NVLink是一种专有系统互连硬件,可促进多个 Nvidia GPU 和支持CPU之间的一致数据和控制传输。
概述
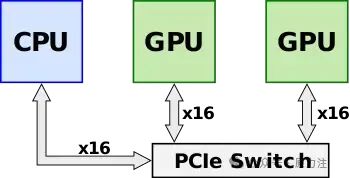
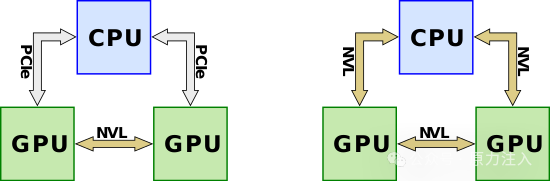
NVLink 于 2014 年初发布,旨在作为 PCI Express 的替代解决方案,具有更高的带宽和附加功能(例如共享内存),专门设计用于与 Nvidia 自己的多 GPU 系统的 GPU ISA 兼容。在推出 NVLink 和 Pascal(例如Kepler)之前,多个 Nvidia 的 GPU 会位于共享的PCIe总线上。尽管已经可以使用 Nvidia 的统一虚拟寻址通过PCIe总线实现直接的 GPU-GPU 传输和访问,但随着数据集的大小不断增长,总线成为越来越大的系统瓶颈。通过使用PCIe 交换机,吞吐量可以进一步提高。
链接
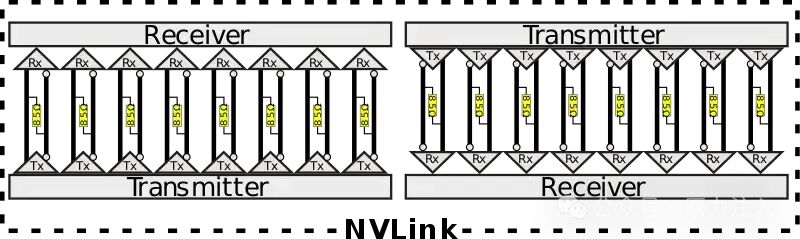
NVLink 通道称为 Brick(或NVLink Brick)。单个 NVLink 是双向接口,每个方向包含 8 个差分对,总共 32 条线。这些线是直流耦合的,使用带有嵌入式时钟的 85Ω 差分终端。为了简化路由,NVLink 支持通道反转和通道极性,这意味着两个设备之间的物理通道顺序及其极性可以反转。
包
单个 NVLink 数据包的范围从 1 到 18 个 flit。每个 flit 为 128 位,允许使用单个 header flit 和 16 个 payload flit 传输 256 字节,峰值效率为 94.12%,使用单个 header flit 和 4 个数据 payload flit 传输 64 字节,单向效率为 80%。在双向流量中,效率分别略微降低至 88.9% 和 66.7%。
数据包至少包含一个标头,以及可选的地址扩展 (AE) 数据块、字节启用 (BE) 数据块和最多 16 个数据有效负载数据块。典型的事务至少包含请求和响应,而发布的操作不需要响应。
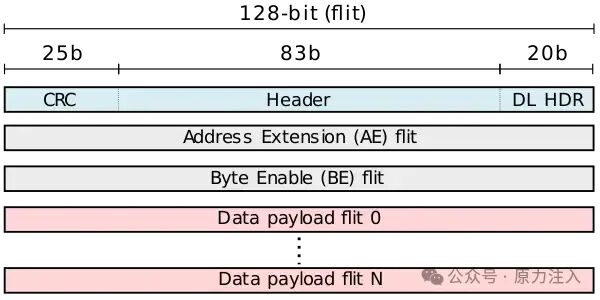
头部 flit
Header flit 为 128 位。它包含 25 位 CRC 字段(如下所述)、83 位事务字段和 20 位数据链路 (DL) 层字段。事务字段包括请求类型、地址、流控制位和标签标识符。数据链路字段包括数据包长度、应用程序编号标签和确认标识符等内容。
地址扩展 (AE) 数据块保留用于相当静态的位,并且通常仅传输变化的位。
纠错
Nvidia 指定错误率为 1/1×10 12。错误检测通过 25 位循环冗余校验头字段完成。接收器负责将数据保存在重放缓冲区中。传输的数据包按顺序排列,如果 CRC 正确,则将确认发送回发送端。超时后丢失的确认将启动回复序列,重新传输所有后续数据包。
CRC 字段由 25 位组成,允许最大数据包最多有 5 个随机位出错,或者,对于差分对突发,它可以支持最多 25 个连续位错误。CRC 实际上是根据报头和前一个有效载荷计算的,因此无需为数据有效载荷设置单独的 CRC 字段。请注意,由于报头还包含数据包长度,因此它也包含在 CRC 校验中。
例如,考虑两个数据有效载荷(32 字节)flit 及其附带的标头序列。下一个数据包将对当前标头以及来自前一个事务的两个数据有效载荷进行 CRC 校验。如果这是第一个事务,则 CRC 假定前一个事务是NULL事务。
数据速率
| NVLink 1.0 | NVLink 2.0 | NVlink 3.0 | NVlink 4.0 | |
|---|---|---|---|---|
| 信令速率 | 20 GT/秒 | 25 GT/秒 | 50 GT/秒 | 100 GT/秒 |
| 车道/连接 | 8 | 8 | 4 | 2 |
| 评分/链接 | 20 GB/秒 | 25 GB/秒 | 25 GB/秒 | 25 GB/秒 |
| 双向带宽/链路 | 40 GB/秒 | 50 GB/秒 | 50 GB/秒 | 50 GB/秒 |
| 链接/芯片 | 4(P100) | 6(V100) | 12(A100) | 18(H100) |
| BiDir BW/芯片 | 160 GB/秒(P100) | 300 GB/秒 (V100) | 600 GB/秒(A100) | 900 GB/秒 (H100) |
GT/s — Giga Transmission per second (千兆传输/秒),即每一秒内传输的次数。
与 PCIE 速度对比
| 版本 | 推出 | Line 编码 | 每通道传输率[i] | 带宽(每个方向)[i] |
|---|---|---|---|---|
| x1 | x2 | x4 | x8 | x16 |
| 1.0 | 2003 | NRZ | 8b/10b | 2.5 GT/s |
| 2.0 | 2007 | 5.0 GT/s | 0.500GB/s | 1.000 GB/s |
| 3.0 | 2010 | 128b/130b | 8.0 GT/s | 0.985GB/s |
| 4.0 | 2017 | 16.0 GT/s | 1.969 GB/s | 3.938 GB/s |
| 5.0 | 2019 | 32.0 GT/s[ii] | 3.938GB/s | 7.877 GB/s |
| 6.0 | 2021 | PAM-4FEC | 1b/1b242B/256B FLIT | 64.0 GT/s32.0 GBd |
| 7.0 | 2025(预计) | 128.0 GT/s64.0 GBd | 15.125GB/s | 30.250GB/s |
- ^ 跳转到:每条通道(lane)都是全双工通道。
- ^ 出于技术可行性,最初也考虑过25.0 GT/s
以PCIe 2.0为例,每秒5GT(Gigatransfer)原始数据传输率,编码方式为8b/10b(每10个比特只有8个有效数据),即有效带宽为4Gb/s = 500MByte/s。
参考:
NVLink 1.0
NVLink 1.0 最初是在基于Pascal微架构的P100 GPGPU中引入的。除了能够从 CPU 端访问系统内存外, P100还配备了自己的HBM内存。P100 有四个 NVLink,支持高达 20 GB/s 的双向带宽,即 40 GB/s,总聚合带宽为 160 GB/s。在最基本的配置中,除了连接到 CPU 以访问系统 DRAM 的 PCIe 通道外,所有四个链路都连接在两个 GPU 之间,以实现 160 GB/s 的 GPU-GPU带宽。
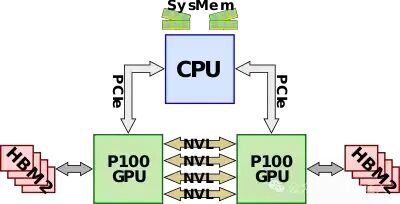
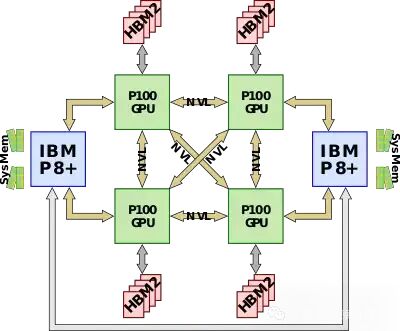
第一款原生支持 NVLink 的 CPU 是 IBM POWER8+,它允许 NVLink 互连扩展到 CPU,取代速度较慢的 PCIe 链路。由于 P100 只有四个 NVLink,因此可以使用来自每个 GPU 的单个链路将 CPU 链接到 GPU。典型的全配置节点由四个 P100 GPU 和两个 Power CPU 组成。四个 GPU 完全相互连接,第四个链路连接到 CPU。
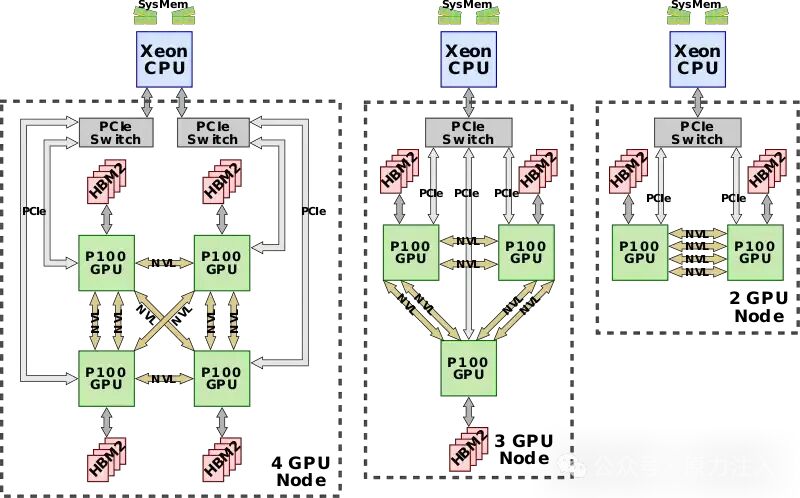
由于基于Intel的 CPU 不支持 NVLink(并且不太可能永远支持它们),因此可能存在从两个到四个 P100 GPU 的几种变化。在每种配置中,GPU 都完全相互连接,每两个 GPU 都连接到一个直接连接到 CPU 的PCIe 交换机。无论配置如何,每个链接都是 40 GB/s 双向的,并且可以聚合以在任何两个 GPU 之间提供更高的带宽,它们之间使用的链接越多。
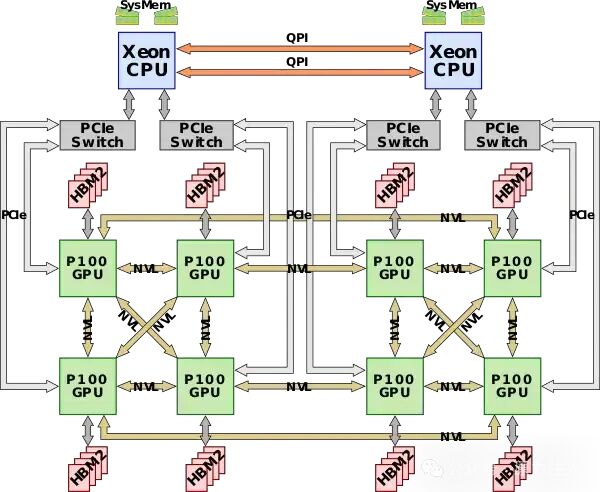
DGX-1 配置
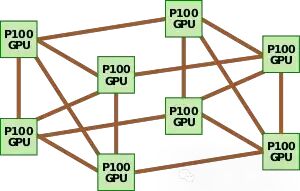
2017 年,Nvidia 推出了充分利用 NVLink 的 DGX-1 系统。DGX-1 由八个 Tesla P100 GPU 以及双插槽Xeon CPU 组成,这些 GPU 以混合立方体网格 NVLink 网络拓扑连接。两个 Xeon 通过英特尔的QPI相互通信,而 GPU 通过 NVLink 通信。
NVLink 2.0
NVLink 2.0 最早是在基于Volta微架构的V100 GPGPU和IBM的POWER9中推出的。Nvidia 增加了 CPU 主控支持,允许 GPU 和 CPU 在平面地址空间中访问彼此的内存(即直接加载和存储)。平面地址空间通过新的地址转换服务得到支持。此外,还为 CPU 和 GPU 添加了对原子操作的本机支持。随着平面地址空间的增加,NVLink 现在具有缓存一致性支持,允许 CPU 高效缓存 GPU 内存,显著改善延迟并提高性能。NVLink 2.0 将信令速率提高到每线 25 Gbps(25 GT/s),实现 50 GB/s 双向带宽。V100 还将片上 NVLink 的数量增加到 6 个,总聚合带宽为 300 GB/s。值得注意的是,还添加了额外的省电功能,例如在空闲期间停用通道。
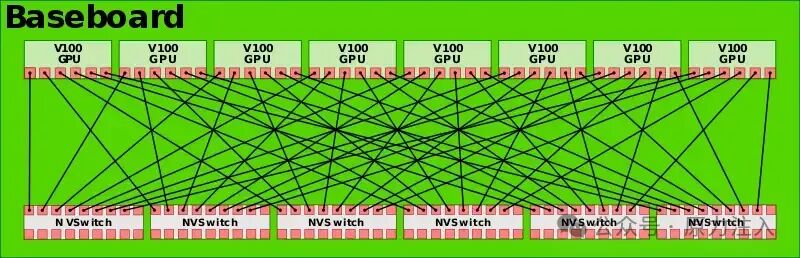
NVLink 2.0 是随第二代DGX-1推出的,但完整的拓扑结构变化发生在DGX-2中。Nvidia 还随 DGX-2 推出了NVSwitch,这是一款 18 NVLink 端口交换机。这款 20 亿晶体管交换机可以将流量从 9 个端口路由到其他 9 个端口中的任何一个。每个端口 50 GB/s,交换机总共能够提供 900 GB/s 的带宽。
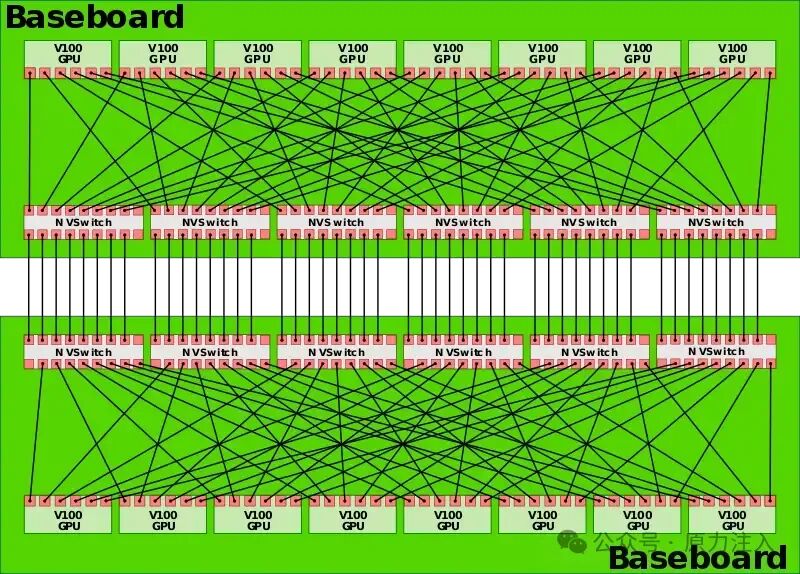
对于 DGX-2,Nvidia 使用六个NVSwitches将八个 GPU 中的每一个与同一底板上的所有其他七个 GPU 完全连接。
然后将两个底板相互连接,以将所有 16 个 GPU 完全连接在一起。
NVLink 3.0
NVLink 3.0 首次在基于Ampere微架构的A100 GPGPU中推出。NVLink 3.0 使用 50 Gbps 信号速率
参考
- IEEE HotChips 34 (HC28), 2022
- IEEE HotChips 30 (HC28), 2018
- IEEE HotChips 29 (HC29), 2017
- IEEE HotChips 28 (HC28), 2016








评论区
登录后即可参与讨论
立即登录