近日,小米在 CVPR 2026 NTIRE 赛事中荣获三项奖项。其中,小米玄戒多媒体算法团队斩获高效超分辨率赛道冠军,小米大模型应用团队夺得人像修复赛道冠军与反光消除赛道亚军。
NTIRE(New Trends in Image Restoration and Enhancement)由 CVPR 组委会承办,是全球规模最大、水平最高的图像恢复与增强领域学术研讨会。小米在本次赛事中展现了从硬件优化到生成式视觉算法的技术深度。
01
高效超分辨率,推理速度与重建质量的双重领先
▍Efficient Super-Resolution Challenge
NTIRE 高效超分辨率挑战赛要求参赛团队在严格保持图像重建质量下限前提下,进一步压缩推理耗时、参数量与计算量,推动在手机、边缘设备等资源受限场景下的真实落地。此外,本届比赛进一步强化推理速度(Runtime)在综合评分中的权重。
在本届比赛的最终评估中,小米**玄戒**多媒体算法团队依托在芯片多媒体影像算法领域的软硬融合方向持续积累,凭借 SPANV2以综合得分4.43的显著优势位列第一,在推理速度、计算量、参数规模之间取得了出色的整体均衡。
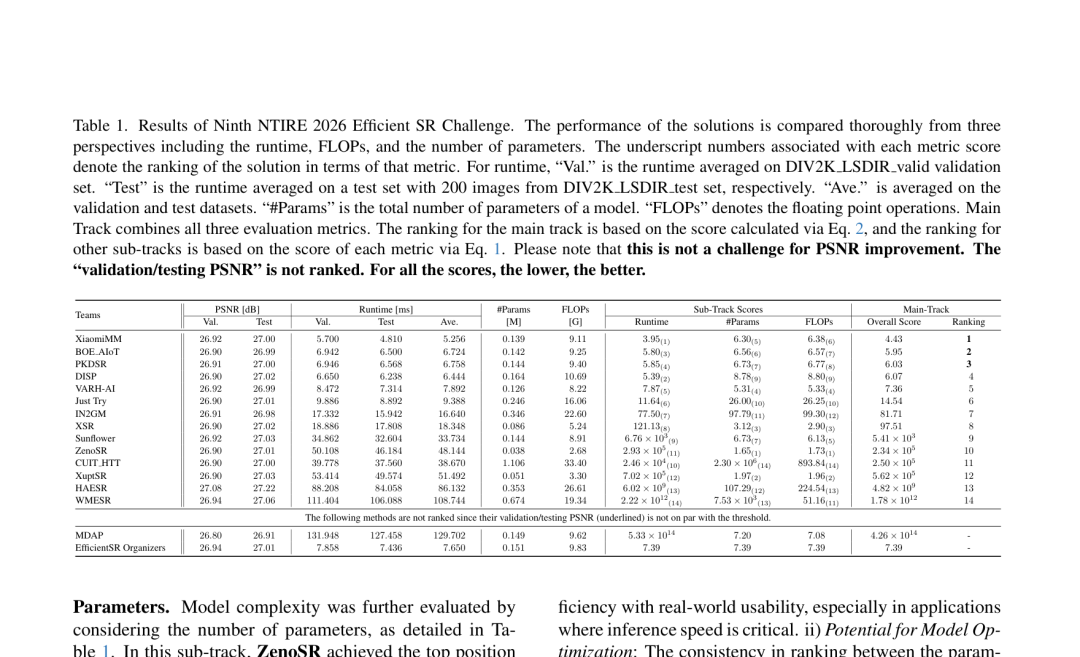
NTIRE 2026 Efficient SR Challenge 最终排行榜:XiaomiMM(SPANV2)综合得分4.43,位列第一
在这个赛道,小米玄戒多媒体算法团队延续了上一届冠军方案 SPAN(Swift Parameter-free Attention Network)的技术路线,提出了全新一代方法 SPANV2,从算法结构与硬件执行两个层面同时发力,在精度几乎无损的情况下将推理延迟再次大幅压缩。
▍SPANV2:从「受控残差更新」出发的新一代高效超分网络
与上一代 SPAN 相比,SPANV2的改动集中在两处:一是让网络在修复图像时不再套用一种固定策略处理全图,而是能根据画面内容自适应判断哪里需要精修、以什么方式精修;二是把 GPU 在注意力计算中原本需要三次读写显存的步骤合并为一次完成,省下了大量重复的数据搬运开销。两点叠加,使模型在画质几乎无损的前提下,推理速度再次被显著提高。
团队将高效超分的设计问题重新抽象为一个受控残差更新(Governed Residual Update)框架:网络中的每一个基本模块都被拆解为两个解耦的阶段——先由一个轻量分支生成候选修正(candidate correction),再由一个显式的「调控器(governor)」决定这份修正应以何种方式、在多大程度上被注入到后续传播路径中,相当于每个模块都在做“提方案、再过审”两步走。在这个统一视角下,上一代 SPAN 对应于调控器为解析、无参数形式的最经济实例,把关逻辑是一条固定规则;SPANV2则在同一宏观结构下,用一个轻量可学习的通道混合调控器替换了原有的解析映射,让“准入”过程具备内容自适应性和跨通道建模能力,判断更细腻,也更贴合画面本身的特点,且仅引入极少量额外参数。
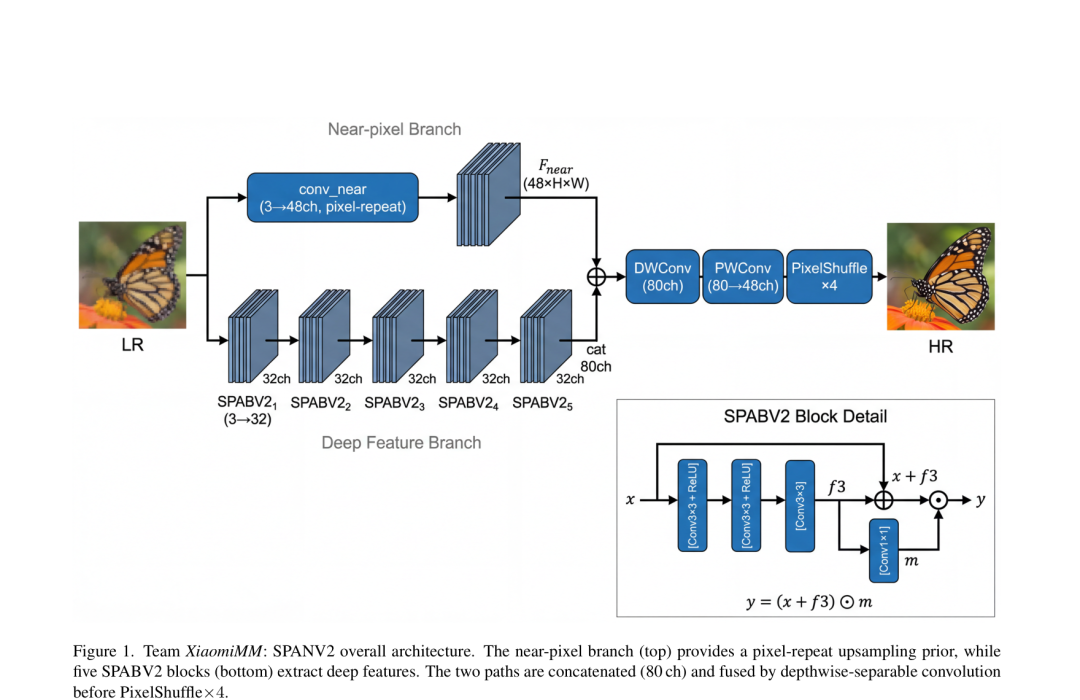
SPANV2整体架构:上方 near-pixel 分支提供像素重复的上采样先验,下方5个 SPABV2模块负责深度特征提取,两路通过深度可分离卷积融合后经 PixelShuffle×4完成重建
围绕这一核心思想,SPANV2在工程实现上做了三处关键重构:
1.可学习的通道混合注意力**。**原 SPAN 的注意力完全由两个中间特征的逐元素乘积得到,只能“挑出要加强的部分”,且通道之间互不相干,表达能力受限于「非负」与「通道独立」两个隐含约束。SPANV2的 SPABV2模块将其替换为一个 C×C 的1×1可学习投影,注意力图既可以取负值,也能显式建模通道之间的互补、抑制与补偿关系,像是从单色画笔升级成一整套调色盘——参数几乎没多花,重建质量却能再上一层。
2.融合算子 span_attn_op。团队通过深入的性能画像发现,对小型高效超分网络来说,真正的性能瓶颈并不在 FLOPs,而在显存带宽——注意力步骤中三次读写 C×H×W 的特征张量带来了大量冗余的 DRAM 往返,相当于把同一批数据在显存里反复搬进搬出三趟。为此,团队手写了一个专用算子,将1×1注意力卷积、逐元素加法和逐元素乘法三步融合进一个 kernel,并结合共享内存缓存、float4向量化加载、寄存器级特征复用与循环展开等手段,把原本重复三次的搬运压到一次完成——GPU 开一次“货箱”就干完所有活。对本来就轻量的模型来说,搬运省下的时间比计算省下的还要来得实在,这也是 SPANV2在推理延迟上拉开差距的一项底层优化。
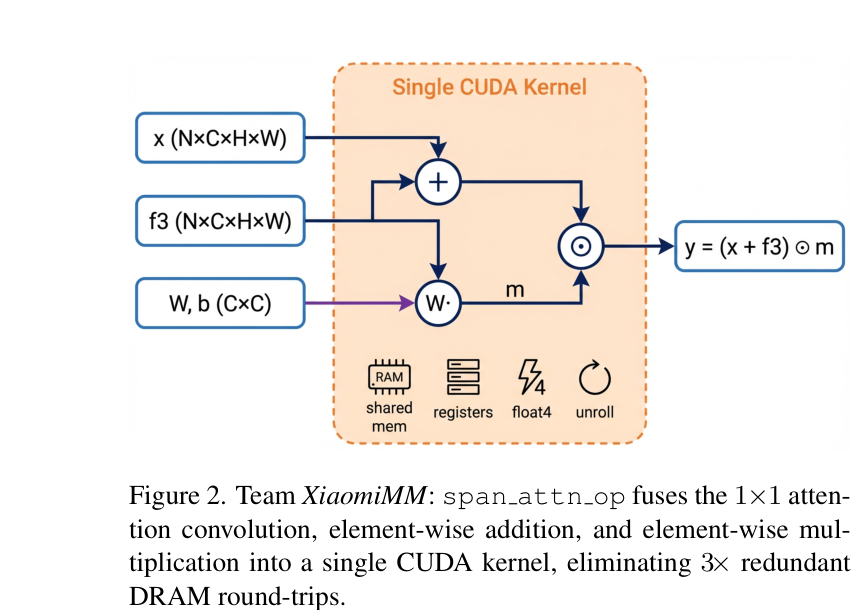
span_attn_op 将1×1注意力卷积、逐元素加法、逐元素乘法融合为单个专用算子,把原本重复三次的数据搬运压缩到一次
3.近邻**像素**上采样分支。 自然图像里,天空、墙面、光滑物体表面这类低频区域占了绝大多数能量,其实并不需要“修”,直接放大就够用。团队因此在主干之外并行引入一条极轻量的深度可分离分支,权重初始化为精确的最近邻上采样,相当于给低频部分开了一条“直通车”;网络在训练初期就天然带有这个强先验,主干分支得以把容量集中用于头发、毛发、纹理和边缘这些真正需要精雕细琢的高频残差。
完整的 SPANV2仅含0.139M 参数、32个特征通道、5个堆叠的 SPABV2模块与一个近邻上采样分支,换算下来模型体积只有几百 KB,纯 CNN 架构不依赖特殊硬件,主流手机芯片的图像 ISP/NPU 都能直接跑起来——这意味着用户体验中多了一项悄悄生效、不拖慢快门、也不多占内存的底层能力。
值得一提的是,SPANV2的平均推理耗时(5.256 ms**)在本届比赛的提交方案中明显领先,相比去年的 SPAN 基线进一步降低了超过30%。官方报告在总结本届赛事时特别指出:「XiaomiMM 通过自定义融合专用算子,揭示了在高度优化的轻量级网络中,性能瓶颈越来越多地来自内存带宽而非算术复杂度,低层级的硬件-软件协同设计正在成为高效超分研究中不可或缺的维度。」算子级硬件感知优化**也由此在本届获奖方案中显现为一项重要的差异化能力。
5.256毫秒的单帧耗时,折算下来一秒能处理近200帧,比上一代再快约三成。拍摄时,取景预览会更跟手,连拍和视频超分也能稳住更高的帧率,后台处理一张照片的耗电也跟着下降。照片变清楚是肉眼能看见的部分;更省电、更少等待,是看不见但同样实在的那部分。
02
人像修复,还原高清细腻画质
人像修复任务旨在将真实世界中退化的低质量人脸图像,恢复为高质量且富含细节的图像。该任务面临三大核心挑战:人脸结构缺失、高频细节缺失以及人物特征难以保持。其本质是在“细节补全”与“身份保持”之间寻求最佳平衡。
小米大模型应用团队提出了双阶段级联框架 + 单步扩散细化的技术方案,从全球参赛队伍中脱颖而出,荣获第一名(Team name: MiPlusCV),在无参考图像质量与身份一致性综合评测中全面领先!
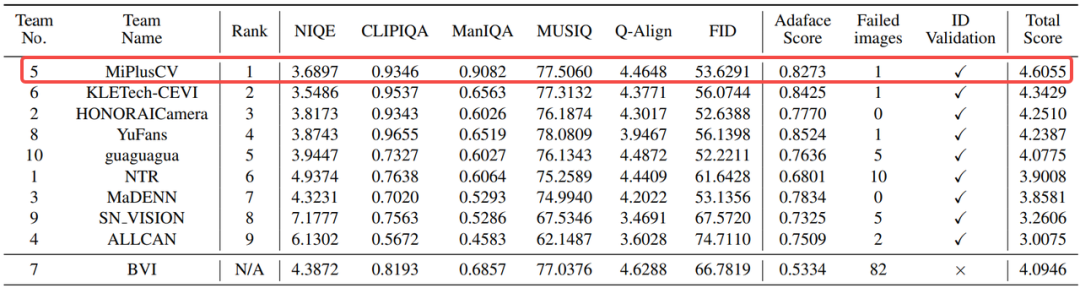
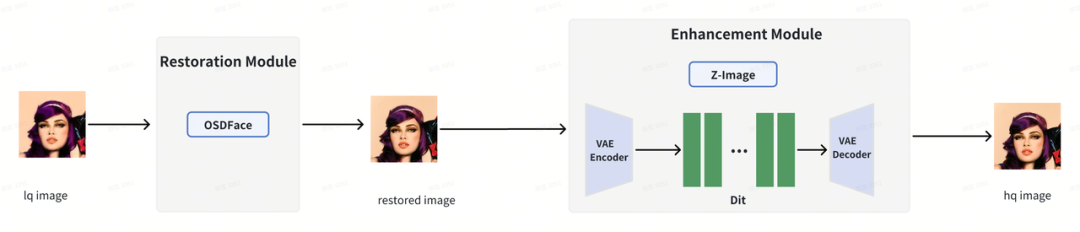
▍层层递进修复:先修对,再修像,后修美
真实世界中的老照片、模糊、压缩损伤、噪声和低分辨率往往属于复合退化,若直接一步生成,容易出现结构漂移、人脸失真甚至身份变化。为此,团队采用了更稳健的双阶段设计:
-
第一阶段:基于 OSDFace 进行粗修复与结构恢复,重点解决五官布局恢复、严重退化修正和整体人脸结构稳定,确保人脸结构修复正确
-
第二阶段:基于 Z-Image One-step Diffusion 进行细节增强,进一步补充皮肤纹理、发丝、边缘和高频细节,确保细节真实自然
相比单阶段方案,双阶段框架结构更稳定、身份一致性更强,在复杂真实退化场景下也展现出更优秀的鲁棒性。
如果仅依赖单一重建损失进行训练,往往容易导致图像过度平滑、人物身份漂移以及整体感知质量不足。为此,团队在训练阶段引入了多目标联合优化策略,从以下四个维度同步提升修复效果:
| 优化**维度 | Loss 函数 | 作用 | 解决的问题** |
| 像素层 | L1 Loss | 基础重建准确性 | 整体清晰度 | | 感知层 | DISTS 感知损失 | 视觉自然度 | 纹理真实感 | | 身份层 | ArcFace 约束 | 身份一致性 | “修得更像本人” | | 语义层 | DINOv2 对抗学习 | 高级语义一致性 | “修得更真实” |
在完成监督训练后,团队进一步引入了质量奖励优化机制(Reward Fine-tuning),使用多个图像质量评估模型作为反馈信号,模拟人类主观审美标准,对结果进一步优化。这一机制让模型不再局限于“技术上修复正确”,而是进一步向“人眼看起来更好”的方向靠近。
▍高性能!质量与效率双管齐下
传统扩散模型虽然生成能力强,但需数十步采样才能完成推理,成本高,难以落地。针对这一问题,团队创新性地引入了单步扩散细节增强机制(One-step Diffusion),将复杂的多步推理压缩至单步完成,在保证生成质量的同时大幅提升推理效率。
输入图
结果图
03
反光消除,让玻璃不再“抢镜”
日常拍照时,透过玻璃拍摄的照片往往会混入反光(如室内灯光、人影等),严重影响成像质量。反光消除的目标,就是从一张混合图像中恢复出干净的透射层。不同玻璃材质、角度、光照条件下的反射形态差异极大,且现实的反射图像还伴随着色偏、模糊等复杂退化。因此,反光消除是一个极具挑战性的任务。
小米大模型应用团队基于 RDNet-XL 架构,通过骨干网络升级、扩散模型知识蒸馏与渐进式多分辨率训练策略,在 CVPR 2026主观评分中荣获第二名(4.31分),同时多项客观指标位列第一。
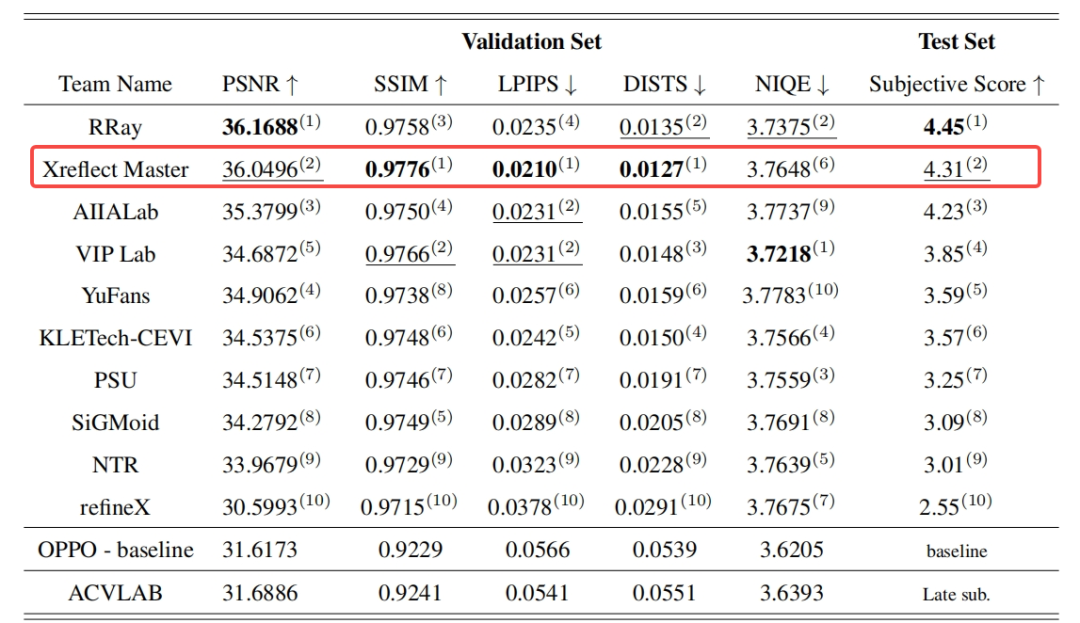
▍升级骨干网络,精准抑制反射
团队的技术路线非常清晰:以强大的骨干网络为基础,用扩散模型知识蒸馏攻克困难样本,通过渐进式训练稳定优化过程。
方案基于 XReflection 框架中的 RDNet(Reversible Decoupling Network)架构,将原始骨干从 FocalNet-L 替换为更大规模的 FocalNet-XL。这一升级带来了显著的多尺度表征能力提升和全局上下文建模增强,使模型能够更精确地抑制反射并保留细节。
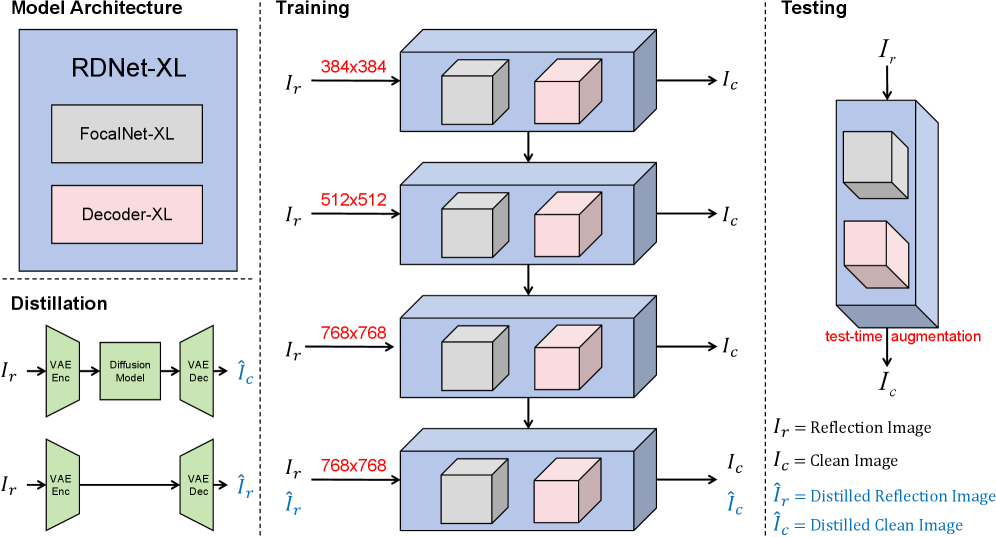
▍蒸馏扩散模型,复杂场景也能消!
针对强反射、复杂反射等困难样本,团队创新性地引入了扩散模型知识蒸馏策略:
-
困难样本生成:使用扩散模型 SOTA 方法(WindowSeat、DAI)对大规模开源图像进行反光消除,生成1000对高质量伪标签数据;
-
域对齐处理:将每张反射图像通过与扩散模型相同的 VAE 编码器-解码器处理,用重建图像作为网络输入,消除 VAE 编解码带来的域差异;
-
蒸馏训练:以扩散模型的输出作为教师信号,对已完成渐进式训练的模型进行额外蒸馏训练。
这一设计相当于将扩散模型的“生成式先验知识”注入到判别式网络中——模型获得了扩散模型处理困难反光的能力,且保持了判别式网络的推理效率,既强又快,双剑合璧。
此外,为了在大分辨率图像上实现稳定训练,团队还采用了三阶段渐进式分辨率训练策略(384×384→512×512→768×768)。这种从小到大的训练方式,使模型先学习局部反射模式,再逐步扩展至全局结构理解,有效避免了直接在大分辨率上训练的不稳定性。

输入图

结果图
人像修复、反光消除、超分辨率——三项成果覆盖了从拍摄到查看的典型影像场景。未来,小米将继续深耕影像算法领域,推动技术从研究走向产品落地,为用户带来更好的影像体验。
参考文献:
Wan C, Yu H, Li Z, et al. Swift parameter-free attention network for efficient super-resolution[C]//CVPR, 2024: 6246-6256.
技术报告:
📄 人像修复:https://arxiv.org/abs/2604.10532
📄 反光消除:https://arxiv.org/abs/2604.10321
📄 高效图像超分辨率:https://arxiv.org/abs/2604.03198







评论区
登录后即可参与讨论
立即登录