别吹 PPT 了!到底谁能把 AI 落地到桌面?
最近的摩尔线程发布会上,摩尔线程创始人、董事长兼首席执行官张建中是这么形容AI时代遭遇的算力挑战的:“很少有人能准确预测下个月token的需求量是多少。”回看2024-2026年初这短短2年时间,中国的日均token消耗量就上涨了1800倍,2025年中日均token消耗量30万亿,二道了2026年初仅OpenClaw这一个应用的日均token消耗就达到了140万亿... 在智能体AI的时代背景下
关于「摩尔线程」的技术文章、设计资料与工程师讨论,持续更新。

最近的摩尔线程发布会上,摩尔线程创始人、董事长兼首席执行官张建中是这么形容AI时代遭遇的算力挑战的:“很少有人能准确预测下个月token的需求量是多少。”回看2024-2026年初这短短2年时间,中国的日均token消耗量就上涨了1800倍,2025年中日均token消耗量30万亿,二道了2026年初仅OpenClaw这一个应用的日均token消耗就达到了140万亿... 在智能体AI的时代背景下

5月18日,摩尔线程举办2026产品发布会,宣布全面深化端侧AI战略布局,并重磅发布首款面向家庭场景的消费级产品——MTT AICUBE(以下简称:AICUBE)。为满足词元(Token)时代爆发的端侧算力需求,摩尔线程立足自研“长江”智能SoC,实现了算力从云端智算集群向边缘和终端的延伸,赋能更为普惠的家庭智能场景。 作为该端侧战略的关键落子,AICUBE重新定义了家庭智能设备的形态与体验。它不
5月18日,摩尔线程在北京举办主题为“词元时代,万物智能”的产品发布会。在Agentic AI驱动词元(Token)需求呈指数级跃升的关键节点,万物智能处于爆发前夜,算力的基石作用愈发关键。 摩尔线程在此次盛会上全方位展示了其作为智算底座的战略纵深,全面展示了“云-边-端”全栈智算矩阵:从万卡级规模的夸娥智算集群,到自研“长江”SoC驱动的智能终端MTT AICUBE和MTT AIBOOK;从数字

5月18日,摩尔线程在北京举办主题为“词元时代,万物智能”的产品发布会。在Agentic AI驱动词元(Token)需求呈指数级跃升的关键节点,万物智能处于爆发前夜,算力的基石作用愈发关键。 摩尔线程在此次盛会上全方位展示了其作为智算底座的战略纵深,全面展示了“云-边-端”全栈智算矩阵:从万卡级规模的夸娥智算集群,到自研“长江”SoC驱动的智能终端MTT AICUBE和MTT AIBOOK;从数字
5月16日,在杭州市具身智能创新发展大会上,国家人工智能应用中试基地(具身智能)(简称:国家具身智能应用中试基地)正式揭牌,摩尔线程成为共建合伙人,并担任其产业委员会委员。 摩尔线程成为国家具身智能应用中试基地共建合伙人 为进一步深化合作,摩尔线程与国家具身智能应用中试基地签署战略合作协议,并成立“具身智能算力与仿真联合实验室”。双方将充分发挥“全功能GPU算力底座”与“国家级战略平台”的优势,以
AI芯片目前是国内半导体被卡脖子最严重的领域之一,但它同时也是国产芯片机遇最明确的,而且这一次的逆袭会来得很快,10年时间就能完成全面国产替代。 根据摩根斯坦利公布的一项研究结果,国产AI芯片自给率(主要是GPU类型)在2021年才只有10%,但是发展速度非常快,今年就能达到41%,四年时间份额3倍提升。 接下来的5年中,AI芯片的自给率还会快速提升,到2030年将提升到86%,意味着进口的所有A
第二届浦江AI学术年会期间,上海人工智能实验室(上海AI实验室)联合多家科研机构、运营商和大模型企业,共同发起AI全环节软硬件验证合作计划,并拟于今年发布AI全环节软硬件验证平台(验证平台),分场景建设自主AI软硬件能力验证环境,以破解AI软硬件各层次组合复杂、选型困难、全环节评测标准不统一等问题。 5月14日,上海AI实验室DeepLink团队组织召开首次验证平台推进交流会,并牵头成立验证平台工
5月13日,以无锡市工业和信息化局、无锡市发展和改革委员会、无锡市数据局及无锡市惠山区人民政府为指导单位,由摩尔线程主办的无锡具身智能产业伙伴思享沙龙成功举行。活动现场,摩尔线程与首批16家联合共建单位签署合作备忘录,正式启动摩尔线程(无锡)工业具身智能创新中心,以生态合力加速具身智能的产业应用。 本次活动,政府、产业及学界嘉宾齐聚一堂,深入探讨具身智能创新路径。无锡市工业和信息化局、无锡市发展和
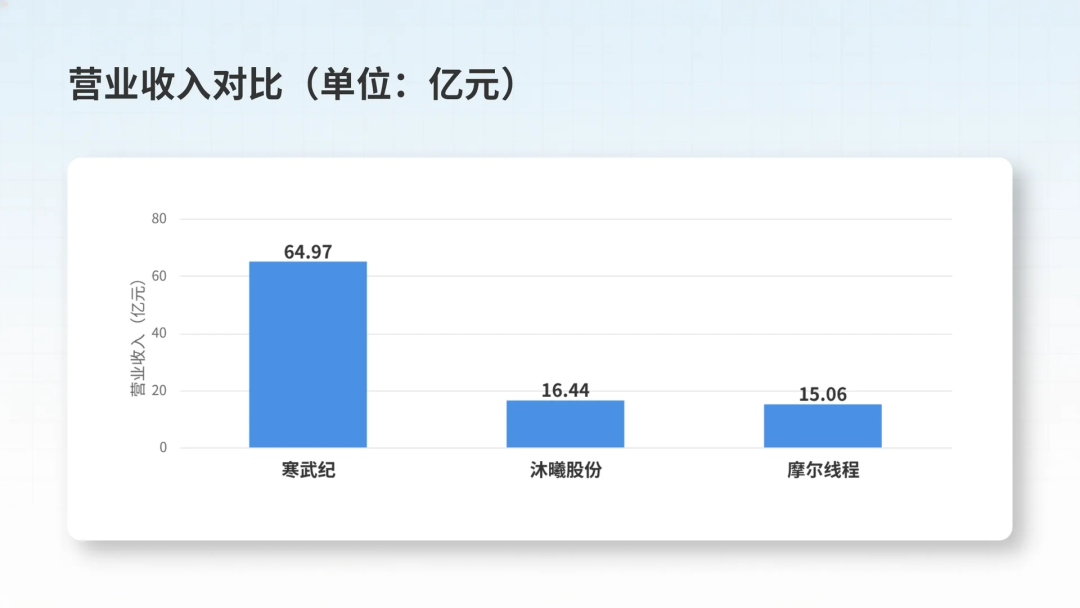
博主整理了A股上市的三家国产GPU公司寒武纪、沐曦股份、摩尔线程的营收和经营数据。 营收方面: 寒武纪2025年全年营收64.97亿元,断层领先。 沐曦股份和摩尔线程营收分别是16.44亿和15.06亿,收入接近。 利润方面: 寒武纪扣非净利润为17.7亿元,也是唯一利润为正的公司。 而沐曦和摩尔仍处于亏损阶段,沐曦亏损8.3亿,摩尔亏损10.88亿。 毛利率: 三

5月10日,由摩尔线程与SGLang社区联合主办的“MUSA开源技术沙龙|SGLang × MUSA Meetup”在北京成功举行。 本次Meetup不仅集结了SGLang核心开发成员,并邀请到TileLang、Triton、Mooncake**等开源社区的顶尖技术专家,吸引了近百位前沿开发者到场参与。各方围绕大模型推理引擎、算子编译、工程优化与生态共建**等核心议题,展开了一场高密度、深层次的技

近日,摩尔线程与光轮智能达成战略合作。双方将依托摩尔线程全功能GPU与夸娥(KUAE)智算集群,结合光轮智能“求解—测量—生成”三位一体全栈自研仿真平台,联合打造高置信度仿真数据合成方案,以国产算力与仿真算法的深度融合,为具身智能发展夯实自主可控的基础设施。 本次合作直击具身智能行业的核心痛点:真机数据采集长期面临物理数据稀缺、成本高昂、场景覆盖不足、复杂物理过程难以稳定复现等难题。为跨越数据鸿沟

5月7日至9日,2026移动云大会在苏州举行,聚焦算网融合、人工智能、Token应用与产业落地,汇聚政、产、学、研、用各界嘉宾。作为中国移动投资的国产GPU头部企业及核心生态伙伴,摩尔线程携全栈自主算力解决方案参展,并深度参与新品路演、生态发布、圆桌对话等环节,为智能经济开拓发展新空间。 “新品路演+分论坛”重磅发声, 共筑Token与智算生态 5月7日,在新品路演环节,摩尔线程解决方案总监孙强分

5月6日,一则报道引发市场高度关注:国家集成电路产业投资基金(简称“国家大基金”)正在洽谈领投DeepSeek首轮融资,估值约450亿美元。 几周前,这一数字还停留在200亿美元左右,短短数周翻倍有余,市场用真金白银给出了答案。 国家大基金向来被视为中国半导体产业的“国家队”,重点投向材料、设备、芯片制造等产业链,此前从未公开投资任何一家大语言模型公司。一旦本轮投资落地,这将是大基金首次公开注资本

证监会官网显示,昆仑芯(北京)科技股份有限公司于2026年5月7日正式启动科创板上市辅导,中国国际金融担任辅导机构。这是继2026年1月公司以保密形式向港交所递交主板上市申请后,资本运作的又一关键步骤,标志着其"A+H"两地上市计划全面铺开。 百度控股57.67%,估值或处行业头部区间 辅导备案报告显示,昆仑芯成立于2011年6月10日,注册资本41,237.1134万元,法定代表人为欧阳剑。公
导语 DeepSeek正进行首轮融资,金额高达500亿元人民币,其中创始人梁文锋个人或出资200亿。若顺利完成将刷新中国AI公司融资纪录,其估值也将飙升至515亿美元,重塑全球大模型产业格局。 更值得关注的是,DeepSeek V4.1或于6月登场,主打MCP协议适配与多模态能力。而大洋彼岸OpenAI发布GPT-5.5系列的同时,Anthropic年化收入已突破440亿美元。 在多模态理解、长程
近日,摩尔线程依托旗舰级AI训推一体智算卡MTT S5000与自研MUSA软件栈,基于SGLang 开源推理框架,成功完成DeepSeek-V4的完整运行验证。该成果表明,面向新一代MoE大模型,摩尔线程已构建起从硬件架构核心计算引擎承接、热点算子支持**,**再到端到端部署验证的系统化适配链路,验证了国产GPU平台对前沿大模型“框架级兼容、开箱即落地”的承载实力及工程化落地能力。 随着大模型架构
4月24日,DeepSeek-V4预览版正式发布。DeepSeek自V3起便以高频迭代著称,V4的到来只是节奏延续。 但真正引发行业震动的是:华为昇腾、寒武纪、海光信息、摩尔线程、沐曦股份、百度昆仑芯、阿里平头哥、天数智芯等八家国产AI芯片厂商,在模型发布的同一天,集体完成了全链路适配与性能优化。 (图源:DeepSeek) Day 0 意味着什么? Day 0适配,是指在大模型正式发布当天,算
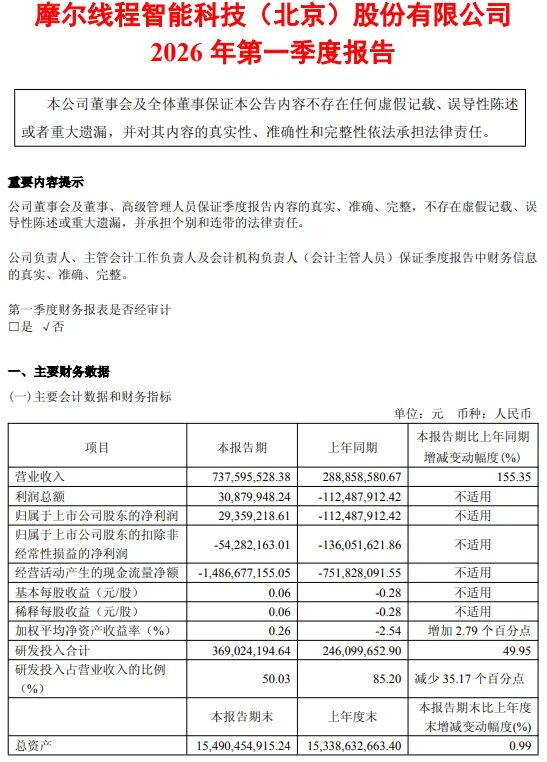
4月26日晚间,国产GPU龙头摩尔线程(688795.SH)披露上市以来首份年报及一季报,向市场交出了一份颇具分量的成绩单。 财报显示,2026年第一季度,摩尔线程实现营收7.38亿元,同比增长155.35%;归母净利润2935.92万元,同比增加1.42亿元,实现同比扭亏为盈;归母扣非净利润亏损0.54亿元,亏损同比收窄60.10%。 这是摩尔线程自2025年12月5日登陆科创板以来,首次在单
近日,中国移动自主研发的九天35B通用大模型即将正式发布。作为中国移动重要的生态合作伙伴及 “AI 能力联合舰队” 的核心算力成员,摩尔线程基于旗舰级AI训推一体全功能GPU MTT S5000,依托成熟的MUSA软件栈与高性能算子优化,已率先完成九天35B模型的全流程适配与推理验证。这不仅是国产GPU与央企大模型的深度协同,更意味着国产AI算力已具备支撑行业级大模型规模化落地的核心能力。 软硬协
4月24日,摩尔线程联合北京智源人工智能研究院,基于旗舰级AI训推一体智算卡MTT S5000与FlagOS全栈软件体系,**完成DeepSeek-V4系列两款模型推理“Day-0”适配,并在魔搭社区正式发布Pro和Flash两个版本的镜像**,为开发者与行业用户带来开箱即用的国产化部署方案。 ▼ DeepSeek-V4-Pro镜像地址: https://modelscope.cn/models/