最近的摩尔线程发布会上,摩尔线程创始人、董事长兼首席执行官张建中是这么形容AI时代遭遇的算力挑战的:“很少有人能准确预测下个月token的需求量是多少。”回看2024-2026年初这短短2年时间,中国的日均token消耗量就上涨了1800倍,2025年中日均token消耗量30万亿,二道了2026年初仅OpenClaw这一个应用的日均token消耗就达到了140万亿...
在智能体AI的时代背景下,要满足如此超出人类预期的AI技术发展需求,无疑要求AI技术全栈参与者努力;尤其是底层摩尔线程这样的AI基础设施供应商,从端到云的算力和平台供给。于是也就有了这次发布的诸多产品与技术。

关注这两天新闻的读者应该知道,摩尔线程在本场发布会上发布或更新了6大板块的产品和技术:夸娥智算集群——最直接的AI基础设施、小麦智能体——一款“全域智能体”、MTT AICUBE——一款家庭AI中枢设备、MTT AIBOOK——AI笔记本、MT Lambda——具身智能训练仿真平台,以及MUSA生态更新。
在我们看来,本次发布会的高光关键词有两个:智能体AI、具身智能。前者贯穿了此次发布或更新的大部分产品和技术——不说小麦智能体本身,AICUBE和AIBOOK的高阶价值都在智能体身上,连MUSA开发都能借助AI agent来编程;而后者作为这届发布会的高潮,是真正能够体现摩尔线程的技术和市场能力的...
那么本文也依托这两个关键词展开,期望从中窥见摩尔线程及以其为代表的国产AI技术如今所处的发展阶段。本文篇幅较长,可点击感兴趣的内容阅读:
智能体AI:
* Part 1 AICUBE与小麦智能体;
* Part 2 AIBOOK及其软件更新;
具身智能:
* Part 3 夸娥智算集群 & MT Lambda;
MUSA:
* Part 4 MUSA生态更新与结尾;
Part 1 把握住个人智能体AI入口
在智能体AI(Agentic AI)发展到一定阶段后,OpenClaw作为杀手级应用顺势而生,继而更多更成熟的商业“龙虾”问世。张建中援引的数据显示,目前全球token消耗场景分布中,48%被AI智能体所占据。摩尔线程这次发布的名为“小麦”的“全域智能体”也是智能体AI走向高级阶段的产物。摩尔线程定义“全域智能体”为“服务工作、生活,7x24小时在线,没有地理和时域空间限制的智能体”。
小麦作为智能体,基于摩尔线程自研的MTClaw开源框架:自然同样具备策略一致的情景感知决策能力、会做长上下文历史检索、支持跨端协同和端云一体,另外就是具备情感语义分析和多模态情绪识别能力,而且能够做意图预测和自主的任务编排——也就是现在很流行的“主动”服务能力。
张建中说小麦智能体具备“事办得全”、“事办得好”、“事办得快”这三大特点。“事办得全”是指在MTT AIOS操作系统生态下有36+应用控制能力、具备60+复杂操作技能、接通了90+ CLI工具;“事办得好”则表示,能藉由“二维拓扑记忆系统”来认不同的人,融合了短时+长时记忆,并且善于归纳总结;“事办得快”体现在执行速度上,基于MTClaw开源框架,高频工具调用成功率超过95%,并且任务执行具备低延迟的特点...

基于摩尔线程自家推出的智能体能力Benchmark评测体系,小麦智能体相比OpenClaw和“友商智能体”在记忆能力、性能和执行成功率、生活场景能力、任务编排能力、安全行动与隐私保护、编码及代码场景能力上都有着相当不错的优势。感兴趣的读者也可以去关注这套基准测试体系——其中有不少测试子项,涵盖行业测试及摩尔线程的自研题集,有机会成为行业标准。
从现场的呈现和demo来看,小麦智能体是面向一般消费用户、可直接语音交互的AI助手应用:具备可自定义的人格、有记忆能力、会认人、会执行复杂任务,而且能基于情境提供主动服务。
不过我们认为,其职能或许不止于此,当面向开发者和企业/行业用户时,小麦更像是MUSA生态及摩尔线程AI技术栈之上,摩尔线程官方的智能体AI应用层参考设计——不要忘记,摩尔线程作为芯片企业的一重身份——这实际上也是有能力在软件上充分投入的加速器芯片企业都会做的事,NVIDIA在AI软件栈上层也做了不少应用。

但和NVIDIA有所不同的是,摩尔线程面向个人用户时,也兼任OEM终端设备制造商的角色。这就决定了小麦智能体可存在于摩尔线程的整机设备中,也存在着更明确的应用场景。比如说这次发布的MTT AICUBE。
前不久Intel的AI NAS解决方案峰会报道中,我们就提到Intel可能是期望借助AI NAS这一设备形态来掌控个人智能体AI入口。而智能体AI入口或中枢,实际上是所有消费电子市场参与者都想要抢占先机的:在这个入口或中枢尚未完全成型之前,手机、PC、可穿戴设备、智能家居、边缘AI盒子,乃至某种新形态的设备,都可能成为候选。
在我们看来,这可能也是MTT AICUBE这款小立方体设备的目标,或至少是目标之一。张建中在发布会上说,AICUBE是AI Agent(小麦)+ AI PC + AI NAS——它某种程度上与Intel泛化了的AI NAS及类似NVIDIA DGX Spark这样的边缘AI设备有着相似的应用场景,只不过做到了更大程度的开箱即用,比如小麦智能体就是个开箱即准备就绪的应用。

作为NAS时,AICUBE后置的的2个NVMe M.2接口,支持扩展至12TB存储容量;MTT AICUBE预计6月18日就会在京东开售...
AICUBE有着常见的扩展接口、扬声器和CNC一体成型的简约外观;硬件核心部分是摩尔线程自研的长江SoC芯片;外加32GB高速统一内存(标称120GB/s带宽,那么应该是LPDDR5X-7500),高配可选64GB;以及标准1TB SSD...
值得一提的是,“长江”是去年首届MUSA开发者大会上宣布的SoC芯片。当时摩尔线程主题演讲时就提到这是一颗集成8核2.65GHz CPU(IP不明,官方资料提到了“全大核”),MUSA架构GPU,外加可编程双核NPU、具备8K 30FPS/4K 60FPS编解码能力VPU,另外还带DPU(显示处理单元)、DSP、ISP的SoC芯片——50TOPS的INT8 AI算力主要由GPU提供;更重要的是这是一颗“全国产”芯片,“国内设计、国内生产、国内封装”。

长江SoC芯片除了用在AICUBE和AIBOOK之中,摩尔线程还推出了基于该芯片的MTT E300模组,面向OEM/ODM及其他硬件合作伙伴...
除了视频与图片的索引和搜索、基于存储内容的短视频生成,作为一台端侧智能体AI设备,AICUBE之中还预装了60+ skill,还有实时视频超分之类的能力。不过摩尔线程演示的重点或者说入口,依旧是小麦:让她根据要求播放电影、根据新拍的照片生成朋友圈文案、通过飞书给好友发消息,都是基于自然语言和模糊对话的方式进行的......
但这些大概也只能算寻常。在摩尔线程的未来展望中,AICUBE面向家庭时,小麦有可定制的身份、形象、声音,认识不同的家庭成员,有长时记忆,会主动判断不同家庭成员的需求,且能够配合智能家居(如家用摄像头的视觉听觉感知能力)提供更为全方位的交互和主动服务。
立足“家庭AI中枢”时,要构建起更为全面的生态才能完成这样的展望——从中的确是可以看到摩尔线程有做智能体AI入口的野心的,当然AICUBE和小麦或许都只是其中的组成部分。
Part 2 智能体AI的另一种可能性
发布会上的另外一款硬件设备、同样可作为个人智能体AI入口、同样基于长江SoC的MTT AIBOOK笔记本实际上去年就已经亮过相,也在京东有售。不过其系统及软件构成有一些更新和完善,包括基于Ubuntu深度定制的AIOS 1.4.1操作系统版本更新,提升了系统流畅度、触控板的多指触控体验、新的界面与交互方式等;
还有主流办公套件与即时通讯应用的支持、自研邮箱app、铠大师Windows虚拟机兼容Windows生态、预置容器兼容Android游戏生态,与趋境科技合作新增远程AI工程师做可远程技术支持等...这些应当都可以视作AIBOOK作为摩尔线程笔记本设备的既有能力。

demo区展示用AIBOOK玩Android游戏,具备出色的GPU硬件加速效率...
而作为更加AI native的AI PC,AIBOOK自诞生之初就在谈Linux环境下更稳定、更高效的AI表现。延续AI PC的逻辑,本次摩尔线程演示AIBOOK的核心功能不出意外的在智能体AI能力上——SLOGAN“为智能体而生”。当前AIBOOK预装了OpenClaw,当然“也可以选择调用我们的MTClaw”;而且加入了“精选的很多skill”,助力日常办公场景。
不过更重要的是,借助长江SoC,AIBOOK笔记本能同时运行12+智能体,“相当于12个员工”,则仅一台AIBOOK组建OPC一人公司成为了可能。这就涉及到AIBOOK软件更新的精华“多智能体协作平台”了,“我们将所有环境都setup好了”——很快通过PES应用商城就能下载:

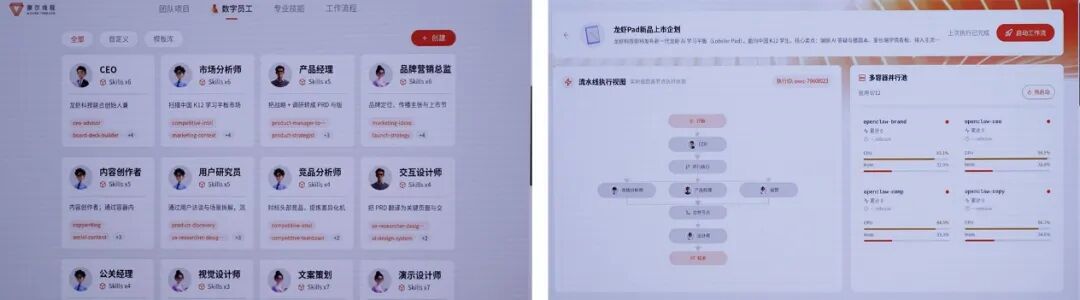
现场演示是用多智能体协作平台,选择平台中预置的CEO、市场分析师、产品经理、运营、设计等几个智能体或称数字员工角色,来共同完成某款新品的上市企划。摩尔线程说,这是个原本2-3周的工作,在该平台下几分钟内就有了完整初稿。“将完整的项目交给数字员工团队,他们会拆解任务,遵循设定编排好的工作流,协同并行推进。”
现场演示的工作人员介绍说,平台配置了面向各种使用场景的skill——这些skill是每个数字员工工作时可调用的专业能力,比如市场分析师会调用资料检索的能力。
虽然我们暂时还不清楚其工作产出质量及将AIBOOK用于OPC的实用性究竟如何,但多智能体在一台笔记本设备上并行协作的这番演示,的确展现了端侧智能体的另外一种可能性,而且摩尔线程还将它作为成品、而非单纯的demo呈现在了用户面前。

Part 3 真正体现实力的具身智能仿真平台来了...
说完端侧和边缘的3款产品,接下来就该谈谈数据中心或智算集群了。这是正面解决张建中在开场时所说token消耗量指数级增长的关键。不过这次张建中谈AI基础设施的重心不是MTT S5000,而是由其构成的夸娥智算集群。去年WAIC的报道文章里,电子工程专辑也重点提过KUAE集群——它是摩尔线程的核心战略,用于AI大模型训练、推理、智能体服务等,可能也是GPU显卡之外,外界最关注的话题之一。

除了再度提到,于模型训练而言,夸娥智算集群具备万卡稳定运行能力(Dense模型MFU 60%、MoE模型MFU 40%,有效训练时长>90%)、训练精度对齐“国际主流计算卡”(从PPT来看应该是Hopper)、集群线性度在万卡时保持95%、输出模型质量出众,KUAE Training Suite套件能够对pre-train、post-train、reinforcement learning提供出色支持;以及于模型推理而言,支持不同场景、大量主流模型之外...
张建中还举例谈到了夸娥是如何驱动短剧工业化的“全流程智能生产”的:这是一整套在夸娥上部署的“生产流水线”,“其中涉及的模型很多,要满足视频生成、语言理解、剧本创作等各种需求”...最终实现了视频制作成本的大幅下降,比如现场演示成本500元的token消耗制作的2分钟科幻场景短片,就已经具备影视商业应用潜质了。
不过夸娥并非本文要谈的重点,“摩尔线程利用夸娥AI工厂,能够提供一系列的训练平台,训练世界模型、机器人技能,或者机器人的训练仿真模拟”。于是有了本场发布会最为我们惊叹的摩尔线程在具身智能、Physical AI领域的布局。在全国产平台训练出能够为现实世界具身智能机器人所用的模型并在机器人身上实际发挥作用,以往应该还是不曾有过的。

现场演示了机器狗侧空翻,这应该是首次在全国产硬件平台上训练出来的运控策略、部署到全国产端侧芯片上,并实现了sim-to-real的验证...
电子工程专辑过去这两年撰写的有关NVIDIA机器人平台的文章,多半都提及了NVIDIA的“三台计算机”理论,一台用于训练Physical AI模型;一台作为模拟仿真引擎——可理解为Physical AI在虚拟环境中学习,进行模拟仿真和模型测试,也负责合成数据生成;还有一台就是机器人本身。
套用到摩尔线程身上,现在的摩尔线程应当已经涉足了这三台计算机,在国内可能也是绝无仅有的。这次发布的MT Lambda——“首个全栈国产化具身智能仿真平台”,应该划归在第二台和第一台计算机范畴(定位上有些类似Isaac?)。

张建中介绍说Lambda平台有三大核心能力:(1)多物理场统一求解,用开源+自研的物理引擎,将物理规律应用在虚拟世界之中,用于仿真真实物理环境;(2)高保真实时渲染,GPU的本行,包括摩尔线程GPU支持的硬件光追加速可提升渲染速度;(3)大规模集群扩展,尤其是夸娥支持将大量GPU用于机器人训练。
软件部分,在MT Lambda Lab之中,在MUSA的基础上构建起Lambda-Sim系统——其中的物理仿真引擎支持MuJoCo、Newton-musa,且内置了摩尔线程自研的物理引擎AlphaCore;而图形渲染引擎部分,除光线追踪外也支持混合渲染、MTAGR(生成式渲染),以及“将3DGS和4DGS的能力集成在图形渲染中,用户能够更简单的复制和建立3D模型来做训练”。另外,还提供了数据合成工具,支持世界模型、有强化学习工具等...
在此之后,“摩尔线程打通了从数据合成,到模型训练,到验证部署的闭环。”张建中总结说,“我们从感知模拟开始,有可交互的物理引擎,高质量的数据合成,机器人大脑模型训练,到强化学习的AI驱动并行训练,最后再仿真平台中验证真机的实际能力是否与理论一致”。
其中部分环节与合作伙伴共同完成。比如合成数据生成——这是解决数据稀缺、场景泛化等问题的关键,由摩尔线程与光轮智能合作打造。光轮智能有自研的高精度GPU物理求解器,支持刚体、柔体、流体、颗粒等复杂物理过程高精度实时仿真;且已经适配了MUSA架构,也令S5000发挥了更高的效率,“千卡集群每天能生成10万帧高保真合成数据”。而“具身大脑模型训练”环节,则与北京智源合作,训练成果已至RoboBrain 2.5......
更靠近模型训练、建立在Lambda-Sim之上的Lambda Lab支持强化、模仿学习和合作伙伴的RLinf框架,提供丰富的机器人模型与预置任务;内置多种传感器仿真,支持感知-动作一体化训练;GPU原生高吞吐仿真,做到集群化大规模训练;且最终sim-to-real落地,“让实际效果与预想的训练效果一致”...
以及在具身仿真全链路闭环的打造上,摩尔线程选择了与光线云合作,从任务资产的一键导入、云端智能算力调度、训练推理加速,到“混合内生世界模型”、最终虚实互联将仿真能力落地为真实世界应用。
从MT Lambda平台的发布,及不同环节合作伙伴的参与,是能够看到摩尔线程相较其他国产GPU厂商技术上的领先的;大概也算是“中国版英伟达”称谓某种程度的续写了——台上演示机器狗侧空翻的那几秒,实际上就该系统链条的搭建来看,都是极其不容易的过程。
Part 4 持续完善的MUSA生态,为智能体AI加速
最后简单谈谈支撑起上述一切的MUSA生态——有关摩尔线程MUSA架构和软件栈,我们在过去的文章里做过比较详细的解读,其概念与所处层级可与CUDA类比。实际上,现如今的MUSA基本也做到了“100%兼容主流生态”,包括Top100 AI加速仓库和Top100科学计算加速仓库;甚至有Automusify Skill来实现“0干预自动化移植现有工程到MUSA平台”——也算是智能体AI在反哺AI生态兼容性了。
从面向开发者的软件视角来看,MUSA在驱动运行时层支持761个API,加速库层实现了“100%完整兼容”,算子层覆盖核心55类算子——cuDNN可在muDNN上“完美实现”,框架层PyTorch算子的100%兼容。
本次的更新,除了文首提到的摩尔线程推出了MUSACODE,并以插件形式可集成到VSCode中——即靠AI写MUSA代码,可实现自然语言交互的代码生成,包括kernel或算子,如此一来AIBOOK和AICUBE也成为相当不错的MUSA开发工具;其他主要更新还包括有MUSA SDK 5.1.0版本升级,兼容CUDA 12.8版;
MATE算子库v0.2.1版本升级,FlashAttention3效率达到95%,算子覆盖率提升至90%,加速热点Attention/Sage Attention/DSA/GDN/DeepGEMM等;推理套件将SGLang合入主线,vLLM官方后端接入MUSA软件栈;针对超大规模集群,训练套件在pre-train、post-train、强化学习多方面支持更出色...
另外MUSA编译器技术也做了更新,包括MUSA Fortran编译器问世终于能将传统Fortran代码移植到MUSA生态下;MTX(中间语言)0.2.0版本更新,支持Inline MTX,具备更友好的兼容性,实现DeepEP等适配支持与效率优化;升级支持Triton 3.6;TileLang-MUSA合入开源主线,GEMM类算子性能达成95%以上的效率,Attention类算子效率超90%...

持久耕耘MUSA生态的价值,也能够在此时有所体现。值得一提的是,很难得在国产GPU厂商的发布会上,看到软件或生态相关的产品在主题演讲中占到过半的篇幅:不单是MUSA,小麦智能体、MT Lambda、AIBOOK的软件更新皆如是——国际主流GPU厂商的发布会有此情形倒是寻常,但这在国内的确还不多见。可能这也某种程度体现出了摩尔线程在国产AI技术领域的快人一步。
尤其是MT Lambda具身智能训练仿真平台及其成果给我们留下了深刻的印象,这大概是最能体现国产GPU企业具备面向更多垂直领域的技术能力,以及与国际接轨、开始具备竞争力的写照。虽说就GPU硬件层面,因为一些众所周知的原因,中国的芯片技术难以取得进展;但显然在智能体AI时代来临之际,中国的这些参与者并未因此停止创新和探索。AI时代的无限可能仍在续写。










评论区
登录后即可参与讨论
立即登录