你有没有遇到过这样的尴尬?
在停车场场景下,当你对车辆说出 “小爱同学,锁车” 时,若旁边路人随口发出类似 “关闭”“停” 的语音,传统车外语音方案可能出现误触发;而当你手持物品走向车尾,说出 “小爱同学,打开后备箱” 时,受移动状态与环境噪声影响,指令也可能出现识别不完整、响应不及时的情况。
这些问题表面看是“车外太吵”,本质上其实是一个更难的技术挑战——“鸡尾酒会”**场景下的目标说话人语音识别**。
在真实车外环境中,系统面对的不是单一噪声,而是多人同时说话、声源不断移动、背景混响、语音重叠等复杂情况。传统方案往往只能做到“听到什么就转写成什么”,但无法同时解决2个难点:
1.正确区分出谁是说话的目标人、谁是干扰人,从而屏蔽掉干扰声音。
2.在用户位置移动、语音信号变化时,实现对目标人声音的“动态追踪”。
伴随新一代 SU7 的发布,我们带来了车外语音「连续说」和「边走边说」功能。两者协同,让车外语音交互第一次具备了接近人类动静态场景下的“聚焦式聆听”能力,在实际场景中解决了“鸡尾酒会”问题。
01
技术核心:目标说话人识别(TS-ASR)—— 只听你的声音
**▍**一句话理解****
以前:车外语音识别是"来者不拒",谁说话都转录、指令混在一起无法识别,让你的语音指令体验大打折扣。
现在:"屏蔽其他人声音,只听你一个人的**指令**"。
**▍**为什么这件事这么难?——鸡尾酒会场景的真正挑战****
在学术上,这类问题被称为鸡尾酒会场景(Cocktail Party Scenario):在多人同时交谈、声音交叠、噪声复杂的环境里,如何只提取识别目标说话人的内容。
这比普通语音识别难得多,因为模型不仅要“听清语音”,还要同时完成多项复杂任务:
-
区分说话人:判断混合语音里有几个人在说话;
-
处理重叠语音:当多个人同时开口时,把目标用户的声音从干扰中剥离出来;
-
理解场景属性:根据性别、音色相似度、时间段等线索逐步锁定目标;
-
保持连续识别:在用户移动过程中,持续对同一个目标进行跟踪和识别。
这也是为什么传统多模态大模型即便已经具备一定 TS-ASR 能力,在复杂场景下仍然容易“听错人”或者“漏掉关键内容”。
**▍它是怎么做到的?**
第一步:基于声纹注册,实现专属语音控车
在车机录入声纹后,只要你在车外喊出"小爱同学"那一瞬间,唤醒词语音片段背后的声纹信息会被算法精准捕获,作为本次识别的"目标音色参考"。
第二步:先思考,再识别
这正是我们技术的核心突破——受行业内知名大模型推理范式的启发,我们将思维链**(Chain-of-Thought,CoT)** 引入语音识别任务,让模型在输出指令文本前,先走一遍逻辑推理。
这种"先想清楚再开口"的方式,让模型具备了真正的推理能力:
-
现在有几个人在说话?
-
哪段声音是重叠的?
-
哪个声音才是刚才唤醒我的那个人?
-
我应该听谁的声音?
通过这种"先记住你,再只听你"的方式,即使旁边有人大声聊天、即使周围人声鼎沸,你的新一代 SU7 也能精准识别你的指令,对其他人的声音或指令充耳不闻。
02
核心架构
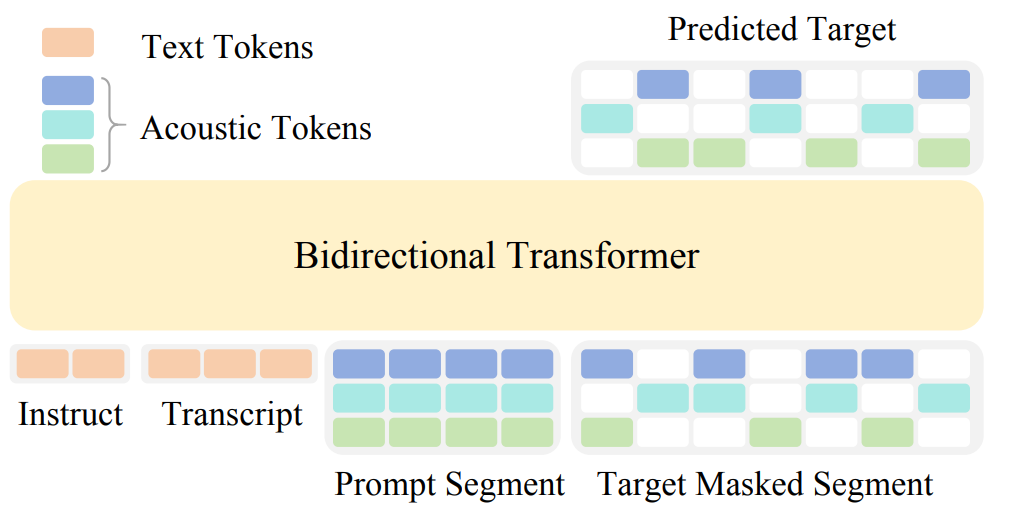
TS-ASR 大模型的结构基于 LLM 范式,由语音编码器(SpeechEncoder)和大语言模型两部分组成:
-
输入:目标音色语音(唤醒词"小爱同学")+ 静音片段 + Query(用户指令)
-
处理:SpeechEncoder 将语音模态对齐到文本模态,同时融合声纹信息与语义信息
-
输出:仅识别目标说话人的语音内容,自动过滤其他干扰
具体而言,语音编码器采用预训练的 Data2Vec2,它本身就能同时捕捉语义信息和说话人特征,无需额外的说话人编码模块;大模型主干使用轻量级的 LLM 模型,通过线性 Adapter 将语音特征投影到语言模型空间,最终以结构化格式输出推理过程和识别结果。
TS-ASR 整体架构——基于 LLM 范式,将目标说话人参考语音、静音片段与混合语音统一输入,通过 Data2Vec2 编码器 + LLM 主干完成"先推理、再识别"
03
如何训练出"会推理"的模型?——三阶段训练策略
为了进一步突破复杂场景下的目标说话人识别问题,小米 MiLM Plus 团队提出了全新的 TS-ASR 框架,并在论文《Thinking in Cocktail Party: Chain-of-Thought and Reinforcement Learning for Target Speaker Automatic Speech Recognition**》**中系统验证了这一路线的有效性。
这套新框架的核心思想可以概括为一句话:“不是直接输出识别结果,而是让模型先思考,再决定该听谁、该输出什么”。
**▍**第一阶段:打基础(TS-ASR SFT)****
全参数监督微调,让模型先掌握基本的目标说话人识别能力——这是一切的起点。
**▍**第二阶段:学推理(CoT 微调)****
用专门构造的 CoT 数据集进行微调,教会模型"分析后再作答"。每条训练样本都包含五个结构化信息:
-
音频中的说话人数量和总时长
-
目标说话人(参考语音)的性别
-
每位说话人的发言时段、性别、以及与目标声纹的相似度等级(1-5级)
-
基于以上信息的推理过程
-
最终的转录文本答案
这里有一个关键设计细节:相似度我们没有直接使用浮点数(如 0.87),而是映射成 1-5 的离散等级。实验证明,大模型更容易理解简洁的符号,而不是精确的小数——就像人类在嘈杂环境中判断"像不像"时,用"很像/有点像/不太像"来描述,远比"相似度 0.83"更直觉。
**▍第三阶段:攻难题(强化学习 RL)**
CoT 微调之后,模型还有一批"死角"——那些它始终做不对的难样本。我们使用 GRPO 强化学习算法,专门挑出模型预测错误的样本进行针对性训练,并设计了两类奖励信号:
-
识别**准确率**奖励:转录越准确,奖励越高
-
格式规范奖励:确保
<think>推理结构完整
这就像学生复习只盯着错题看——效率最高,提升最快。
04
效果有多好?
经过三阶段训练,模型在标准测试集上的表现大幅超越现有方案:
-
CoT 推理将 2 人混音错误率从 7.4% 降至 5.29%,提升约 28%——证明"先思考"确实有效
-
再加入 强化学习(RL),进一步降至 4.84%,实现行业大幅领先
-
即便在单人说话的普通场景,识别错误率也从 8.1% 降至 3.65%,推理能力实现了泛化
05
车外语音体验的整体提升
除了目标说话人识别之外,我们也在车外语音链路的其他环节做了配套优化,新增移动拾音功能(TS-Tracking)——支持在车主一边移动一边说话的情况下,动态追踪车主的声音并进行转录,共同提升复杂场景下的交互稳定性与连续性。
有了移动拾音技术加持,在车外下达语音指令时,你可以边走边说,识别算法始终跟着你、听懂你,让车外语音从"能用"到"好用"。
06
多项技术如何协同工作?
各个语音先进技术并不是孤立的——它们在车外语音系统中形成了完整的上下游配合:用户唤醒 → TS-Tracking 动态追踪声源位置 → TS-ASR 锁定目标说话人声纹 → CoT 推理分析场景 → 精准识别指令,过滤干扰 → 执行用户意图
无论你站着说、走着说、在嘈杂环境中说,系统都能:
1.跟得上你(移动拾音)
2.认得出你(TS-ASR 说话人识别)
3.听得懂你(大模型语音识别 + CoT 推理)
07
写在最后
从"听到什么转什么"到"只听你说的",这不只是技术指标的提升,更是车外语音交互体验的一次质变。
新一代 SU7 通过 「 目标说话人跟踪(TS-Tracking)与目标说话人识别(TS-ASR)」 双重能力加持 ,让车外语音交互体验真正变得聪明、精准、自由——你可以自由地在车外唤醒"**小爱同学"并下达指令,你的小米汽车**会更懂你。









评论区
登录后即可参与讨论
立即登录