当量子纠错迈入“百比特”仿真时代,如何利用AI与高性能计算跨越理论鸿沟,为容错量子计算的最终落地按下“加速键”?
谈及商用、具备容错能力的量子计算未来,量子纠错这一棘手难题始终是首要攻关目标。作为量子计算基石的量子比特(qubit)脆弱且易受干扰,极易发生退相干,导致系统计算出现错误;而频繁出错的计算系统,本身不具备实用价值。
量子纠错(QEC)研究的核心是逻辑量子比特。它通过将多个物理量子比特进行纠缠构建而成 —— 物理量子比特的量子态极易被光、声或其他量子比特运动等环境噪声破坏,而逻辑量子比特则能在保护物理比特的同时,实现错误检测与纠正。
目前,全球正开展大量研究,力求让量子纠错技术更易落地、更具可扩展性。我们此前已报道过微软、谷歌、亚马逊云科技(AWS)等企业在量子芯片量子纠错领域的多项进展。
ModAI 公司全栈工程师贾纳基拉姆·萨里帕利表示,这些案例正是量子纠错研发范式正在发生转变的体现。该公司利用人工智能、大语言模型与机器人技术开发商用工具。
“如今,这一领域正经历关键转型。” 萨里帕利写道。他指出,早期量子系统需要成百上千个物理量子比特,才能构建出一个稳定可靠的逻辑量子比特,规模问题是核心挑战。“这种巨大开销,正是容错能力长期以来看似遥不可及的原因。而现在,这一认知正在改变。近期技术突破,正让容错从抽象理论走向真实硬件设计。研究人员不再纠结于‘纠错是否可行’,而是聚焦‘如何高效实现纠错’。”
引入经典计算系统与人工智能
本月早些时候,来自亚马逊云科技、Quantum Elements、南加州大学与哈佛大学的科学家联合发表研究成果:他们运用数字孪生技术与云端高性能计算(HPC)系统运行仿真模型,为量子纠错研究提速。
这一成果也进一步凸显了经典高性能计算、人工智能与软件在量子纠错研发中的关键作用。
科学家们写道:“该成果让贴合硬件真实噪声特性的电路仿真,在以往无法企及的实验级规模上变得实用,也让基于经典云基础设施开展量子纠错数字孪生常规研究成为可能。由于工作流效率足够高、可大规模运行,还能生成高保真度的校验数据,用于开发和验证更强大的解码器 —— 这是进一步抑制逻辑错误、提升量子纠错码性能的关键抓手。”
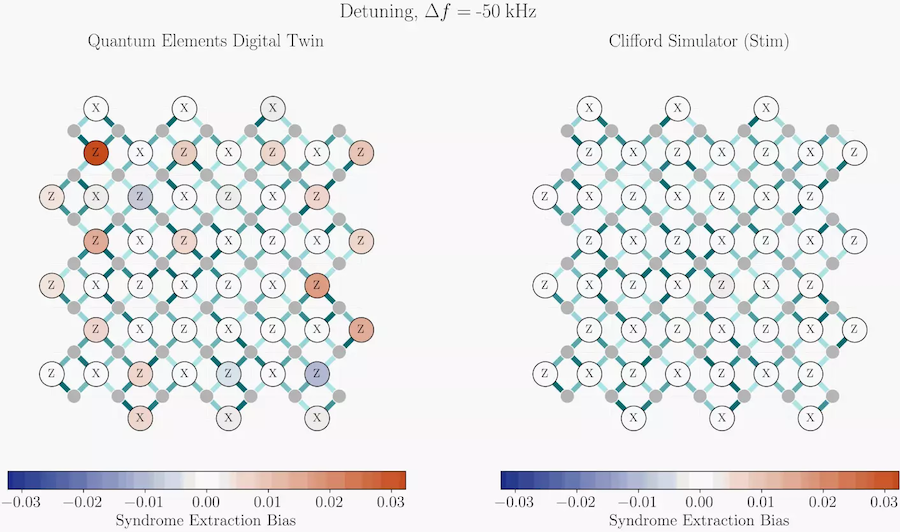
这项研究的核心,是初创公司 Quantum Elements 的人工智能数字孪生技术,以及由 AWS ParallelCluster 集群管理工具调度的 AWS EC2 Hpc7a 实例。研究团队成功对包含 97 个物理量子比特的7 阶旋转表面码完成量子主方程仿真。
7 阶表面码是一种量子纠错方案,物理量子比特按二维晶格排布,需要 97 个物理比特,远超传统经典系统开放系统仿真的能力范围。借助 Quantum Elements 的数字孪生能力与配备 96 个虚拟 CPU 的云端高性能计算集群,研究团队仅用单个计算节点、75 分钟便完成仿真,还能更精准捕捉相干噪声与关联噪声 —— 这些正是克利福德门仿真器等传统模型会遗漏的特性。
Quantum Elements 联合创始人兼首席执行官伊扎尔·梅达尔西表示,这是量子纠错领域的重要一步。
“如今,我们已经能在高度贴合真实场景的环境中,加速量子纠错技术研发。” 梅达尔西在接受《The Next Platform》采访时说,“你可以调整参数,适配不同硬件平台;还能研究更高级的特性与量子纠错策略,比如 qLDPC 码。”(qLDPC 即量子低密度奇偶校验码,是一类重要的量子纠错码。)
弥补现有方案的缺陷
研究团队采用南加州大学开发的实时量子蒙特卡洛算法,对 7 阶旋转表面码执行量子主方程仿真。该算法通过有限条随机轨迹进行压缩,降低内存与算力开销,从而加速主方程数字孪生仿真。团队构建的电路包含 228 个单比特哈达玛门、168 个纠缠双比特门,共分为 8 个电路层,将数据比特与辅助比特(“辅助量子比特”)结合在一起。
科学家表示,该方案弥补了其他基于数字孪生的主方程仿真技术的短板。
克利福德仿真器等替代方案速度更快,也能提取用于检错、纠错的校验统计数据,以及数据比特上的真实错误,但存在明显取舍。
他们写道,克利福德仿真器要求量子比特噪声以适配框架的形式表达,容易遗漏相干效应与相位敏感效应;张量网络方法则依赖近似收缩与截断处理,导致计算成本与保真度波动,同样可能丢失噪声行为特征。此外,这类方法在仿真超过 15~20 个量子比特时,难度会急剧上升。
97量子比特里程碑
“如果采用所谓‘暴力计算’,仿真上限大概只有 20 个含噪量子比特。” 梅达尔西说,“但通过数学方法压缩计算规模,我们能远超这一限制,达到行业公认极具关键意义的规模 ——97 量子比特。97 比特足以实现 7 阶表面码,这个规模足够突破阈值性能,能够模拟代表当前顶尖水平的大型系统。”
在如此大规模的数字孪生中,研究人员可以纳入量子比特间串扰等效应 —— 也就是 “相邻比特如何相互影响”,从而构建高保真度的计算系统设计,用于训练下一代解码器,快速推进量子纠错研发。
“一旦能够仿真并构建如此大规模的数字孪生,我们就不必再坐等硬件成熟后才开始研发量子纠错策略,而是可以与硬件研发并行推进。当硬件发展到足以支撑大规模量子纠错的成熟阶段时,对应的解码器与纠错策略也已完善,从而加速容错量子计算的落地。” 梅达尔西说。
加速研发进程
他表示,科学家们公布的这项研究只是第一步,加速与规模化这类计算始终是核心目标。与此同时,该工作也为量子纠错发展迈出关键一步:将人工智能融入其中,助力实现目标。
“人工智能真正深度参与的最大障碍之一,是数据生成。” 梅达尔西说,“当下用于训练机器学习、人工智能模型的硬件系统,本质上还是两三年前的设计。如何构建面向未来的研发路径?”
这项研究的重要性,既体现在规模上,也体现在效率上。如今相关工作只需一个多小时即可完成;而借助人工智能驱动的数字孪生,只需增加资源就能进一步提速。
“如果能将系统配置调整为未来形态,反复开展训练,那么我们虚拟构建的模型、解码器与纠错策略,就会与一两年后硬件的实际水平完全匹配。” 他说,“在无法直接使用未来硬件的前提下,这是我们唯一能加速研发、唯一能训练并构建适配未来系统的原生机器学习与人工智能方案。”








评论区
登录后即可参与讨论
立即登录