
随着人工智能(AI)驱动的数据呈指数级增长,高带宽内存(HBM)的应用也随之激增。
然而,HBM仍属高端内存,技术实现难度颇高。由于英伟达(NVIDIA)在GPU开发上步伐迅猛,相关标准难以跟上——这意味着,若HBM想继续搭乘GPU和加速器普及的快车,定制化至关重要。
Dell’Oro集团2025年6月发布的一份报告显示,持续的AI发展推动服务器和存储组件市场在2025年第一季度同比增长62%,其中对HBM、加速器和网卡(NiC)的需求尤为强劲。
Dell’Oro高级研究总监Baron Fung在接受笔者采访时表示,英伟达的Blackwell GPU,加上主要云服务提供商推出的定制加速器,正共同推动AI加速器市场的发展。
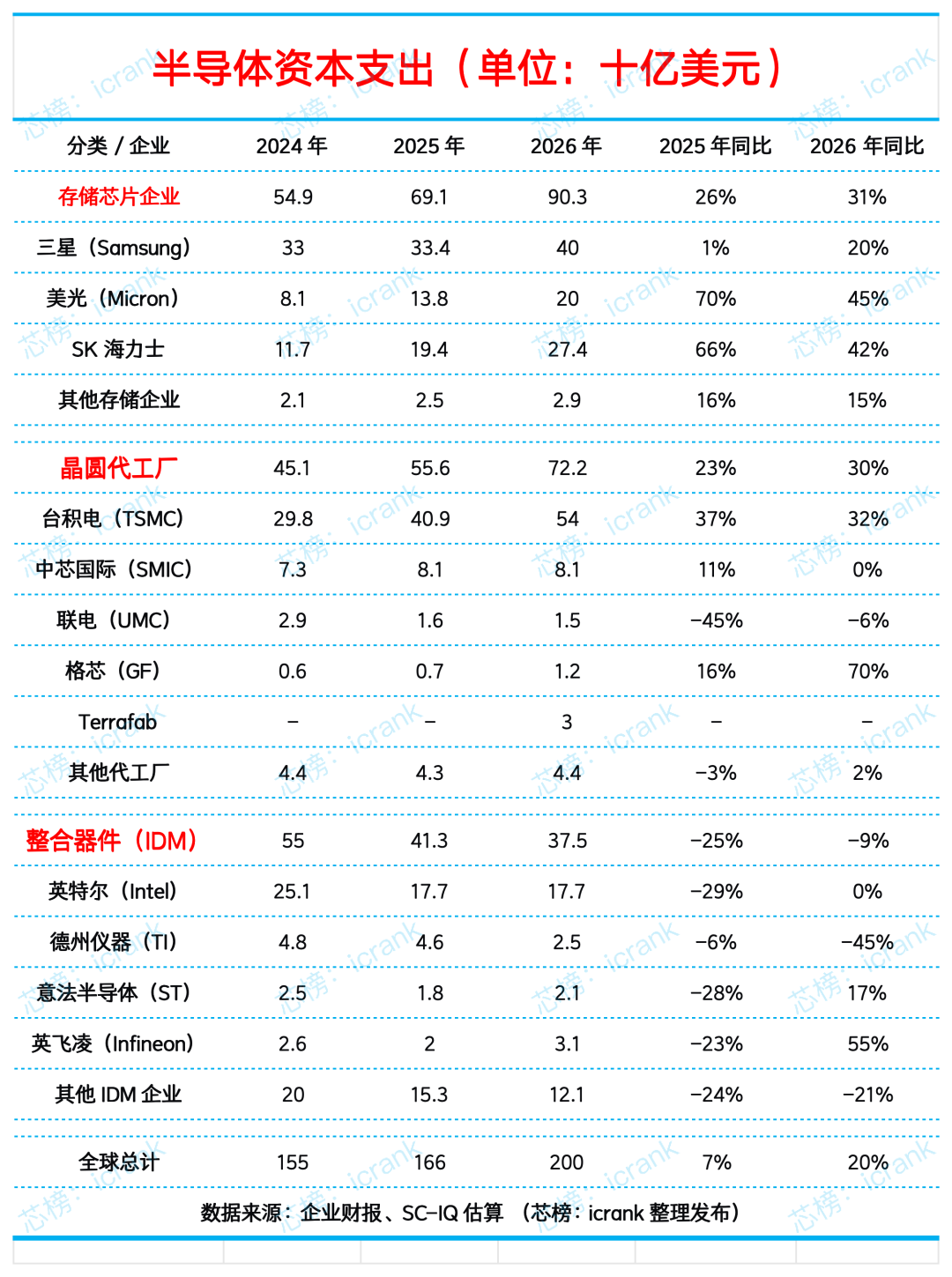
Dell’Oro发布的《数据中心IT半导体及组件季度报告》指出,SK海力士以64%的营收份额领跑HBM市场,三星和美光科技紧随其后。
Fung表示,受专注于训练的GPU增长驱动,HBM的普及率自2022年起显著提升。“与此同时,AI服务器乃至加速器对HBM的采用率也在不断提高。”
GPU产能正在推动HBM需求增长
Dell’Oro集团Baron Fung
Fung指出,过去几年间,AI服务器的市场份额已从20%增至约60%,HBM和GPU的容量及性能也实现了飞速增长。这种增长给HBM供应带来了巨大压力,供应商的订单往往提前一年就被预订一空。
三星一直难以满足HBM芯片的供应需求,这为SK海力士和美光的迅速崛起提供了契机。美光的下一代HBM4采用2048位接口,预计将于2026年投产(图1)。
美光随后还将推出HBM4E,并允许客户定制其基础裸片。该公司披露,2025财年第四季度HBM收入实现大幅增长,年化收入规模较上季度提升20亿美元,达到近80亿美元。
Fung表示,关税带来的不确定性增加了供应链复杂性,这将影响HBM的价格。
对于高性能计算需求,除HBM外虽有其他替代方案,但局限性明显。“一些低端GPU使用GDDR,但无法获得HBM那样的高速互连及与GPU的紧密集成,”Fung说道。其他选择包括用于训练模型存储的低延迟DRAM或闪存SSD,但若追求顶级性能和最低延迟,HBM仍是不可或缺的选择。

图1:美光下一代HBM4显存采用2048位接口,预计将于2026年投产;HBM4E显存将在随后几年推出,并提供定制化裸片选项。(来源:美光)
供应与标准流程成瓶颈
Fung表示,GPU制造商正在为HBM供应商制定路线图。由于供应受限,三大厂商都将拥有强劲的市场表现,其中SK海力士领先,三星和美光紧随其后。
HBM制造商面临的挑战在于,GPU供应商发布新技术的步伐已显著加快,几乎每年推陈出新,这远快于内存标准的传统更新周期。
爱德万测试(Advantest)高级总监兼内存产品营销经理横山仁(Jin Yokoyama)告诉笔者,与以往需四到五年才能完成的内存技术更新不同,如今HBM的迭代周期已缩短至两到两年半,大大加快了创新步伐。他表示,数据中心和加速器中的HBM正经历快速增长和技术进步。
横山仁还指出,HBM晶圆产量急剧上升,增速超过了DDR5等传统DRAM。这种快速发展给爱德万等测试厂商带来了巨大挑战,因为他们必须跟上更快的产品迭代周期和日益复杂的设计要求。
此外,横山仁强调,不同厂商的测试要求各不相同。关键挑战包括不断提升的数据带宽和器件容量,这需要开发更高速的测试解决方案和更强大的散热管理功能。
定制解决方案加剧测试复杂性
横山仁表示,HBM测试的复杂性进一步加剧,部分原因在于针对高级AI和SoC应用场景的定制化方案日益普及。
他指出,传统上HBM标准由JEDEC制定,供应商负责制造内存核心和基础逻辑晶圆。但随着HBM4的出现,SoC供应商和超大规模云厂商越来越需要定制化HBM功能,以优化特性,使其与特定的AI ASIC或定制SoC完美匹配,从而实现最佳性能。
横山仁表示,这一趋势促使更多逻辑和控制器功能被直接集成到HBM基础逻辑裸片中。基础逻辑裸片的制造正逐渐转移至台积电等采用3nm或5nm先进工艺的代工厂,而这些先进工艺反过来又需要更先进、更灵活的测试流程。
Marvell Technology产品营销高级总监Khurram Malik表示,机器人、传感器及其他物联网(IoT)边缘设备的普及导致数据呈指数级增长,颠覆了HBM传统的线性发展模式。HBM4E在JEDEC发布HBM3规范仅三年内便已上市。
Marvell与所有主要HBM供应商(包括美光、三星和SK海力士)合作,采用其定制的HBM计算架构。Malik表示,该架构于2024年底发布,通过集成先进的2.5D封装技术和定制接口,能够设计出专为AI加速器(XPU)量身定制的HBM系统。
Malik指出,随着每一代新产品的推出,HBM的内存带宽和I/O数量均翻倍增长,封装密度和复杂性也日益提高。由于HBM4和HBM5等技术将I/O数量从2000个增至4000个,要在业内达成共识并非易事,这就要求采用创新的封装方式,以便在有限空间内容纳这些高带宽连接。
Malik表示,英伟达不仅缩短了产品开发周期,实现每年发布一款新GPU,还计划将内存带宽和容量翻一番。然而,JEDEC标准的制定耗时较长,这意味着英伟达正转向定制解决方案。
模型规模扩大对存储容量提出更高要求
Malik表示,由于架构复杂性(包括内存和控制器布局),HBM5在标准化和普及方面将面临挑战。随着工作负载对每个计算裸片的HBM堆栈需求增加,对于设计下一代AI和计算硬件解决方案的客户而言,平衡高内存带宽与更高容量变得至关重要。
Malik指出,AI已“大幅膨胀”了对存储容量的需求。“顶级AI模型发展迅猛,参数数量已从数百万激增至数十亿。我们预计单个模型将产生万亿级参数,而这些参数都需要驻留在内存中。”
他表示,Marvell的定制HBM架构可实现33%的内存容量提升,计算面积增加高达25%,内存接口功耗降低70%——对于运行AI工作负载的现代数据中心而言,这一指标正变得尤为重要。优化的接口减少了每个裸片所需的硅片面积,从而可以将HBM支持逻辑集成到基础裸片上(图2)。
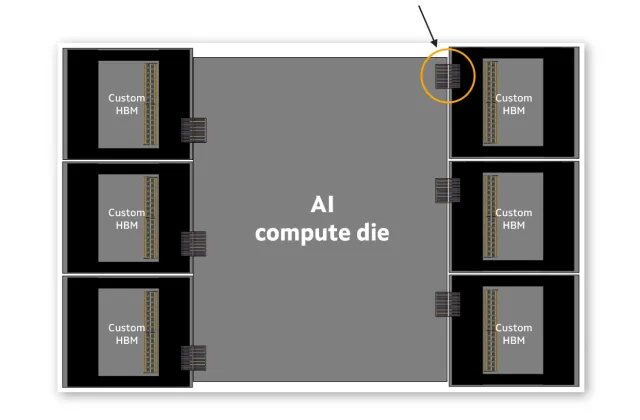
图2:Marvell定制HBM显存的XPU渲染图。(来源:Marvell)
Malik表示,Marvell为其HBM5架构提出的方案是采用裸片间互连技术,以加快连接速度并进一步释放芯片空间。Marvell架构不依赖JEDEC标准,需要新的控制器、可定制的物理接口、新的裸片间接口以及改进后的HBM基础裸片。
他指出,像英伟达这样的超大规模云厂商和GPU制造商正在快速创新HBM架构,专注于带宽和计算需求,其速度往往领先于标准制定机构。由于行业发展日新月异,标准制定机构的更新速度显得相对滞后。
“业界需要意识到,他们急需更高效的HBM架构。”Malik说道,“终端用户和超大规模云厂商将会采用一切可行方案,以满足其计算所需的带宽和吞吐量。”






评论区
登录后即可参与讨论
立即登录