同样的GPU,推理速度提升8.3倍;80页合同,AI不用OCR就能读懂并回答问题——这些不是实验室PPT,而是小米AI团队刚拿到ACL 2026录用的7篇论文背后的真实技术突破。
ACL(Annual Meeting of the Association for Computational Linguistics)是计算语言学与自然语言处理领域国际公认的顶级学术会议,CCF-A类。本届会议将于2026年7月在美国圣地亚哥举行。小米AI团队共有7**篇**最新研究成果入选,其中主会长文3篇、Findings长文4篇。
这**7篇论文不是7**个孤立的学术发表,而是一张完整的技术拼图。 从最底层的端侧推理优化(VecInfer),到感知理解层的多页文档理解(Doc-V*)、长上下文注意力机制(Attention Basin)和通用信息抽取方法(ProUIE),再到交互层的对话语音生成(ZipVoice-Dialog)和手机Agent评测(MobileBench-OL),最后到训练底座层的Agent训练策略(STEP)——从芯片到应用,小米AI能力栈的每一层都有论文撑着。
论文简介
****▍****《VecInfer: Efficient LLM Inference with Low-Bit KV Cache via Outlier-Suppressed Vector Quantization》****
合作者单位:中国科学院信息工程研究所
论文作者:姚丁钰,杨晨旭,佟政阳,林政,刘伟,栾剑,王伟平
录用类型:主会长文
论文链接:https://arxiv.org/pdf/2510.06175
项目链接:https://github.com/ydyhello/VecInfer
今年3月,谷歌一篇KV cache压缩论文TurboQuant引发全球存储芯片股价单日暴跌数百亿美元,让“KV cache压缩”从学术名词变成财经热搜。VecInfer研究的正是同一核心问题——如何让大模型“记忆”更省空间、推理更快。
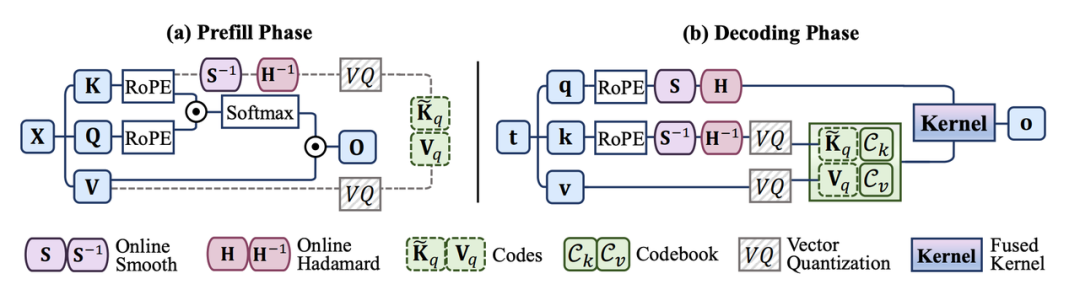
大模型长上下文推理中,KV cache的显存占用是核心瓶颈。现有矢量量化方法在超低比特下受异常值干扰严重且部署效率不足。VecInfer通过smooth与Hadamard双变换抑制异常值,并设计计算与反量化融合的CUDA kernel提升部署效率。与TurboQuant的标量量化路线不同,VecInfer采用矢量量化方案,在超低比特下实现了更优的精度-效率平衡:2-bit下接近全精度性能,196k上下文的Llama-3.1-8B上实现2.7倍注意力加速与8.3倍端到端延迟降低。
通俗地说,同样的GPU可以处理更长的对话、同样的手机芯片可以跑更强的模型。你手机上的小爱同学,未来可以记住整本小说的上下文跟你聊,而不是聊三轮就“失忆”——这正是小米端侧AI战略的关键底座。
****▍****《Doc-V*: Coarse-to-Fine Interactive Visual Reasoning for Multi-Page Document VQA》****
*表示共同第一作者
合作者单位:华中科技大学、复旦大学
论文作者:郑元雷*,付培*,李航,王资洋 ,张誉译,阮文宇,张晓今,魏忠钰,罗振波,栾剑,陈伟,白翔
录用类型:主会长文
合同审阅、财报分析、学术文献检索——这些需要翻阅大量多页文档的工作,正是AI落地的高价值场景。但现有方案的短板很明显:端到端模型一次性处理全部页面计算成本高且存在“中间信息丢失”,RAG方法依赖静态检索容易遗漏关键证据。
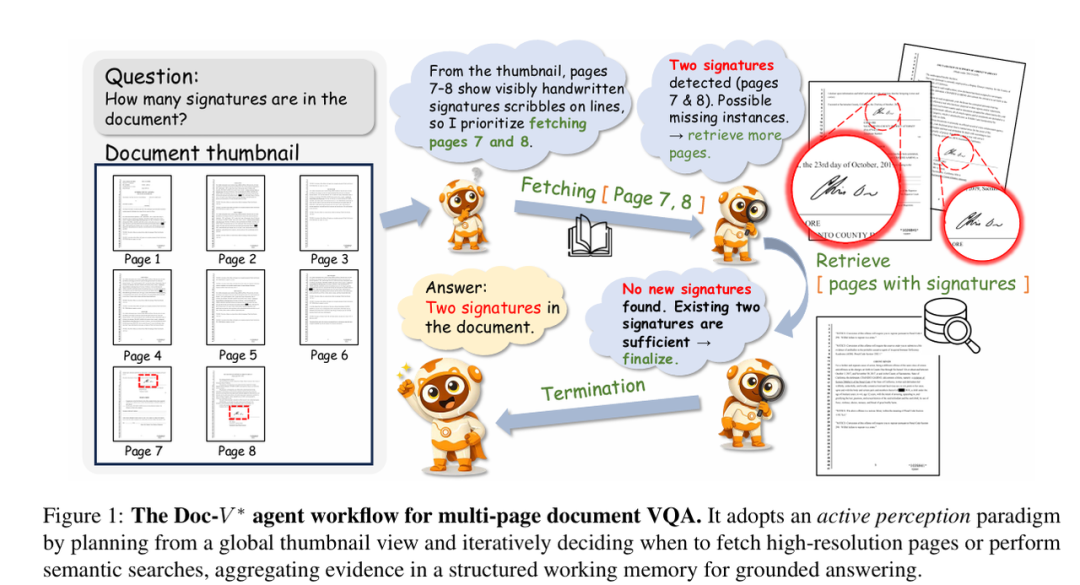
Doc-V*提出OCR-free的主动感知范式,让AI像人类专家一样按需翻阅、动态检索、跨页整合,无需OCR、无需闭源模型,即可实现接近GPT-4o级别的理解能力。在四个公开基准上取得开源最优,长文档场景(>80页)相比RAG基线提升9.8个百分点,且GPU峰值显存显著降低。
就好比你扔给它一份80页合同,它能像资深律师一样来回翻、交叉比对,不需要OCR,直接“看图”理解——当前开源最强。对金融、法律、企业知识管理等行业而言,这是一条低成本、可落地的文档自动化路径。
****▍****《Attention Basin: Why Contextual Position Matters in Large Language Models》****
*表示共同第一作者
合作者单位:中山大学(深圳)
论文作者:易子皓*,曾德龙*,凌振清*,罗皓灏,徐辙,刘伟,栾剑,曹晚霞,沈颖
录用类型:主会长文
论文链接:https://arxiv.org/pdf/2508.05128
“Lost in the Middle”——大模型对长文本中间位置的关键信息视而不见,这个问题困扰了整个行业。现有方案要么靠不稳定的启发式重排,要么引入高昂的重排序与微调成本。花了大价钱买了更长的上下文窗口,结果模型只认真看开头和结尾?
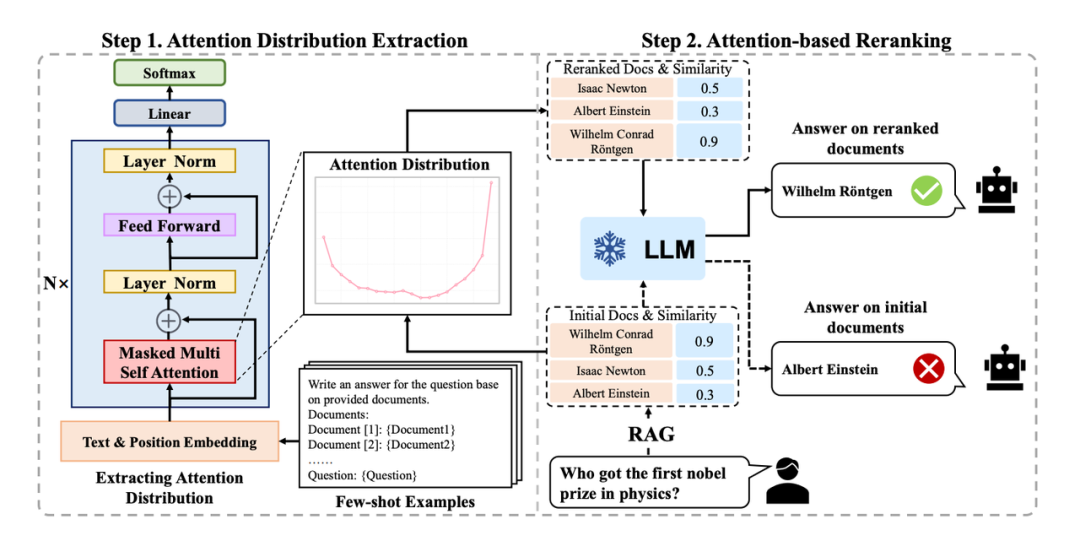
本文首次从注意力机制层面揭示其根源:模型天然形成“U型注意力盆地”,且该偏置源于对语义块边界的结构性感知而非绝对位置。据此提出的AttnRank,仅需一次低成本注意力**画像**采集,通过轻量文档重排将关键信息置于注意力高峰位置,无需训练、零额外延迟、兼容主流加速框架,在10种架构上均一致提升性能。
不换模型、不加算力,只在输入端做一次智能排序,长文理解就能显著提升——这可能是今年“性价比”最高的一篇论文。对于小米AI助手、车载语音、智能家居中枢等产品,这意味着无需升级模型或增加算力,现有模型就能理解更准、回答更稳。
**▍****《ZipVoice-Dialog: Non-Autoregressive Spoken Dialogue Generation with Flow Matching》**
论文作者:朱涵,康魏,郭理勇,姚增伟,匡方军,庄伟基,李肇庆,韩志峰,张栋,张鑫,宋星辰,叶凌轩,林珑,Daniel Povey
录用类型:Findings 长文
论文链接:https://arxiv.org/pdf/2507.09318
项目链接:https://github.com/k2-fsa/ZipVoice
从Google NotebookLM的AI播客到各类智能客服,对话式语音生成正在成为内容创作新风口。但让AI自然地“对话”——在两个说话人之间流畅切换音色和节奏——远比让AI“朗读”困难。现有自回归模型普遍推理慢且不稳定。
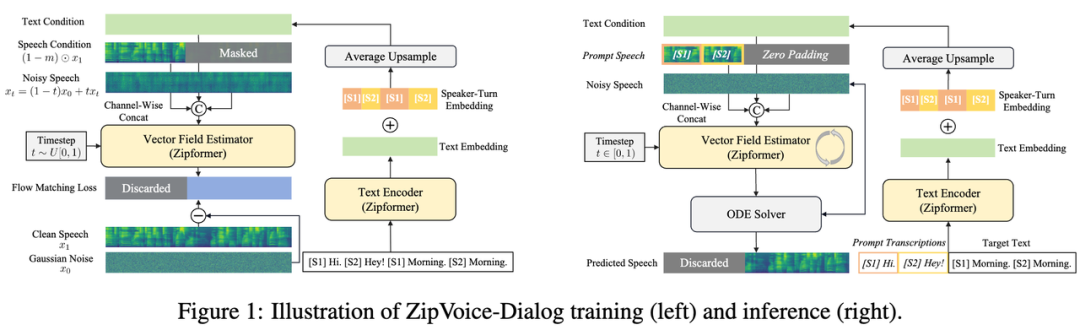
ZipVoice-Dialog基于Flow-Matching实现非自回归对话生成,通过课程学习策略保证语音文本对齐,并引入说话人轮替嵌入实现精准切换,还支持立体声生成。实验表明,在推理速度、可懂度、切换准确率和音色相似度上均显著优于自回归基线。
可以实现让AI两个人自然对话——不是一人一句的机器人感,而是有打断、有节奏、有音色切换的真实对话。团队还顺手开源了首个6800小时规模的对话语音数据集OpenDialog,直接给全行业送了一份大礼。这是小米AI语音交互体验持续进化的重要技术储备。
**▍****《MobileBench-OL: A Comprehensive Chinese Benchmark for Evaluating Mobile GUI Agents in Real-World Environment》**
*表示共同第一作者
合作者单位:北京大学、香港中文大学
论文作者:吴沁倬*,杨智卓*,李翰豪,高鹏至,刘伟,栾剑
录用类型:Findings 长文
论文链接:https://arxiv.org/pdf/2601.20335
项目链接:https://github.com/xiaomi-research/mobilebench-ol
“帮我订一张明天去上海的机票”“把这张图发到家庭群”——让AI替你操作手机完成任务,是今年最火的Agent应用方向之一。但现有手机Agent到底能用到什么程度?之前的评测主要关注指令遵循,忽略了复杂推理、自主探索与对弹窗、延迟等真实环境噪声的鲁棒性。
MobileBench-OL覆盖80款中文主流应用的1080个任务,通过基础能力、长尾应用、长时任务、GUI推理、噪声鲁棒五个子集系统评估代理能力,并提供带设备重置机制的自动化评估框架。
小米主导的这份“手机Agent体检报告”,第一次把行业的真实水平摊到桌面上:最强**AI**面对20步以上的手机操作,成功率不到两成,碰到弹窗干扰更是大幅下降。知道差距在哪,才知道往哪使劲——这些数据清晰地勾勒出从“demo能跑通”到“日常可依赖”的距离,也为小米手机Agent的研发提供了精准的优化方向和评测标尺。
**▍****《STEP: Success-Rate-Aware Trajectory-Efficient Policy Optimization》**
合作者单位:中国人民大学、武汉大学
论文作者:陈雨涵,刘宇轩,张龙,高鹏至,栾剑,刘伟
录用类型:Findings 长文
论文链接:https://arxiv.org/pdf/2511.13091
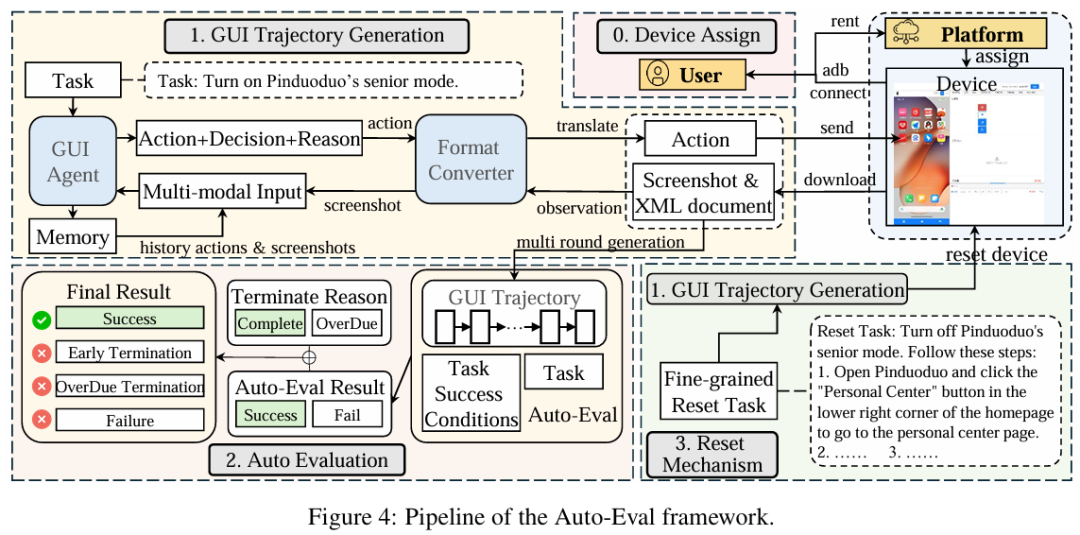
训练一个能在手机上帮你完成复杂操作的AI Agent,每一次试错都需要真实执行、等待环境反馈,成本远高于训练普通聊天模型。现有轨迹级优化方法还存在三大瓶颈:对不同难度任务“一刀切”采样、失败轨迹中正确步骤被误罚、多轮交互采样成本高。
STEP用“先挑难题练、再按步骤学”的策略破解这些问题——通过任务成功率感知的自适应重采样将训练资源集中于困难任务,同时将轨迹拆解为步级样本进行细粒度优化。在OSWorld和AndroidWorld基准上,同样的计算预算下收敛更快、泛化更强。
通俗地讲,训练手机Agent每次试错都要真机执行,成本远高于训练聊天模型。STEP的做法是“先挑难题练、按步骤学”,同样预算训得更快、泛化更强。这项技术对小米正在推进的手机Agent、车载智能助手等产品有直接的工程价值,让Agent从“能力可行”走向“训练可持续”。
**▍****《ProUIE: A Macro-to-Micro Progressive Learning Method for LLM-based Universal Information Extraction》**
*表示共同第一作者
论文作者:刘文达*,宋志刚*,聂帅,刘光耀,陈立崧,杨滨语,陈亚冉,周鹏,王洪振,刘宇宸,胡文月,许家铭,史润宇,黄英
录用类型:Findings 长文
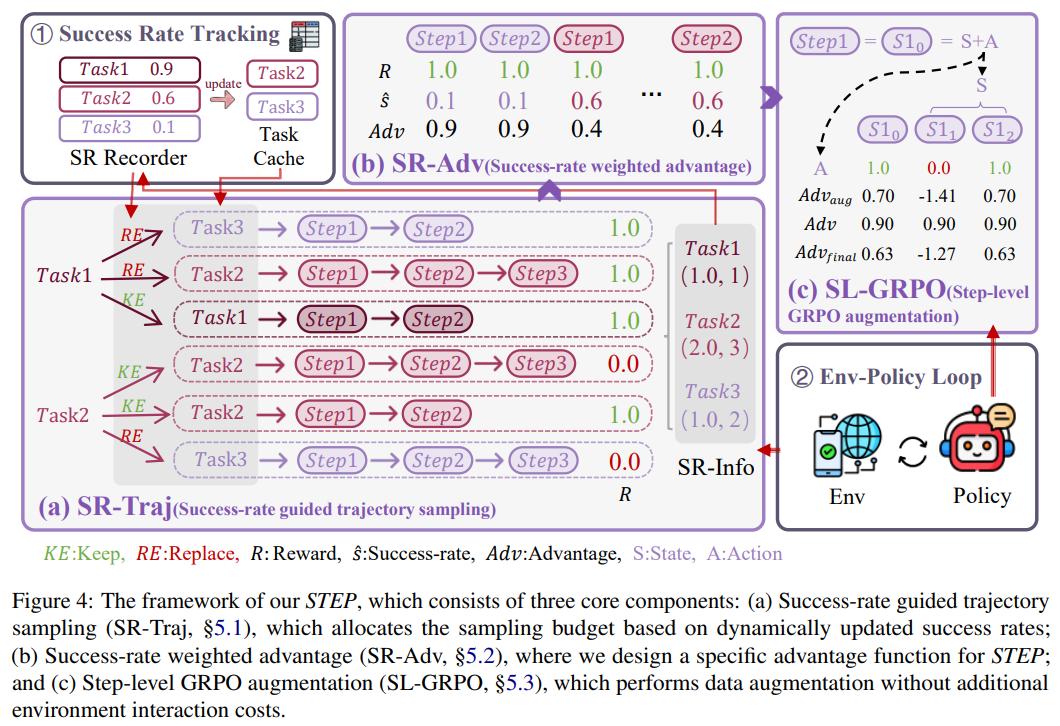
随着大模型加速走向产业落地,信息抽取正从“单任务、重工程”迈向“统一建模、低成本泛化”。但现有通用信息抽取方法往往依赖额外知识、复杂对齐或外部资源,训练更重,收益却未必成正比。
我们提出一种从宏观到微观的渐进式学习框架(ProUIE),在不引入任何外部信息的前提下,分三阶段提升统一信息抽取能力:先建立统一抽取基础,再精简结构化输出,最后结合带细粒度奖励的GRPO做深度探索。在36个公开数据集上,ProUIE稳定提升效果,以更小的4B骨干超过多种强基线。
这项工作的价值在于:不用额外“喂”更多外部信息,也能把实体、关系、事件抽取得更准、更稳,因此更适合真实业务中的文本知识挖掘与结构化信息处理任务。对手机 AI 助手来说,这意味着它可以更准确地理解用户设备内的文本数据,挖掘其中的结构化知识,并进一步沉淀为可用记忆,从而直接支撑搜索问答、日程出行等业务落地。
从底层推理优化到上层Agent协作,从多页文档理解到对话语音生成——这7篇论文不只是学术履历上的数字,它们正在成为小米产品体验进化的技术底座。ACL 2026,圣地亚哥见。






评论区
登录后即可参与讨论
立即登录