两个月前,我们发布了 Xiaomi-Robotics-0 模型,并深度分享了其在复杂工业场景中的实战经验。模型发布首月就在 HuggingFace 全球 VLA 模型下载榜斩获第六名。
看到 Xiaomi-Robotics-0 在全球开发者手中释放潜力,我们深受鼓舞。为了让其真正成为“开箱即用”的生产力利器,今天我们给大家带来新的能力演示并正式发布 Xiaomi-Robotics-0 真机后训练(Post-training)全流程。
01
加速进化仅需20小时
基于预训练基座,我们仅利用 20 小时的任务数据进行真机后训练,便让 Xiaomi-Robotics-0 掌握了“将耳机收纳进耳机盒”这一高难度动作,并能够连续丝滑地完成多个耳机的收纳。
依次完成不同颜色耳机收纳
该任务涉及两大核心挑战:
-
耳机与槽位间公差极小,模型必须达到亚毫米级的空间感知精度,才能完成精准对位。
-
耳机与盒体表面粗糙度最低至 Ra0.03μm,极易在触碰过程发生位移,模型必须能快速修正动作偏差,避免装配失败。
多视角展示装配细节
02
三重策略破局“偷懒效应”
为实现机器人动作的无缝衔接,我们在部署阶段采用了异步推理(Asynchronous Execution)方案:在执行当前轨迹时,同步推理下一步动作。为了确保模型前后两次推理生成的动作轨迹不发生突变,我们在训练中引入了动作前缀(Action Prefixing)。这如同为接力赛选手提供了“助跑区”,让新动作能够从既有轨迹中自然生长,从而实现动作流的平滑切换。
在引入 Action Prefixing 后,一个行业通病——“偷懒效应”随之而来:模型容易过度依赖动作惯性,而选择性地忽视实时的视觉反馈。为此,我们引入了三项关键技术,平衡动作的连贯性与响应的灵敏度:
a. 自适应加权机制 (Adaptive Loss Re-weighting):根据模型预测值与真实轨迹的偏差,动态调整 Loss 权重,强迫模型在关键误差处“刻苦补课”
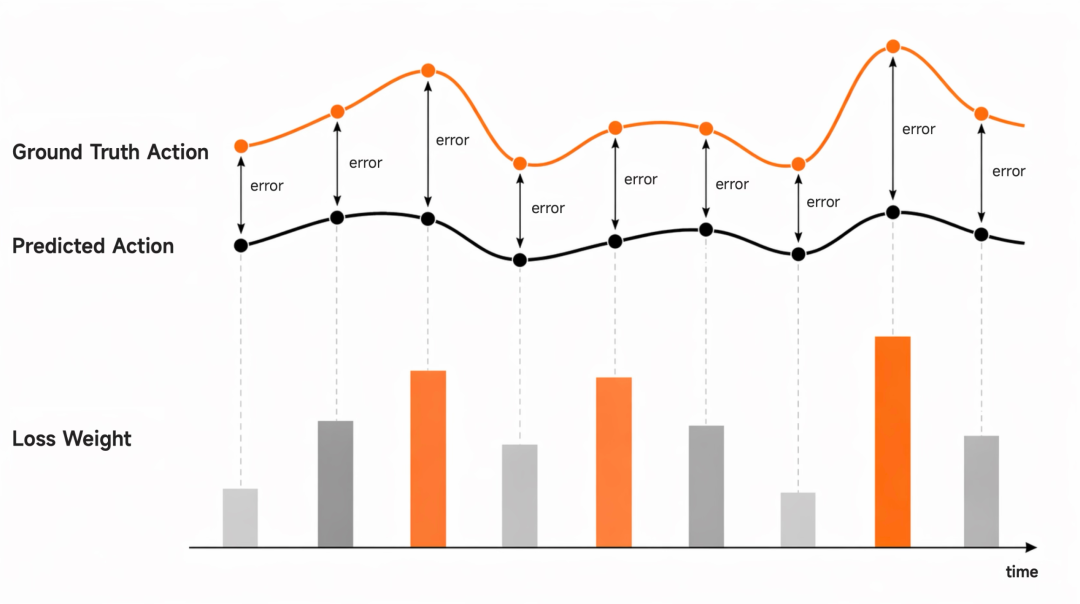
自适应加权机制 (Adaptive Loss Re-weighting)
b. Λ 型掩码 (Λ-Shape Attention Mask):通过特殊的注意力机制,确保模型在参考前段动作末尾的同时,保持对当前视觉信号的高度专注,防止陷入单纯的“路径依赖”。
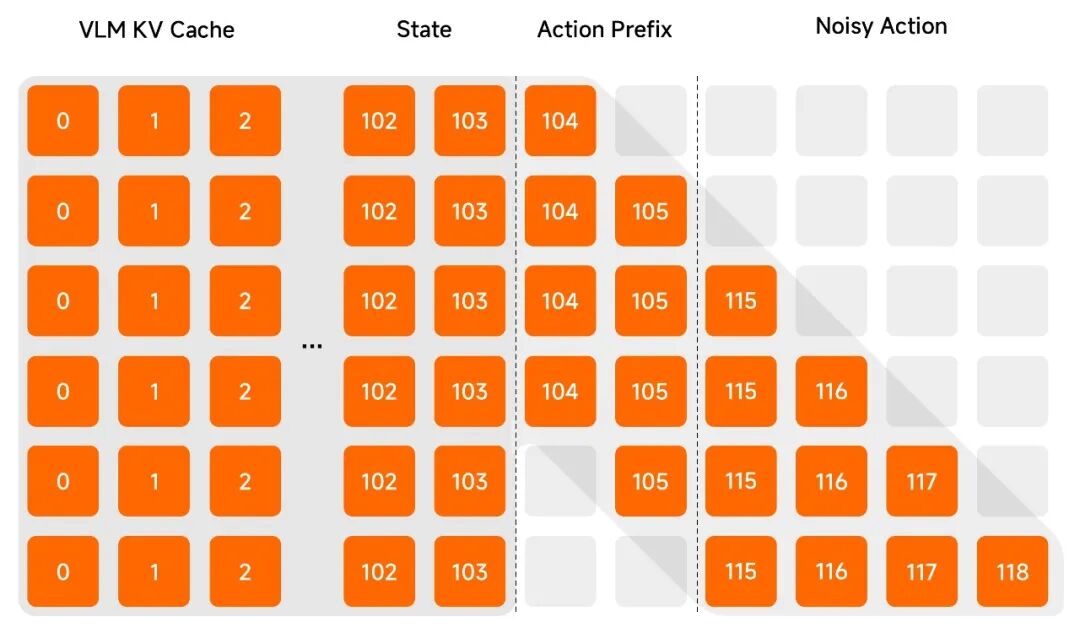
Λ 型掩码 (Λ-Shape Attention Mask)
c. 前缀动作随机遮蔽 (Random Masking):在训练中对既有的动作前缀进行随机 Dropout,倒逼模型深入挖掘摄像头画面与传感器信号,而非盲目跟从动作惯性。
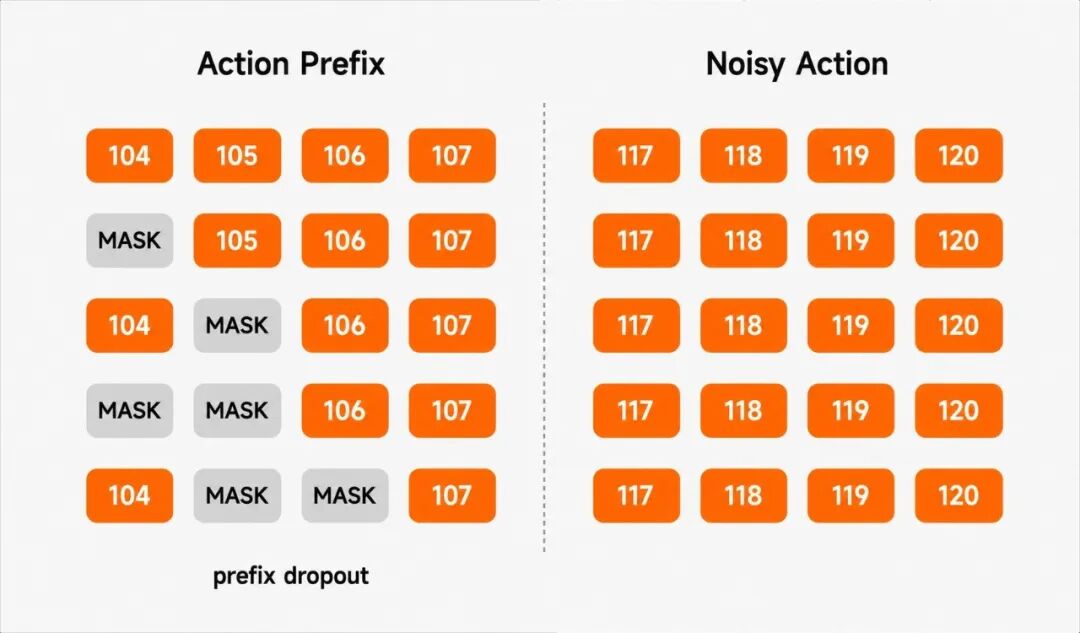
前缀动作随机遮蔽 (Random Masking)
03
开源与资源
真机后训练是打通 VLA 模型迈向落地 “最后一公里” 的关键。我们选择将这一套完整的数据处理、训练方法、推理代码全面开放,正是希望通过开源的力量,降低机器人智能化的技术门槛。
为此,我们还专门搭建了机器人技术发布与交流平台,欢迎广大开发者与生态伙伴前往小米机器人官方网站分享经验、交流探讨、共同进步。
未来,小米也将持续在多样化的硬件本体上开展跨本体通用能力的部署、测试与验证,不断迭代优化模型性能,全面提升具身智能的泛化能力与落地效果。
我们也真诚鼓励所有开发者,在不同硬件本体上积极开展模型部署、验证与创新实践,充分释放开源技术的价值。我们期待看到更多开发者利用 Xiaomi-Robotics-0,在各式各样的场景中,通过极低的真机后训练成本,训练出属于自己的 “专属机器人”,让我们一起推动机器人走向具身智能的未来。
-
技术官网:
-
技术报告:
-
项目网站:
https://robotics.xiaomi.com/xiaomi-robotics-0.html
-
模型权重:
-
开源代码:
04
About Xiaomi Robotics
探索物理智能的边界,我们从不止步。
欢迎加入,一起在具身智能领域,触碰未来。








评论区
登录后即可参与讨论
立即登录