• 项目主页:
https://horizonrobotics.github.io/robot\_lab/uni3R
• 文章链接:
https://arxiv.org/pdf/2508.03643
• GitHub代码**:**
https://github.com/HorizonRobotics/Uni3R
概述
在现实场景中,通常只能获取来自多个视角的RGB图像,而缺乏相机位姿、深度或点云等辅助信息。现有三维重建方法普遍存在两方面局限:一是将几何重建与语义理解解耦建模,需分别训练与优化,导致系统复杂且效率受限;二是高度依赖位姿与深度监督,才能稳定恢复几何结构。针对这些问题,Uni3R提出统一架构,将整体流程转化为可泛化的前馈推理过程,无需预先配准的相机信息。
仅需少量普通照片,模型可自动重建完整的三维场景并识别其中的物体。这一目标长期以来是计算机视觉的重要方向。然而,传统方法往往依赖耗时的逐场景优化,或将三维重建、语义理解等任务分离建模,难以同时兼顾效率与泛化能力。
我们的核心思考是,以3D Gaussian Splatting作为高效统一的三维表征基础,在同一几何表示上整合不同任务,实现几何、语义与渲染的一体化建模。基于此,我们提出Uni3R,一个面向三维重建与语义理解的统一框架。该方法能够从未经对齐的多视图图像中直接恢复完整场景,并同步建模语义信息。通过跨视角融合机制,Uni3R构建基于3D高斯的统一表示,在同一表征空间中联合编码几何结构与语义特征。
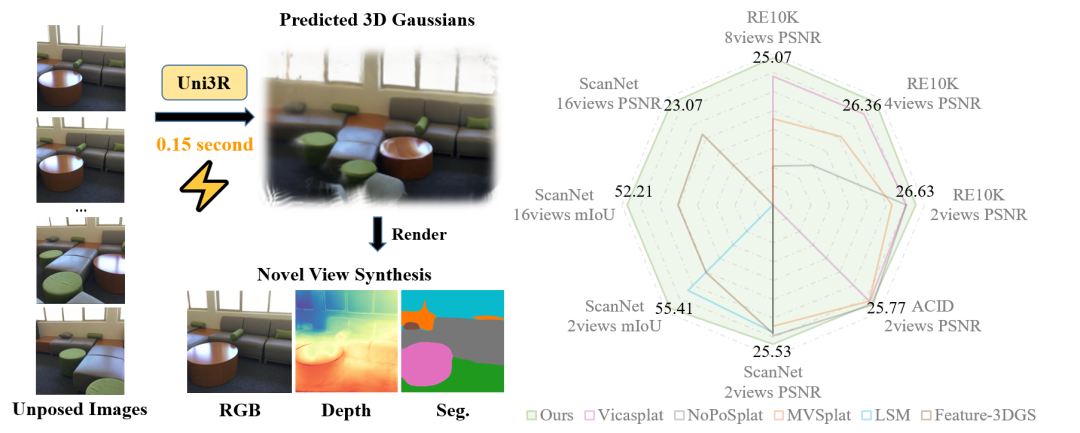
依托统一表征空间,Uni3R仅需单次前向传播(约0.15秒),即可并发完成高保真新视角合成、开放词汇三维语义分割与深度预测三项核心任务,并在多个基准数据集上达到当前最先进水平。进一步实验表明,统一多任务表征不仅显著减少了底层计算冗余,还在几何重建、视角合成与语义理解之间形成稳定的协同增益。右侧雷达图展示了Uni3R与多种现有方法在不同数据集与任务上的性能对比结果,表明该方法在各项指标上均表现出一致且领先的性能。
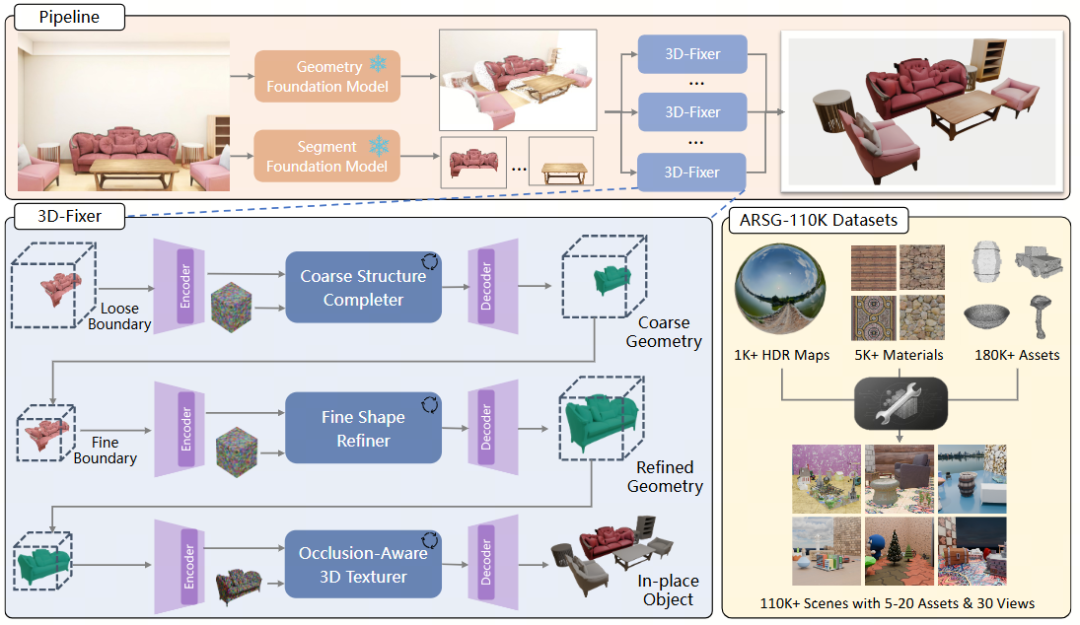
总体框架
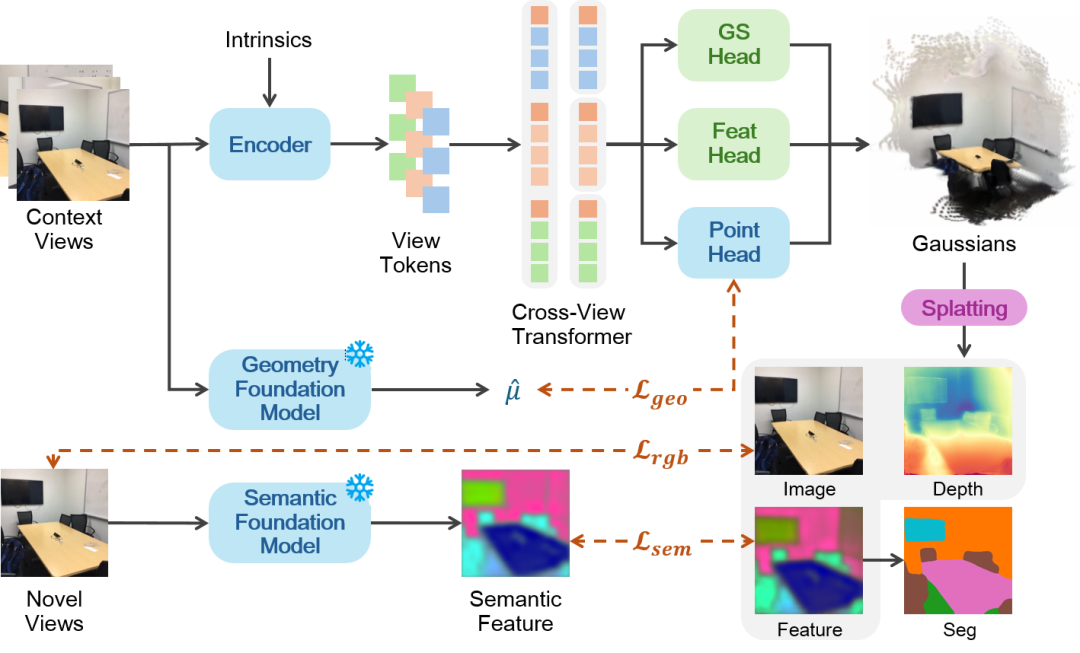
Uni3R以多视角RGB图像为输入,首先通过DINOv2编码器提取高维特征,并利用跨视角注意力机制 (Cross-View Transformer) 融合多视图信息,构建全局一致的场景表征。模型在单次前向过程中直接预测三维高斯原语 (3D Gaussian Splatting) ,该统一表示同时编码场景的几何结构、外观信息与语义特征。
为提升训练稳定性,Uni3R引入面向RGB-only监督的几何约束损失 (Geometry Loss) ,为三维表示提供额外的结构先验。基于高斯泼溅渲染,模型能够生成新视角图像、深度图及语义结果,并通过联合损失进行端到端优化,从而实现三维场景的统一重建与语义理解。
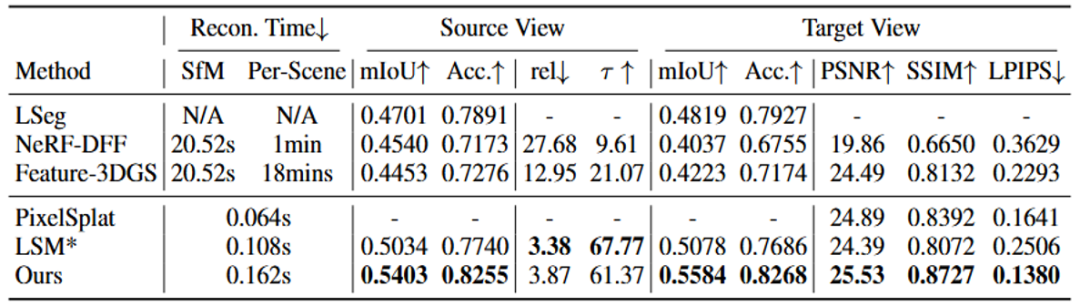
新视角语义分割
Uni3R在多项三维视觉任务中取得了当前最先进的性能,并能够生成结构一致、语义清晰的三维场景理解结果。与传统方法不同,许多模型(例如 LSeg)只能在二维图像上进行语义分割,而Uni3R则为每一个3D高斯表示赋予语义特征,从而在三维空间中构建出一个统一且稳定的语义表示。这一设计将几何结构、语义信息和渲染过程有机结合,使模型在三维空间中的语义理解更加准确、一致。
此外,一些方法(例如 LSM)在训练过程中需要依赖真实的三维点云数据进行监督,而Uni3R则不需要这样的额外标注。这使得Uni3R在实际应用中更加高效、灵活且具有更好的扩展能力,为大规模三维场景理解提供了新的解决方案。
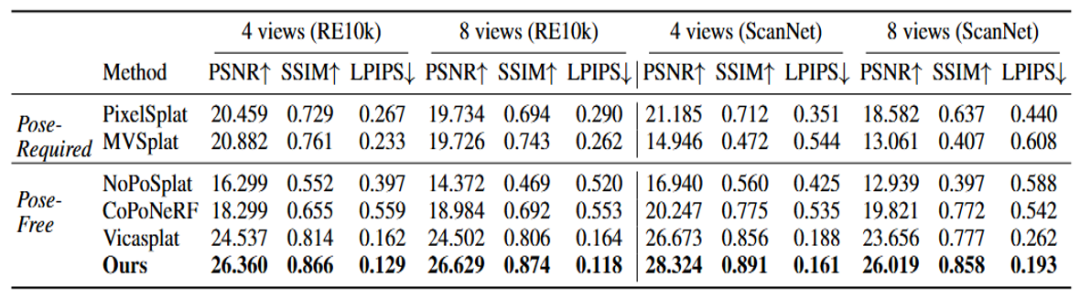
新视角图像生成
在新视角图像生成的任务中,我们的方法取得最好的效果。相比之下,NoPoSplat和VicaSplat由于在多视角生成下的3D不一致问题,产生了明显的伪影和模糊。

实验结果表明,在4视图和8视图两种设置下,Uni3R在RE10K和ScanNet等数据集上均取得了全面领先的表现。相比当前性能较强的VicaSplat方法,Uni3R在PSNR指标上平均提升约2.0dB,显示出更强的多视角信息融合能力和更好的泛化性能。
可视化如图:
总结与展望
Uni3R提出了一个全新的统一框架,使得3D几何重建与语义理解在单次前馈中同时完成,并在多个数据集上实现了SOTA性能,尤其适用于无位姿、多视图稀疏输入条件下的复杂场景。
未来的研究有几个值得进一步探索的方向:
-
将基于多任务统一前馈3D GS框架,拓展到3D基础模型自监督、甚至表征学习自监督,支持下游任务更好的学习语义、语义表征;
-
更长序列的拓展:进一步优化前向推理架构,以支持大范围、实时更新的重建感知;
-
实例运动场景重建:加入Instance分割,希望能够处理含运动物体或场景变化的视频序列;
希望通过这些拓展,实现从视觉输入到统一3D理解的可能性,更加希望为具身智能在物理世界运作提供了新的空间表征学习范式,来开启具身感知、理解与交互的新篇章。










评论区
登录后即可参与讨论
立即登录