GPU 相关常见术语
本文介绍了GPU 相关常见术语。 CPU像总经理,GPU像几万个熟练工人;CUDA 像管理这些工人的操作手册,HBM 像高速仓库,NVLink 像工厂之间的专用高铁。AI 模型越大、Token 调用越多,对 GPU、显存、互联、电力和散热的要求就越高。 你可以把 GPU 理解成:一座有成千上万个“小工人”的计算工厂,特别擅长同时处理大量重复计算,所以非常适合 AI、图形渲染、科学计算和大模型训练。
关于「GPU」的技术文章、设计资料与工程师讨论,持续更新。
本文介绍了GPU 相关常见术语。 CPU像总经理,GPU像几万个熟练工人;CUDA 像管理这些工人的操作手册,HBM 像高速仓库,NVLink 像工厂之间的专用高铁。AI 模型越大、Token 调用越多,对 GPU、显存、互联、电力和散热的要求就越高。 你可以把 GPU 理解成:一座有成千上万个“小工人”的计算工厂,特别擅长同时处理大量重复计算,所以非常适合 AI、图形渲染、科学计算和大模型训练。

黄仁勋的物理AI,要烧掉15个宇树 我一直说,老黄绝对是这个时代资本代理人的楷模。 和他相比,马斯克多了点理想主义,库克甚至有点呆萌,而微软、谷歌、亚马逊等巨擘的掌门人,竟然显得名不见经传,老黄自然是有极有水平的。 AI的第五层—物理AI,"如果说生成式AI让机器学会'表达',物理AI则赋予机器'指挥行动'的能力。"老黄的一句话,深刻切中痛点,当今的大模型仍无法实际解决问题、人型机器人还在各种出丑
5月20日晚,砺算科技旗下首款消费级显卡LX 7G100创始版在京东开启预约。首批限量1000份,售价2969元(含官方政府补贴)。24小时内预约人数突破2.2万,中签率不足5%,市场热度可见一斑。 此次限量版包含砺算创始人宣以方的亲笔签名及专属数字编号。据官方消息,普通版LX 7G100将于618之后上市,售价有望进一步下探,为消费者释放更多优惠空间。 LX 7G100基于砺算自研的TrueGP
NVIDIA Deep Learning Compute(深度学习计算)是一支专注于“算法-软件-硬件”协同设计的 AI 加速团队,以“让 AI 更快、更省、更具扩展性”为使命。从模型创新、软件研发到芯片微架构,从底层算子优化到端到端系统落地,我们的目标是实现全栈技术贯通,持续驱动 GPU 架构迭代演进。团队现开放多个核心技术岗位,期待您的加入。 深度学习计算性能优化架构团队 团队介绍 我们专注于
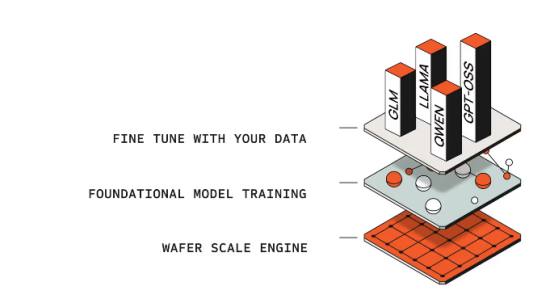
前言: 一家成立十余年的芯片公司,从2025年9月约81亿美元私募估值,到5月14日以488亿美元估值,超额认购超过20倍登陆纳斯达克,它被贴上了一个极具传播力的标签:英伟达挑战者。 一颗“整片晶圆”做成的芯片 英伟达的路线,行业已经非常熟悉:把GPU做得越来越强,再通过NVLink、InfiniBand、以太网、交换机、液冷系统和软件栈,把成千上万张GPU组织成巨型AI集群。 这套体系极其强大
暑假将至,NVIDIA 2026 暑期实习网申现已进入最后冲刺阶段! 作为 AI 计算和 GPU 技术的引领者,我们正在寻找对技术充满热情的你,与全球领先的团队一起用前沿科技探索更多可能。 核心岗位仍有少量名额。还在观望的同学,不妨登上这趟通往未来的“末班车”! 几个数据快速了解 NVIDIA NVIDIA 作为 AI 和加速计算领域的全球领导者,为全球的 AI 基础设施注入动力,持续推动着各行各
AI芯片目前是国内半导体被卡脖子最严重的领域之一,但它同时也是国产芯片机遇最明确的,而且这一次的逆袭会来得很快,10年时间就能完成全面国产替代。 根据摩根斯坦利公布的一项研究结果,国产AI芯片自给率(主要是GPU类型)在2021年才只有10%,但是发展速度非常快,今年就能达到41%,四年时间份额3倍提升。 接下来的5年中,AI芯片的自给率还会快速提升,到2030年将提升到86%,意味着进口的所有A

近期5月7日,埃隆·马斯克在X平台上扔下一颗重磅炸弹:xAI将不再作为独立公司存在 xAI 及其旗下的大语言模型 Grok(以及社交平台 X 的相关业务)都将并入SpaceX,未来以“SpaceXAI”的名义继续运营。 几乎同一时间,SpaceX与Anthropic联合宣布——Colossus 1超级集群全部算力租给Anthropic,超过22万张NVIDIA GPU、300兆瓦+电力,本月内全面

证监会官网显示,昆仑芯(北京)科技股份有限公司于2026年5月7日正式启动科创板上市辅导,中国国际金融担任辅导机构。这是继2026年1月公司以保密形式向港交所递交主板上市申请后,资本运作的又一关键步骤,标志着其"A+H"两地上市计划全面铺开。 百度控股57.67%,估值或处行业头部区间 辅导备案报告显示,昆仑芯成立于2011年6月10日,注册资本41,237.1134万元,法定代表人为欧阳剑。公

在AMD第四季度财报电话会议上,首席执行官苏姿丰(Lisa Su)博士讨论了人工智能CPU市场的竞争情况。 由于智能体人工智能工作负载的增长,人们普遍认同CPU在人工智能行业中扮演着至关重要的角色,从AMD的主要竞争对手英特尔上个月发布的财报显示其利润大幅超出预期也不难看出 —— 智能体人工智能正在增加服务器计算对CPU的需求。 最开始紧缺的是GPU,随后是内存,而如今紧缺的矛头转向了CPU。据半
当地时间5月6日(北京时间5月7日凌晨),埃隆·马斯克在社交媒体X平台发文宣布,xAI将作为独立公司解散,正式并入SpaceX并更名为SpaceXAI。马斯克在回复特斯拉投资者Sawyer Merritt的帖子时写道:"xAI将作为独立公司解散,所以它将仅剩SpaceXAI,即SpaceX的AI产品。"此番表态意味着这家估值曾高达2500亿美元的AI独角兽,在独立运营近三年后彻底终结其独立法人地位
数字时代里,算力就是推动技术进步的核心引擎。ASIC芯片和GPU作为两种最核心的算力载体,各自在特定领域都有着不可替代的优势。 今天就把两者的技术差异、性能特点和适用场景说透,不管你是挖矿、做AI还是搞高性能计算,都能得到专业的参考。 1. 先给核心结论 ASIC是为单一任务优化的专用芯片,GPU是面向通用并行计算的灵活方案,两者没有绝对好坏,只看你用在什么地方。核心差异我整理了一张对比表,一目了
CPU与GPU的使用比例正在翻倍甚至三倍增长,最终会接近1:1。 柳絮纷飞的四月中旬,Kevork Kechichian从北京开启了加入英特尔之后的首次中国行。 与他接手英特尔公司执行副总裁兼数据中心事业部(DCG)总经理时相比,这家半导体巨头的状态,已经发生变化。 9个月前,Kevork Kechichian加入英特尔时,公司股价仍在24美元左右徘徊。如今,这一数字已升至65美元附近,市值回到近

随着人工智能(AI)驱动的数据呈指数级增长,高带宽内存(HBM)的应用也随之激增。 然而,HBM仍属高端内存,技术实现难度颇高。由于英伟达(NVIDIA)在GPU开发上步伐迅猛,相关标准难以跟上——这意味着,若HBM想继续搭乘GPU和加速器普及的快车,定制化至关重要。 Dell’Oro集团2025年6月发布的一份报告显示,持续的AI发展推动服务器和存储组件市场在2025年第一季度同比增长62%,
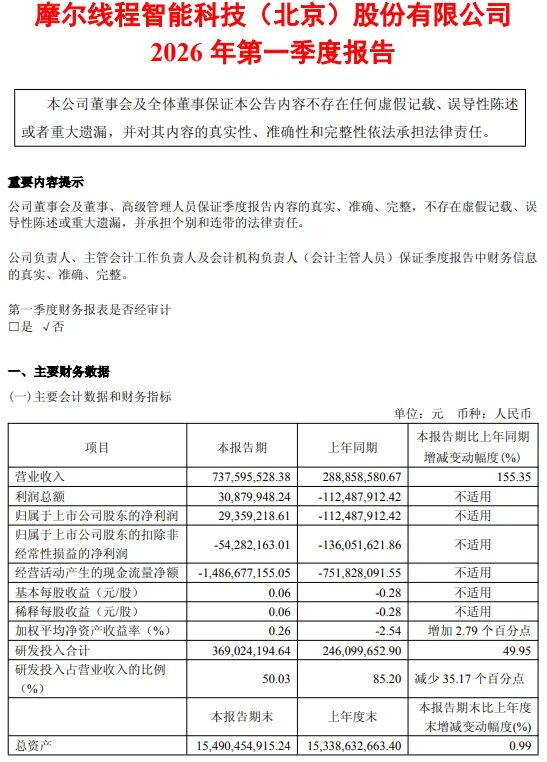
4月26日晚间,国产GPU龙头摩尔线程(688795.SH)披露上市以来首份年报及一季报,向市场交出了一份颇具分量的成绩单。 财报显示,2026年第一季度,摩尔线程实现营收7.38亿元,同比增长155.35%;归母净利润2935.92万元,同比增加1.42亿元,实现同比扭亏为盈;归母扣非净利润亏损0.54亿元,亏损同比收窄60.10%。 这是摩尔线程自2025年12月5日登陆科创板以来,首次在单
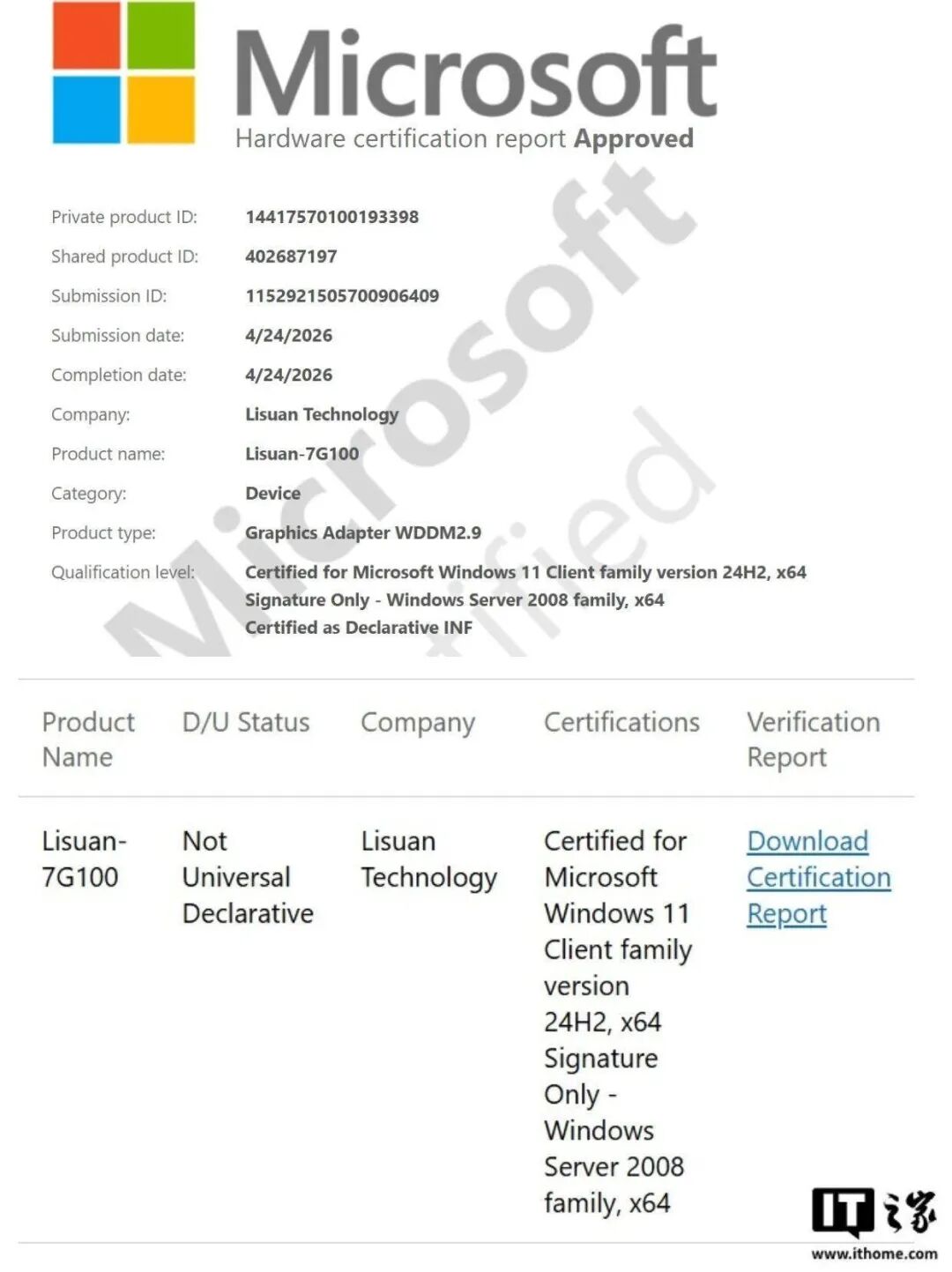
4月26日,据微软官方认证公示信息显示,砺算科技自研高性能图形GPU 7G100系列正式完成微软WHQL(Windows Hardware Quality Labs,Windows硬件质量实验室)全维度合规认证。至此,砺算科技成为国内首家、全球第四家通过该项严苛认证的GPU设计企业,与英伟达、AMD、英特尔三大全球图形算力巨头并列第一梯队。 此次认证落地,并非单一产品技术参数的常规达标,而是国产通

最近这两年,网上关于AI-RAN的讨论很多。 有人认为,AI-RAN是大势所向,代表了通信架构的未来演进方向。 也有人认为,AI-RAN就是一个噱头,是某些厂商的一厢情愿,肯定不会成功。 那么,到底什么是AI-RAN?它背后的技术逻辑是什么?它究竟会不会颠覆整个通信行业呢? 什么是AI-RAN AI-RAN,即人工智能无线接入网(Artificial Intelligence - Radio Ac

4月20日,国产GPU厂商象帝先计算技术(重庆)有限公司(以下简称“象帝先”)通过官方微信公众号宣布,近日已与国内头部券商中信建投证券股份有限公司(以下简称“中信建投证券”)正式签署财务顾问协议,全面启动IPO上市前各项准备工作。 作为国内资本市场的头部券商,中信建投证券在半导体、集成电路等硬科技领域积累了丰富的辅导与保荐经验,此次双方携手,既是象帝先对上市工作的高度重视,也是对中信建投证券专业能

36氪获悉,浙江杭州GPU创企曦望近日宣布完成新一轮超10亿元融资,这也是2026年AI产业迈入“推理落地、智能体普及”时代后,国内GPU赛道诞生的最大单笔融资之一。 据悉,本轮融资由多家产业方战投、地方国资及头部财务机构共同参与,杭州资本为投资方代表,其表示看好曦望“All-in推理”的战略前瞻性及技术与商业化能力。融资资金将主要用于新一代S3推理GPU的规模化量产交付、全栈软件生态建设,以及
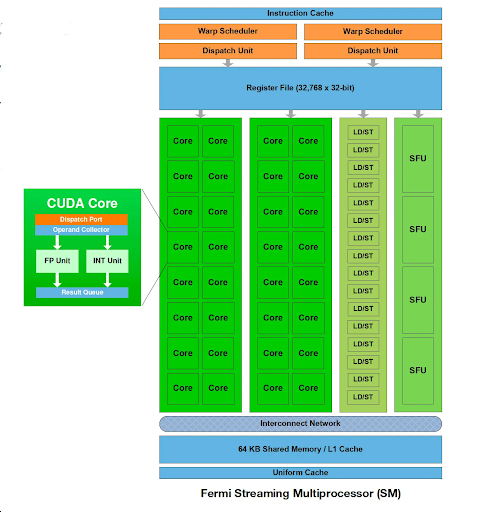
本文介绍了GPU和LPU的区别与各自适用场景。 众所周知,AI芯片领域,英伟达GPU一家独大,但最近有个新选手跳出来叫板——LPU,专门做大语言模型处理(LLM)的新架构。 这玩意到底是黑科技还是炒概念?今天咱就硬核拆解,谁才是AI的最优解,看完你就懂了。 核心结论先给你撂这:GPU仍是全能扛把子,LPU是LLM推理领域的专门杀手,如果你只做大语言模型推理,LPU现在已经比GPU更强。但是做LLM