力、HBM容量、工艺节点。H100、H200的发布会成为行业风向标,芯片的大小、服务器内能集成多少芯片是竞争的核心。然而,当AI应用从实验室走向千行百业,推理场景对延迟、吞吐量、功耗的差异化需求,正在将竞争边界从芯片层面推向整机、集群乃至供应链能力。
"AI芯片的下半场,不只是算力竞赛,而是系统组织能力竞赛。"王晓阳如是总结。这一判断的背后,是推理负载本身的深刻变化。当前业界公认的高效做法是将Prefill(预填充)和Decode(解码)阶段分离处理——前者是算力密集型任务,后者是访存密集型操作。NVIDIA在其最新的AFD(Attention and FFN Disaggregation)架构中,甚至进一步将解码阶段拆分为计算部分和FFN部分的独立处理。

更具前瞻性的是"以存储为中心"(Memory-Centric)架构的兴起。王晓阳指出:"以往的AI计算,乃至整个计算领域,主要以计算为核心。然而,未来将更多地转向以存储为中心的计算架构——无论数据以何种形态存在,是CPU、GPU还是ASIC,计算都将围绕存储进行。"
这一范式转变对先进产能的分配提出了全新命题。据预测,到2026年台积电N3产能中超过60%将用于生产AI芯片,且这一比例可能持续增长。在先进制程成为长期稀缺资源的背景下,把它用在刀刃上才是最经济的系统级考量——这正是Chiplet架构崛起的宏观逻辑。
巨头们的Chiplet棋局:从通用GPU到场景化ASIC
如果说Chiplet曾经是AMD、Intel等追赶者的"弯道超车"策略,那么在AI算力需求爆发的今天,它已成为包括NVIDIA在内的所有玩家的必选项。
NVIDIA的演进轨迹最具说服力。从H100的单Die巨芯(4nm工艺、CoWoS封装、80GB HBM3),到B200/GB200的双Die Chiplet架构(NVLink 5.0、192GB HBM3e),再到即将推出的Rubin/Vera多Die系统(NVLink 6.0、定制互联网络)——NVIDIA已从单芯片算力霸权过渡到多芯片乃至整个系统的算力霸权。Rubin架构中,GPU、CPU、SmartNIC、DPU、Switch芯片乃至光互联技术形成完整闭环,构建起从芯片内到机架级的私有生态壁垒。
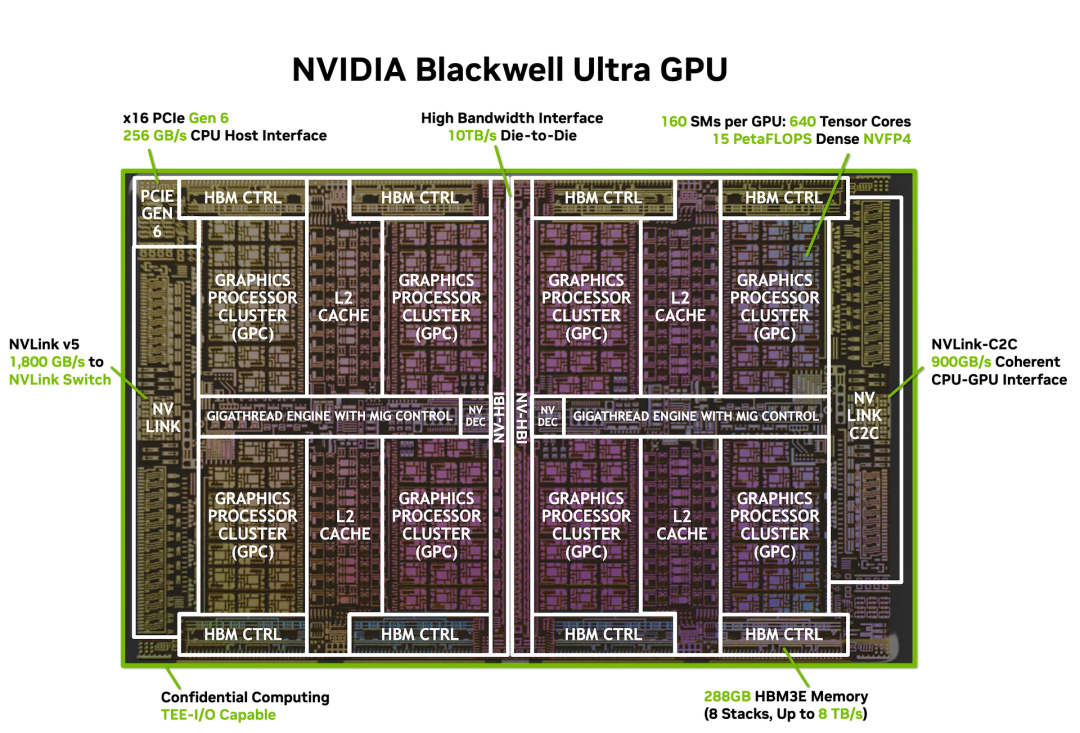
"NVIDIA已从B200开始采用双Die Chiplet架构,证明大算力芯片走向多Die是必然。"王晓阳分析道,"但NVLink是私有协议,这给了UCIe等开放标准巨大的市场空间。"
AMD则是Chiplet架构的先驱。早在2016年,AMD就开始研发基于多Die形式的Zen架构,Zen 2起率先商用不同工艺解构芯片设计——一个IO芯片加多个计算芯片。MI300X采用CPU+GPU混合Die设计,配备192GB HBM3和3D V-Cache垂直堆叠缓存。作为UCIe联盟的创始成员,AMD正积极推动开放互联生态。
Intel虽然略显落后,但其技术储备不容小觑。Foveros 3D封装技术、EMIB高密度Die-to-Die桥接互联,以及Ponte Vecchio超级计算机中47个Tile的超多Die集成,都展现了其在先进封装领域的深厚积累。
然而,真正的变革力量来自ASIC定制化浪潮。谷歌TPU、AWS Trainium、Meta MTIA、Microsoft Maia——云巨头纷纷自研芯片,核心诉求只有一个:在特定场景下实现极致效率。
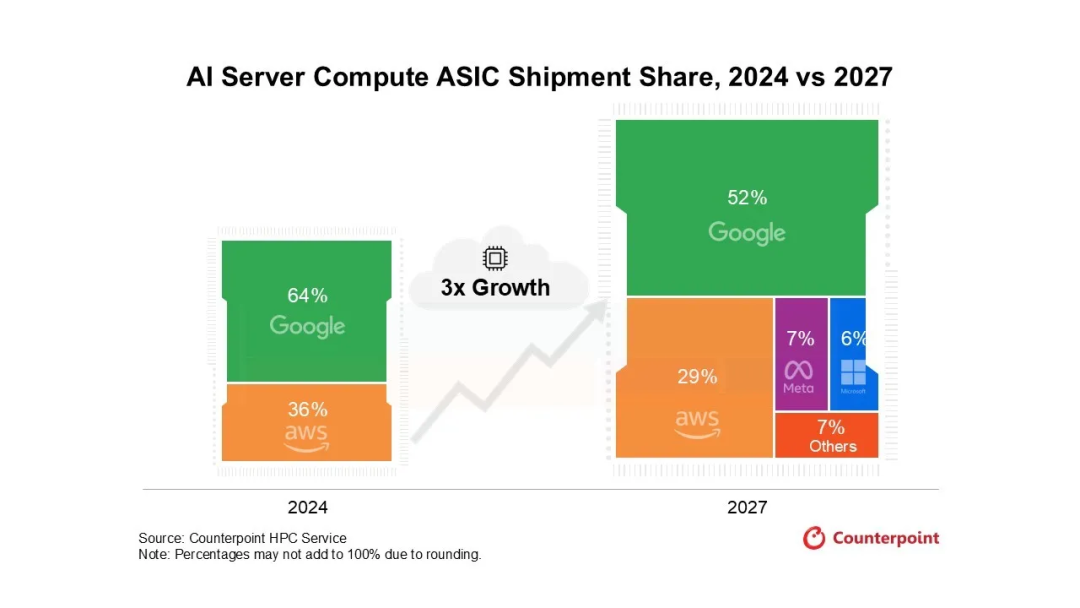
"追求通用性必然意味着必须牺牲一定的效率。世界上不存在既通用又拥有极致效率的事物。"王晓阳道出了ASIC崛起的本质逻辑。当token成本趋近于零成为行业共同目标,针对特定应用和模型场景进行性能优化的定制芯片,便成为无法回避的选择。
从AI芯片版图来看,云端推理ASIC、边缘AI芯片、光互联新架构、AI存算方案、Chiplet生态平台——多元化的技术路线正在并行演进。正如王晓阳所言:"Chiplet最大机会不是拆大算力Die,而是拆I/O、Memory功能。"
架构重建:从单芯片走向系统化推理
一个拆字,体现了Chiplet架构的核心价值,其关键在于将系统从"单一大Die"解耦为"最优子系统组合"。这种解耦带来的灵活性与复用性,正在重塑芯片设计的方法论。

工艺解耦是首要优势。计算核心可以采用最先进节点冲击性能极限,而IO、模拟、SerDes等对工艺不敏感的部分则可用成熟工艺控制成本。王晓阳指出:"由于制程限制,尤其是中国,先进工艺技术已成为瓶颈。因此,我们需要高效利用这些先进工艺,通过解耦公共限制,将对算力有重要需求的部分置于先进工艺之下,而将一些IO和互联模块作为供应商提供。"
内存解耦则提供了前所未有的配置灵活性。传统SOC一旦确定内存接口(HBM、LPDDR、DDR或GDDR),这一代产品便无法更改。若将内存接口置于外部的IO Die中,主芯片只需放置标准的UCIe接口,便可通过扩展方式适配不同内存形态。"同一代芯片在不同的应用场景和算力规模下都能实现复用,这种'内存解耦'的设计极大地增强了产品的灵活性和可配置性。"
独立迭代能力大幅提升了开发效率。在一个包含多个Chiplet的系统中,每一代产品迭代时,部分设计可以保持不变——沿用之前的CPU设计,只需针对AI部分进行迭代,而无需全面重新设计。这种模块化开发方式显著缩短了上市周期。
跨代复用则直接转化为投资回报率。同一IO Die可以适配多款Compute Die,一次投入、多产品线复用。正如王晓阳所言:"在不同的产品代中,我们能够使用相同的IO Die来适配多款芯片。在同一时期的芯片中,一个IO Die就可以解决不同的应用场景。"
封装技术的演进为Chiplet架构提供了物理基础。从传统2D基板互联,到2.5D CoWoS(通过硅中介层实现Die-Die水平高密度互联),再到3D Stacking(TSV直连、垂直堆叠)——带宽越来越高,延迟越来越低。奎芯科技的IO Die方案兼容2.5D/3D封装,以UCIe D2D实现2.5D级别的带宽与延迟,同时大幅缩小Interposer面积。
UCIe标准为什么能成?
在Chiplet互联标准的竞争中,UCIe(Universal Chiplet Interconnect Express)正快速成长为行业主流方向。
UCIe由Intel、AMD、Arm、TSMC、Qualcomm等巨头于2022年联合发起,从1.0版本到1.1版本,主要强调协议与标准之间的合规性、一致性要求,以及标准的可量产性和易落地性。进入2.0时代,UCIe更加注重规模化发展——支持Hub或Switch作为中心节点,连接5到8个甚至更多Chiplet,实现不同功能Chiplet的互联。这意味着协议需要定义更明确的可管理性(Manageability)、测试流程、容错机制等。
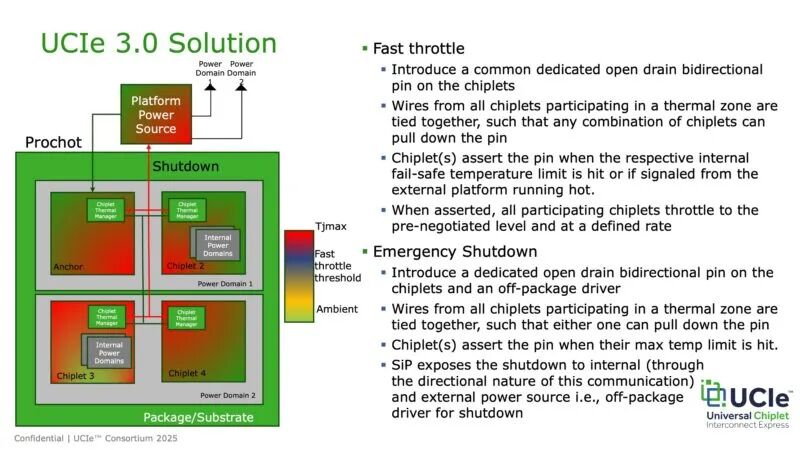
UCIe 3.0则进一步增强了系统控制能力,加入高速率的增强Sideband、MTP(Multi-Protocol Tunneling)以及Fast Throttle等功能,传输速度从32 GT/s提升到48甚至64 GT/s。
与UCIe形成对比的是其他互联标准:
-
NVLink-C2C:NVIDIA专有协议,是其生态系统护城河之一。从Grace Hopper首次商用,到Blackwell扩展至机架级,NVLink已形成垂直整合的封闭体系。虽有NVLink Fusion的局部开放,但其本质是吸引加入而非真正互联互通。
-
Infinity Fabric:AMD专有协议,成熟稳定,支持跨Die、跨Socket乃至机柜级互联,是EPYC、MI300系列的核心。
-
中国国标体系:HiPi联盟和CCITA(中国计算机互连技术联盟)推动的国标+团体标准双轨体系,GB/T 46280系列已于2026年3月实施,HiPi测试规范已采信入国标。
王晓阳对UCIe的前景持乐观态度:"UCIe的主导方更多体现其开放性,有Intel、AMD、TSMC等大厂主导,并且其落地速度相对较快,已有许多公司开始实施UCIe的实际案例和场景应用。"

奎芯在UCIe方案上的实践
作为国内领先的高速接口IP供应商,奎芯科技在UCIe领域的布局已进入收获期。
HBM IO Die方案是奎芯的首个落地产品。该方案将HBM从SOC中解耦,通过UCIe实现主芯片与HBM模组的互联。每个IO Die集成16个标准封装的UCIe IP module,单颗HBM3带宽达819.2GB/s,UCIe D2D距离支持2~25mm——这是UCIe目前可以达到的最远距离。
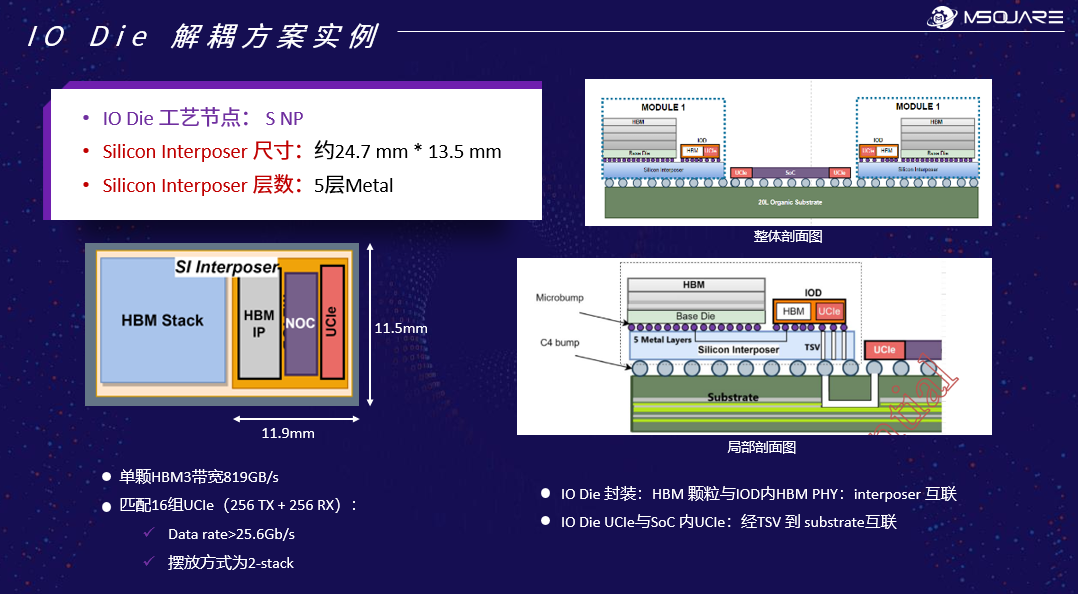
"使用我们的方案后,国内供应链就能够实现此方案,这是一件极具价值的事情。"王晓阳介绍道,"我们保守估计可以节省18%到20%的成本。这是因为HBM在解耦和温度脱敏后,整个供应链的国产化得以实现,同时避免了使用大尺寸interposer等组件。"
SSD扩展方案展示了UCIe在存储领域的创新应用。奎芯为一家企业级SSD客户开发了双主控扩展方案——通过UCIe连接两个SSD主控芯片,中间以IO Die桥接,同时集成PCIe接口与外部Host端相连。该方案已完成客户流片并量产出货,D2D与C2C模式均经生产验证。
LPDDR5X IO Die方案则瞄准AI推理芯片的内存瓶颈。传统方案中,SOC周边空间有限,难以放置大量LPDDR颗粒。奎芯的创新在于:让SOC外部不直接连接LPDDR memory,而是通过UCIe与IO Die相连,从而在单位面积下布局更多颗粒,将LPDDR容量增加30%左右。
更具前瞻性的是3D Memory + UCIe方案。奎芯与合作伙伴尝试将DRAM直接堆叠到基板上,通过集成控制逻辑的Base Die实现与SOC的UCIe标准互联。王晓阳透露:"最新的HBM4标准仍采用interposer互联,但有传言称英伟达正在研发采用UCIe或类似UCIe的方式进行互联。3D memory加UCIe的方案正逐渐成为一个很好的选择。"
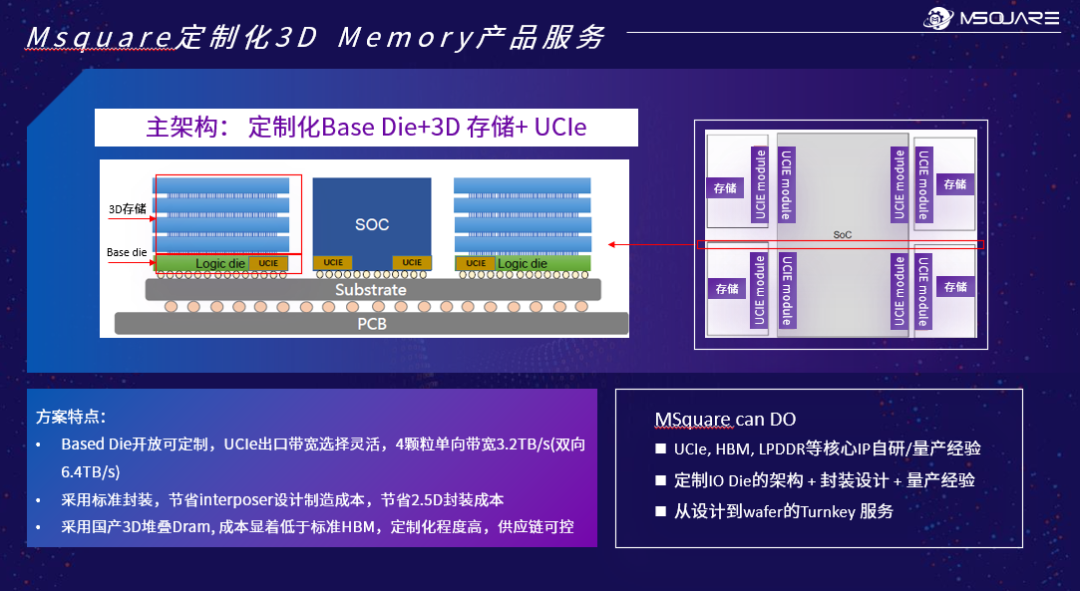
在CPO(Co-Packaged Optics)光互联领域,奎芯也在积极探索。与传统的Serdes方式不同,部分厂商开始使用UCIe实现光模块与计算芯片的连接。"UCIe的能效比较高且具有很强的复用性。如果UCIe成为Chiplet的主流接口,芯片中可以集成多个UCIe,当需要连接CPO时,只需添加一个带有UCIe的CPO即可。"
奎芯科技的UCIe IP测试数据同样亮眼:16Gbps版本连续7天测试误码率为零;32Gbps版本在高低温循环测试(-25°C→-40°C→85°C→25°C)下连续72小时误码率为零。眼图测试显示,16Gbps@25mm距离下眼宽达50ps(0.8UI),32Gbps@25mm距离下眼宽达23.4ps(0.748UI)。
Chiplet的未来在于模块化战略与开放生态
站在产业变革的十字路口,Chiplet与ASIC定制的结合正在开启一个新的时代。
王晓阳阐释了系统级组织的本质:"芯片本质上是一种工业产品,而任何工业产品其生产过程都需要细致的分工。以汽车为例,早期的汽车可能由单一厂家完成所有环节的制造,而如今的汽车则是通过玻璃厂、轮胎厂、发动机厂等不同厂家分工合作生产出来的。芯片的制造过程与之类似。"
这种分工的深化,意味着"未来的AI推理,不再是把模型丢进一颗大芯片,而是把请求分配到一套系统"。互联技术正是这套系统的"神经系统"——它决定了数据能否高效传递、延迟能否足够低、不同模块能否协同工作。
对于国内AI芯片企业而言,Chiplet架构究竟是"可选项"还是"必选项"?王晓阳给出了审慎的判断:"在需要大尺度和高算力的情况下,尤其是在资源受限的场景下,选择Chiplet是必经之路。如果不采取这种做法,设计的性能很可能会落后于竞争对手。"
当然,挑战依然存在。最大的门槛在于生态——从互联标准协议,到工程化落地,再到测试和整个生态,这过程中有很多细节问题需要逐渐成熟和完善。
关于国产标准与UCIe的关系,奎芯科技持开放兼容态度。王晓阳认为国产标准应当在UCIe体系上作为一个超集存在,而不是作为并行的体系。这样做可以避免国内IP厂商和芯片厂商在开发时面临额外的负担。没有必要开发两套标准,可以重度兼容UCIe标准或稍微有一些差别是更为明智的选择。
展望未来,奎芯科技将继续深耕三个方向:IP侧,持续优化高速互联技术;Chiplet侧,打造可复用、可扩展的模块化产品;系统侧,构建开放可定制的平台能力。
从IP到Chiplet,从单芯片到系统化推理,从封闭生态到开放标准——半导体产业正在经历一场深刻的架构革命。在这场革命中,互联技术不再只是芯片设计的"配角",而是重构算力未来的核心变量。奎芯科技等企业的积极布局,正在为全球Chiplet生态贡献独特的中国智慧。











评论区
登录后即可参与讨论
立即登录