数字时代里,算力就是推动技术进步的核心引擎。ASIC芯片和GPU作为两种最核心的算力载体,各自在特定领域都有着不可替代的优势。
今天就把两者的技术差异、性能特点和适用场景说透,不管你是挖矿、做AI还是搞高性能计算,都能得到专业的参考。
1. 先给核心结论
ASIC是为单一任务优化的专用芯片,GPU是面向通用并行计算的灵活方案,两者没有绝对好坏,只看你用在什么地方。核心差异我整理了一张对比表,一目了然:
| Feature | ASIC | GPU |
| 设计目标 | 面向单一 / 特定场景专用加速 | 面向通用并行计算 | | 性能表现 | 特定任务极致性能、超高能效 | 多任务均衡性能,通用算力强 | | 功耗 | 深度优化,功耗极低 | 功耗较高,中~高功耗 | | 成本 | 研发 / 流片成本极高,量产成本较低 | 研发成本适中,采购与部署成本相对友好 | | 灵活性 | 硬件功能固化,几乎不可编程 | 软件可编程,灵活性极强 | | 迭代速度 | 慢,硬件改版周期长 | 快,驱动与架构迭代频繁 | | 典型应用 | 加密货币挖矿、AI 推理、网络转发、信号处理 | 游戏渲染、AI 训练、科学计算、通用并行计算 |
2. ASIC芯片:专用计算里的性能天花板
先搞懂ASIC到底是什么
ASIC的全称是Application-Specific Integrated Circuit,翻译过来就是专用集成电路,说白了就是为某一个特定应用量身设计的芯片。
和通用处理器不一样,ASIC从硬件层面就已经做好了固定的预定义指令集,来源维基百科的定义就是这么说的。这种专用性,就是它性能优势的来源。
从架构上来说,ASIC集成了几百万到几十亿个晶体管,所有电路都是为目标任务专门设计的。核心组成就是做基础运算的逻辑门、存储模块,还有高速互联系统,这些结构合起来,让ASIC在目标任务上的表现,把通用处理器甩了好几条街。
ASIC的四大核心技术优势
ASIC的优势主要体现在四个方面,每一个都是戳中痛点的。
第一就是极限计算性能。拿比特币挖矿举例子,最新的比特大陆蚂蚁矿机S21 XP水力版,能做到473TH/s的算力,功耗才只有5676瓦,能效比做到了12焦耳每TH,这个性能是任何通用处理器都达不到的。
第二就是出色的能效比。完成同样的任务,ASIC的功耗比通用处理器能降70%以上。在AI推理场景里,谷歌TPU v5比普通GPU的单位计算成本低70%,亚马逊Trainium 3的功耗只有普通GPU的三分之一。
第三是规模化后的成本优势。虽然ASIC前期开发成本很高,7纳米工艺的设计成本大概就要5000万美元,但量产之后边际成本会大幅下降。谷歌TPU v4出货量从10万片涨到100万片的时候,价格从3800美元跌到了1200美元,降了70%。
最后就是小型化优势。因为是专用设计,ASIC在更小的芯片面积里就能堆下更高的计算密度,对那些对空间要求苛刻的应用来说,这一点太重要了。
有个类似的场景就是加密货币挖矿。最早的加密货币红利都是GPU的。
但是ASIC后来居上。
2024年顶级比特币挖矿设备的能效已经做到了12-15J/TH,数据来自Hashrate Index,和2016年比进步了8倍。
| 型号 | 算力 (TH/s) | 功耗 (W) | 能效 (J/TH) |
| Antminer S21 XP | 473 | 5676 | 12.0 | | Antminer S21 Pro | 234 | 3510 | 15.0 | | MicroBT M50S++ | 298 | 5066 | 17.0 | | Canaan A1466 | 195 | 3420 | 17.5 | | MicroBT M50S | 126 | 3276 | 26.0 |
从蚂蚁S21 XP的473TH/s到MicroBT M50S的126TH/s,这些数据就能看出来ASIC在特定领域的压倒性优势。
所以,从这个趋势来看,ASIC能够大战拳脚的重要战场就是AI推理加速。
| 年份 | ASIC 市场份额 | 同比增长 |
| 2024 | 15% | – | | 2025 | 25% | +67% | | 2026 | 40% | +60% | | 2030 | 80%(预测) | +100% |
谷歌TPU v6(Trillium)比v5e性能提升了4.7倍,TPU v7(Ironwood)更是专门针对推理做了优化,而V8也有了专门的推理芯片,足见ASIC在AI领域的潜力有多大。
3. GPU:并行计算里的多面手
GPU架构的独特优势
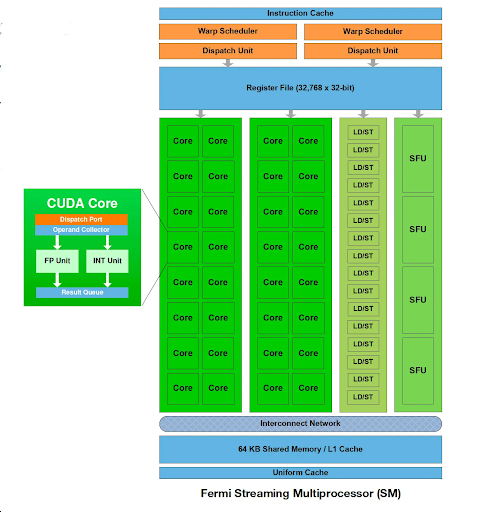
GPU就是图形处理器,用的是大规模并行架构设计,一块芯片里集成了几千个计算核心。拿NVIDIA RTX 4090举例子,它有16384个CUDA核心,可以同时处理海量的并行任务,这种架构天生就适合处理复杂计算和多样化任务。
现代GPU架构一直在进化。NVIDIA的Ada Lovelace架构用了台积电4N工艺,集成了763亿个晶体管,还配了第三代RT核心和第四代Tensor核心。AMD的RDNA 3架构首创了小芯片设计,比RDNA 2的每瓦性能提升了50%。这些创新让GPU在保持通用性的同时,专业计算能力也在不断提升。
灵活的可编程性是GPU的核心优势之一。支持CUDA、OpenCL这些编程框架,开发者可以用软件定义GPU的功能,就能适配不断变化的算法需求。
另外GPU的内存带宽也做得非常高,NVIDIA H100配的HBM3内存,带宽最高能到3.35TB每秒,给大模型训练提供了强有力的支撑。
GPU的性能表现
在游戏和图形渲染领域,GPU的能力大家都有目共睹。Tom's Hardware的测试数据显示,RTX 4090在4K分辨率下平均能跑116帧,即将推出的RTX 5090比4090快24%,能跑到144帧。
| GPU 型号 | 4K 平均 FPS | 相对 RTX 4090 性能 |
| RTX 5090 | 144 FPS | +24% | | RTX 4090 | 116 FPS | 基线 | | RX 7900 XTX | 95 FPS | -18% |
光追性能上,RTX 5090比上一代提升27%,加上DLSS 4技术最多能提供4倍的性能提升。AMD的RX 7900 XTX虽然绝对性能稍弱,95帧的表现也已经相当不错了。
AI训练是GPU的另一个核心应用领域。配了80GB HBM3内存的NVIDIA H100,内存带宽达到3.35TB每秒,做大语言模型训练比A100快4倍。
| GPU 型号 | 内存 | 带宽 | 相对性能 |
| H100 | 80GB HBM3 | 3.35 TB/s | 4.0x | | A100 | 80GB HBM2e | 2.0 TB/s | 1.0x | | RTX 4090 | 24GB GDDR6X | 1.0 TB/s | 0.6x |
在PyTorch框架下跑Granite 7B模型,A100每个GPU每秒能处理4550个token,加上自动混合精度技术,性能几乎翻了一倍。消费级的RTX 4090虽然只有24GB内存、1TB带宽,AI训练性能也能达到专业A100的60%,性价比非常突出。
在通用计算(GPGPU)领域,H100的DPX指令给非AI workload提供了7倍的加速,还支持FP64精度计算,在科学计算领域表现非常出色。多实例GPU(MIG)技术能把一块GPU分成多个独立实例,提高资源利用率。
GPU的应用场景有多广
GPU的应用真的非常宽。内容创作里,视频剪辑、3D渲染、特效处理都需要GPU加速;科研领域,分子动力学模拟、气候建模、基因组分析都离不开GPU;金融领域,GPU用来加速风险分析和高频交易算法。
加密货币挖矿现在已经不是GPU的主要应用了,但对一些抗ASIC的币种,GPU还是有优势。RTX 4090的Ethash算力能到140MH/s,RX 7900 XTX在Equihash算法上表现很好,适合挖Kaspa、Ergo、Ravencoin这些币种。
4. 深度对比:ASIC和GPU到底差在哪
核心指标对比
我们把各项核心指标拉出来比一比,高下立判:
| 指标 | ASIC | GPU | 优势方 |
| 单任务性能 | 100% | 10-20% | ASIC | | 能效比 | 90% | 30% | ASIC | | 开发成本 | 5000 万美元以上 | 0 | GPU | | 灵活性 | 极低 | 极高 | GPU | | 使用寿命 | 2-3 年 | 4-6 年 | GPU | | 应用范围 | 单一 | 广泛 | GPU |
在特定任务的性能上,ASIC的优势是压倒性的。
Bitdeer的对比数据显示,比特币挖矿里,ASIC每瓦算力是GPU的200万倍以上。
AI推理任务里,ASIC的优势同样明显。
测试数据显示,专门的AI ASIC在矩阵运算这类核心任务上,效率比GPU高50%,功耗低30%。
| 设备 | 算力 | 功耗 | 能效 (TH/s per kW) |
| ASIC (S19 Pro) | 110 TH/s | 3250W | 33.8 | | 20x RTX 4090 | <0.1 TH/s | 9000W | 0.00001 | | 性能差 | 1100x | 0.36x | 3380000x |
Groq的LPU就号称比NVIDIA GPU快10倍,功耗还只有十分之一。
但反过来,在需要灵活性的场景里,GPU的优势就出来了。
GPU可以通过软件更新支持新算法,ASIC一旦做出来,功能就比较受限。
所以在研发、原型验证和多样化应用里,GPU更有优势。
但ASIC有贬值快的问题,新一代产品出来,旧设备价格暴跌,残值非常低。
| 成本类型 | ASIC | GPU | 优势方 |
| 初始成本 | 极高 | 低 | GPU | | 运营成本 | 低 | 中等 | ASIC | | 折旧成本 | 极高 | 中等 | GPU | | 转售价值 | 极低 | 高 | GPU | | 大规模 TCO | 低 | 高 | ASIC | | 小规模 TCO | 高 | 低 | GPU |
GPU的成本结构更灵活。高端的RTX 4090大概1700到2000美元,中端产品只要500到1000美元,而且保值率不错。
GPU的通用性让它生命周期结束之后还能转卖或者改做其他用途,4-6年的使用寿命比ASIC长很多,还能保留40-60%的残值。
从投资回报周期来看,稳定大规模应用里ASIC只要12-18个月就能回本,GPU需要18-24个月。
但考虑风险因素,ASIC是高风险,GPU是中等风险。
一句话总结:大规模长期运营ASIC有成本优势,小规模短期应用GPU更合适。
5. 总结:该怎么选?
最后给大家一个简单的选型结论:
| 场景 | 选 ASIC 还是 GPU? |
| 大规模稳定挖矿 | ASIC | | 中小规模挖抗 ASIC 币种 | GPU | | 大模型训练开发 | GPU | | 量产级 AI 推理部署 | ASIC | | 科研 / 通用计算 | GPU |
说白了,路线已经很清晰了:
需求固定、大规模量产 → ASIC拿走性能和能效王冠
需要灵活多变、快速迭代 → GPU仍是不可替代的王者
未来的算力世界,一定是ASIC和GPU各司其职,共同推动AI向前发展。










评论区
登录后即可参与讨论
立即登录