导语
DeepSeek正进行首轮融资,金额高达500亿元人民币,其中创始人梁文锋个人或出资200亿。若顺利完成将刷新中国AI公司融资纪录,其估值也将飙升至515亿美元,重塑全球大模型产业格局。
更值得关注的是,DeepSeek V4.1或于6月登场,主打MCP协议适配与多模态能力。而大洋彼岸OpenAI发布GPT-5.5系列的同时,Anthropic年化收入已突破440亿美元。
在多模态理解、长程智能体、商业营收等维度上,DeepSeek与顶尖对手仍存在差距。这笔融资将如何缩短追赶距离,又将把中国AI引向何方?
商业与技术双重追赶
Counterpoint Research数据显示,2026年第一季度,全球大语言模型(LLM)市场总收入约207亿美元:Anthropic与OpenAI分别占据31.4%和29.0%的营收份额,DeepSeek营收占比仅为0.2%。
这一差异根植于商业模式的差别。Anthropic专注B端企业级市场,通过Claude模型的顶尖代码能力俘获开发者与企业客户;OpenAI则在C端与B端同时发力,以“全场景覆盖”取胜;而DeepSeek长期定位为“纯科研实验室”,开发者使用API多为低成本试验,企业级付费意愿尚未大规模转化。
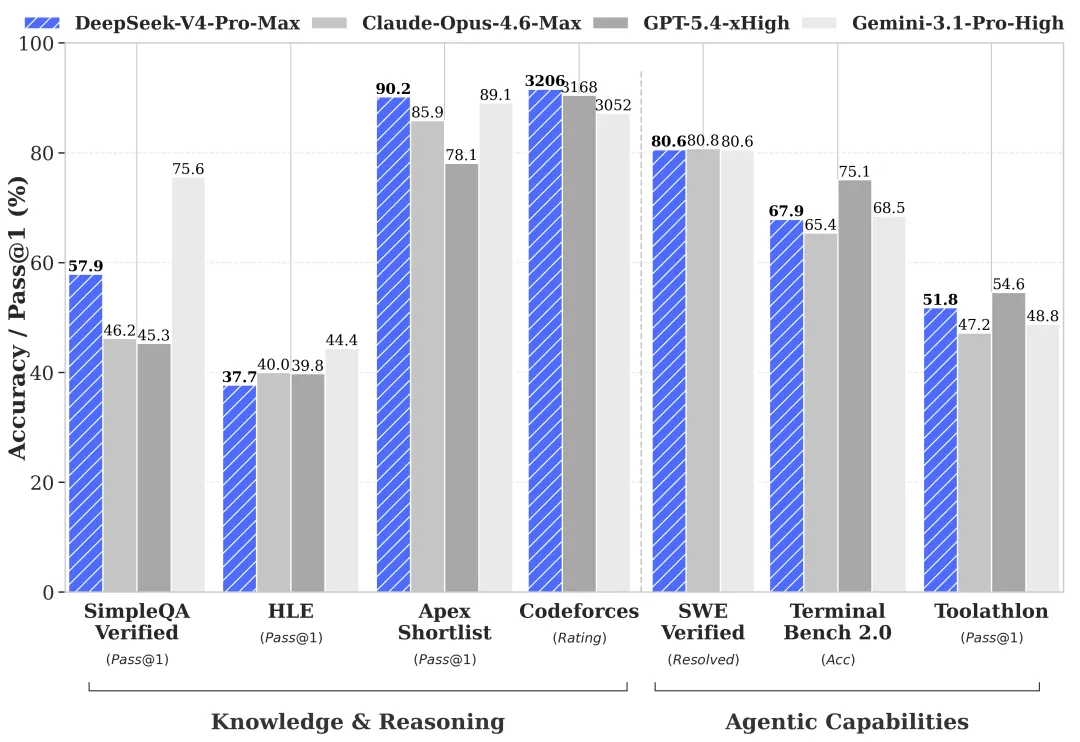
斯坦福大学HAI研究院报告显示,截至2026年3月,头部模型性能正快速收敛:Anthropic、OpenAI、Google、xAI四家Arena Elo评分差距已缩至25分以内;DeepSeek虽位列第一梯队,但与前四名仍有距离。
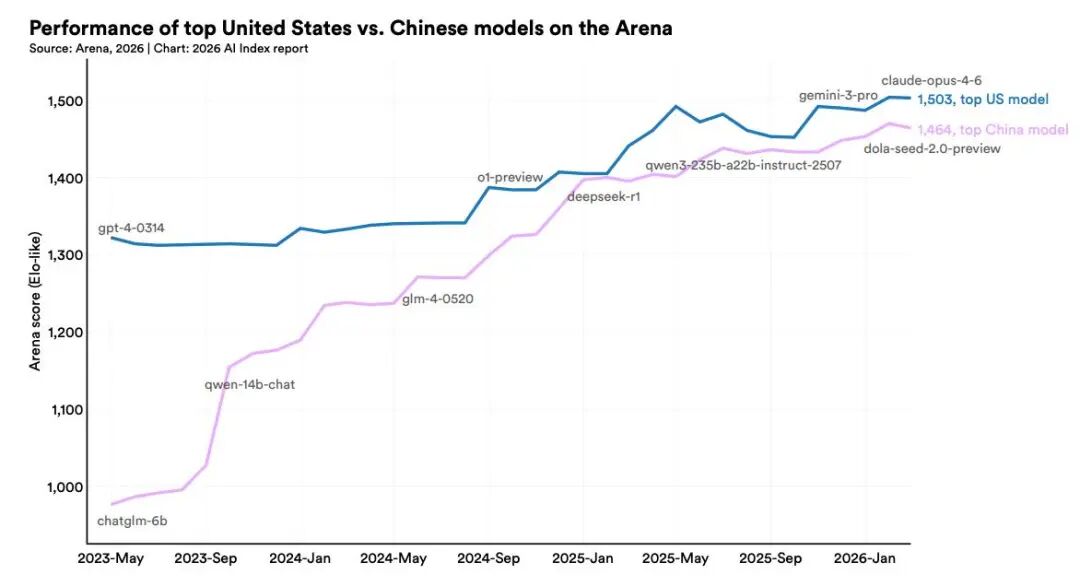
虽然DeepSeek V4.1版本有望新增图像和音频输入处理能力,但目前的纯文本模型对企业级应用场景构成严重制约。此外,今年行业重心已经从“聊天机器人”转向“自主执行复杂任务的AI Agent”,针对主流Agent产品进行适配优化的DeepSeek V4对比国外厂商的深度工具链整合仍有明显差距。
最昂贵的战争:人才与算力
DeepSeek此次融资,最直接的导火索是人才流失。过去一年,核心研发人员相继出走,大厂和资本雄厚的竞争对手用高薪与可兑现的期权抢人:罗福莉加入小米担任Mimo实验室负责人,王炳宣加入腾讯混元团队,郭达雅加入字节跳动Seed实验室,阮翀加入元戎启行任首席科学家。
长期不融资的DeepSeek期权却形同白纸,融资到账将改变后这一局面。4月27日,梁文锋完成注册资本变更,持股直接从1%提高到34%,最终受益股份达84.29%,表决权达100%。这意味着他有足够筹码设计团队激励方案,用可量化的期权稳住核心骨干、吸引外部人才。
算力则是另一场昂贵战争。当AI应用从简单对话转向“长程智能体”后,单次任务Token消耗提升了15到20倍,智能体相关任务已占整体算力消耗的47%。字节跳动2025年全年净利润下滑超70%,原因正是大幅加码AI全链条投入,阿里、腾讯的CAPEX指引也全部指向算力扩张。DeepSeek若再“自给自足”,算力差距只会越拉越大。
算力国产化从“可用”到“好用”
与其他玩家不同,DeepSeek并非从零开始:V4模型发布首周下载量突破17.4万次,华为昇腾、寒武纪、海光信息等国产芯片厂商同步适配,这种开发者粘性和技术信任,是绝大多数闭源厂商不具备的资产;DeepSeek网页端4月访问量达4.86亿,App月活用户1.39亿,在中国AI厂商中名列前茅。
流量底座配合开源社区的开发者生态,让DeepSeek具备“模型+入口”的双重优势。
融资后的商业化路径已清晰可辨 —— V4.1版本加强MCP协议适配,明确瞄准企业用户,让模型能接入企业现有软件系统,加入多模态能力,从“能聊天”进化到“能干活”。高盛发布分析报告称,DeepSeek-V4的核心意义在于以更低成本支持更复杂的智能体应用落地,从而打开AI应用规模化的新空间。知情人士透露,DeepSeek计划加快模型迭代节奏,“向行业主流看齐”,正主动向各行业推广模型,寻找商业合作机会。
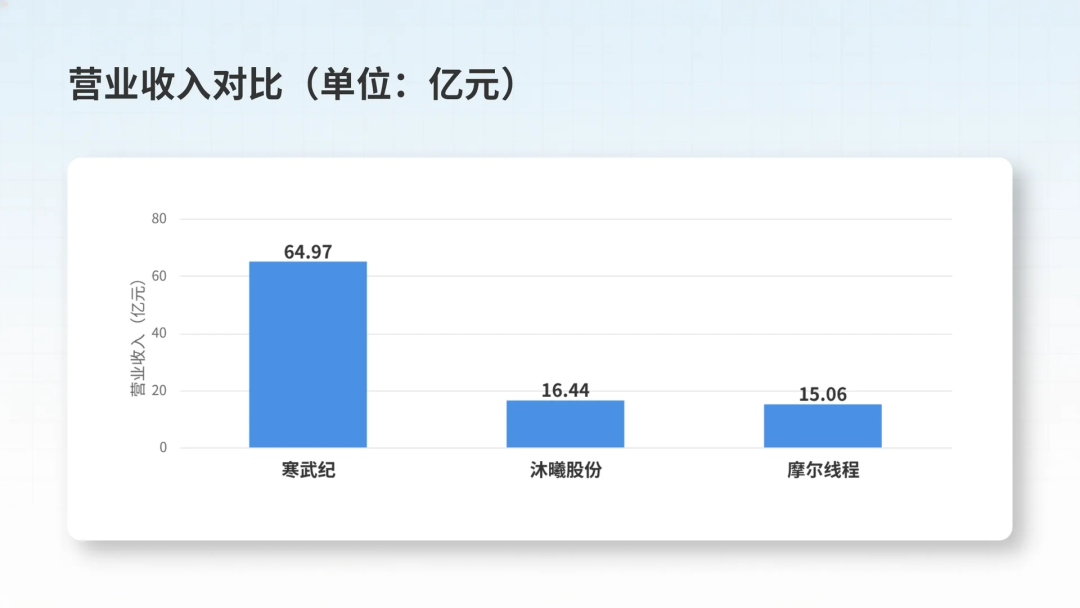
DeepSeek融资中,国家集成电路产业投资基金正洽谈担任主要投资方之一。DeepSeek V4发布时,华为昇腾、寒武纪、海光信息、摩尔线程、沐曦股份、昆仑芯、平头哥真武等多家国产AI芯片实现“Day0同步适配”,这并非偶然,在地缘政治与技术封锁背景下,“芯模共进”已成为国家级别战略方向。
当前时点国产模型能力持续突破,政企及云厂商正加快各类国产芯片适配采购,国产算力供需缺口持续扩大。未来的关键不只是解决“有没有”的问题,更要解决“好不好用”的问题,能效比、集群稳定性、软件生态成熟度将决定国产芯片能否真正承接爆发式增长的推理需求。
从单点突破到生态竞合
中国已构建起覆盖基础层(华为昇腾、寒武纪等AI芯片)、技术层(飞桨、昇思等深度学习框架)、模型层(DeepSeek、通义千问、文心一言等通用大模型)、应用层(办公、政务、工业等垂直场景)的完整产业链。未来竞争不再是单一模型性能之争,而是“芯片-框架-模型-应用”全链条效率之争。
国产月活规模前十名中,除字节、阿里、DeepSeek外,腾讯元宝、Kimi等产品已出现明显梯队分化。字节跳动年营收近千亿美元,阿里有云计算与电商现金流支撑,腾讯有社交生态与投资版图,纯创业公司很难跟上大厂持续的巨额算力采购和人才争夺战。
未来国内市场格局大概率是“3+N”结构:3家综合平台型公司(字节、阿里、腾讯)加上DeepSeek这类技术领先者构成第一梯队,其余玩家被迫转向垂直行业、细分场景寻找生存空间。大模型创业公司密集筹备IPO正是这种压力的直接体现,月之暗面、阶跃星辰已启动港股上市流程。
DeepSeek的融资故事,折射的是整个中国AI产业正在经历的深层转型。当技术奇点的窗口期以“月”为单位计算,速度决定生死。500亿融资搅动的,不只是DeepSeek一家公司的命运,还将加速中国AI大模型产业的“优胜劣汰”进程,催生更清晰的竞争格局,并推动行业从“拼技术”走向“拼价值”。
“国家队”资金入场、芯片厂商同步适配、模型公司加速IPO,中国AI正在告别“散兵游勇”阶段,进入系统化、组织化、资本化的新纪元。中国与世界顶尖模型的性能差距已缩至个位数百分比,但商业变现能力、开发者生态成熟度、企业级服务体系的差距,可能需要更长时间追赶。



评论区
登录后即可参与讨论
立即登录