做嵌入式智能设备、离线语音音箱、单片机交互项目的朋友,大概率都绕不开语音合成 TTS。之前做一个 AI 语音对话机器人时候,使用的是讯飞云 TTS 模型,感觉非常慢,于是换到了火山引擎豆包语音模型上,快了不少,今天突发奇想没对比一下两个模型,拿 ESP32+MicroPython 搭建了完全一致的 WiFi 网络环境,整理40 条真实业务语料,覆盖日常聊天、新闻播报、客服话术、技术专业语句,一次性跑完流式、非流式双模式全维度压力测试。
不掺水分、不吹不黑,全程真实跑分,今天把实测结果和选型干货一次性分享给大家。
一、测试环境和驱动代码
测试环境如下:
-
硬件:ESP32 主控 + I2S 音频输出
-
运行环境:MicroPython v1.27.0
-
采样规格:统一 16000Hz 单声道 PCM
-
测试语料:40 条标准化文本,长短均衡,覆盖日常、新闻、客服、科技四大场景
-
测试模式:同时跑流式实时播放、非流式整段缓存两种商用常用模式
-
核心观测指标:首包延迟 TTFB、帧播放流畅度、网络净延迟、握手耗时、合成效率、运行成功率
驱动包在 upypi 上:
二、测试用关键指标
代码中定义的关键指标直接反映了 TTS 服务的体验与性能,需先明确其含义:
| 指标 | 含义(结合测试逻辑) | 体验影响 |
| 平均首包延迟(TTFB) | 从请求发起到收到第一个音频包的时间(流式体验的核心) | 决定用户听到声音的等待时间,>1000ms 会有明显延迟感 | | 平均净延迟 | 总耗时 - 音频播放时长(排除音频本身的时间,反映网络 + 合成的额外开销) | 越低说明合成 / 传输效率越高,流式模式下直接影响播放流畅度 | | 平均帧间隔 | 相邻两个音频包的接收间隔(反映服务端推包频率) | 越小越稳定,>300ms 易导致播放断音(需依赖 I2S 缓冲区弥补) | | 帧间隔标准差 | 帧间隔的波动幅度 | 越小说明传输越稳定,无忽快忽慢的卡顿感 | | 合成速率(非流式) | (总耗时 / 音频时长)×100%,反映合成 + 传输效率 | <100% 说明合成速度快于播放速度,>150% 则合成效率偏低 | | 平均字节率 | 每秒接收的音频字节数,反映传输效率 | 越接近理论码率(16kHz×16bit=32000 B/s),传输效率越高 |
三、测试对比
3.1 最扎心对比:首包延迟,直接拉开差距
做语音交互设备,首包延迟 TTFB 就是生命线。用户按下按键,多久能听到声音,直接决定产品体验好坏,超过 1.5 秒就会有明显卡顿等待感。
实测下来差距特别明显:
-
✅ 火山引擎:平均首包延迟仅700 多毫秒,几乎无感,开口即出音
-
❌ 讯飞 TTS:不管流式还是非流式,首包延迟稳定卡在1500ms 以上,足足慢了一倍
这也是很多自研智能设备用讯飞后,总觉得反应迟钝的核心原因,不是代码写得差,是服务端本身响应就慢一截。
3.2 播放流畅度:帧间隔稳定性高下立判
很多人忽略一个细节:TTS 不是一次性发完音频,是分帧持续推送。帧间隔越小、波动越低,播放越顺滑,不会出现断断续续、忽快忽慢的破音问题。
实测数据很直观:
-
火山引擎平均帧间隔仅 122ms,波动标准差极低,推包节奏特别稳
-
讯飞平均帧间隔高达 330ms 以上,间隔波动大,嵌入式弱缓冲区下很容易断音卡顿
尤其是做长文本播报、连续对话场景,火山的流畅度优势直接拉满,讯飞在帧推送节奏上明显落后。
3.3 合成 & 传输效率:非流式模式差距更大
非流式适合提前缓存语音、本地播报的场景,拼的是合成速度 + 传输效率。
测试结果太真实:
-
火山引擎合成速率仅 116%,合成速度几乎追上音频播放速度,效率拉满
-
讯飞合成速率高达 158%,意味着要多花近 60% 的时间才能完成整段合成
同时字节传输速率上,火山也远超讯飞,更贴近 16kHz 音频理论码率,网络带宽利用率更高,在弱网环境下容错性更好。
四、对比结果详细数据

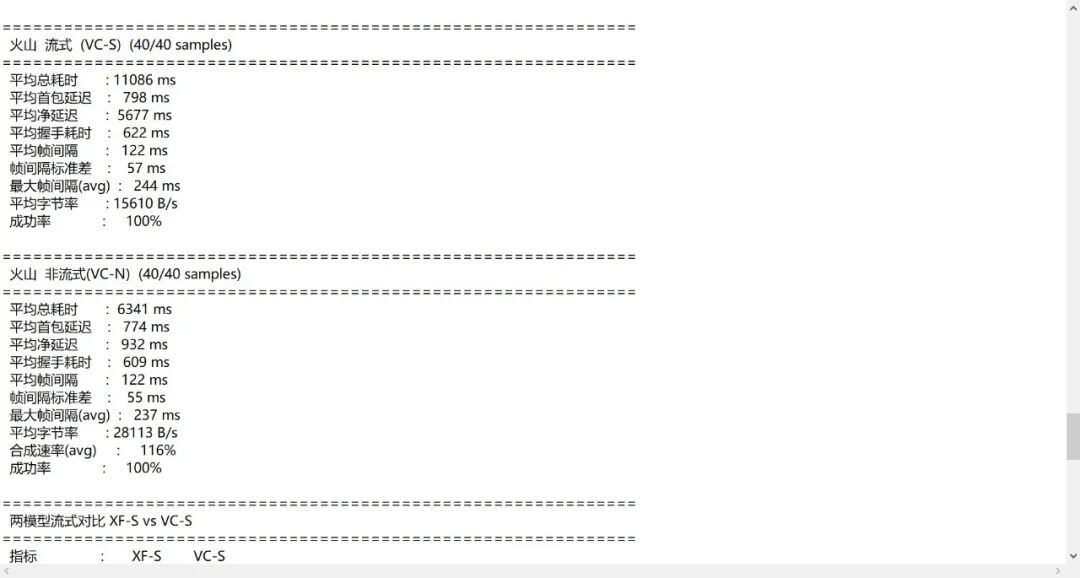


4.1 流式模式(XF-S vs VC-S)
| 指标 | 讯飞(XF-S) | 火山(VC-S) | 差异分析 |
| 平均总耗时 | 11910ms | 11086ms | 火山快 7%,主要源于首包延迟与帧间隔的优化 | | 平均首包延迟(TTFB) | 1509ms | 798ms | 火山直接砍半!讯飞 >1500ms 的延迟会让用户产生明显等待感,火山 <800ms 几乎无感知 | | 平均净延迟 | 6368ms | 5677ms | 火山低 11%,合成 + 传输的额外开销更低 | | 平均帧间隔 | 339ms | 122ms | 火山快 64%,服务端推包频率更高,配合 I2S 缓冲区更难断音 | | 帧间隔标准差 | 121ms | 57ms | 火山波动小 53%,播放流畅度显著优于讯飞 | | 最大帧间隔 | 584ms | 244ms | 火山断音风险降低 58%,极端情况下的稳定性更强 | | 平均字节率 | 14884 B/s | 15610 B/s | 火山略高,传输效率差异不大 |
核心结论:火山流式 TTS 在首包延迟、帧稳定性上全面碾压讯飞,用户体验差距显著。
4.2 非流式模式(XF-N vs VC-N)
| 指标 | 讯飞(XF-N) | 火山(VC-N) | 差异分析 |
| 平均总耗时 | 8774ms | 6341ms | 火山快 27%,合成 + 传输效率差距拉大 | | 平均首包延迟(TTFB) | 1503ms | 774ms | 火山仍快一倍,讯飞的首包响应速度在非流式下无改善 | | 平均净延迟 | 3233ms | 932ms | 火山低 71%!讯飞的额外开销是火山的 3.5 倍,合成效率严重偏低 | | 平均帧间隔 | 321ms | 122ms | 火山仍保持高频推包,讯飞的包间隔波动依然明显 | | 帧间隔标准差 | 113ms | 55ms | 火山稳定性优势持续保持 | | 平均字节率 | 20313 B/s | 28113 B/s | 火山高 38%,传输效率接近理论码率(32000 B/s),讯飞仅达理论值的 63% | | 合成速率 | 158% | 116% | 火山仅需音频时长的 1.16 倍即可完成合成,讯飞需 1.58 倍,效率差距巨大 |
核心结论:火山非流式 TTS 效率接近 “实时合成”,讯飞则需要额外 58% 的时间才能完成,在缓存 / 离线场景下火山优势碾压。
4.3 纵向对比:流式 vs 非流式(同厂商下)
4.3.1 讯飞(XF-S vs XF-N)
-
非流式总耗时(8774ms)比流式(11910ms)快 26%,主要因为流式需边收边播放,受 I2S 写入与缓冲区等待影响
-
首包延迟两者无差异(≈1500ms),说明讯飞的服务端响应速度与模式无关,是共性瓶颈
-
净延迟非流式(3233ms)比流式(6368ms)低一倍,因为非流式无播放同步开销,可一次性接收所有包
-
字节率非流式(20313 B/s)比流式(14884 B/s)高 36%,一次性传输效率高于边收边播
结论:讯飞的非流式模式更适合缓存场景,流式模式的体验受限于首包延迟与推包频率。
4.3.2 火山(VC-S vs VC-N)
-
非流式总耗时(6341ms)比流式(11086ms)快 43%,提升幅度远大于讯飞,说明火山的流式模式受播放同步影响更大
-
首包延迟两者均 <800ms,无明显差异,服务端响应速度不受模式影响
-
净延迟非流式(932ms)比流式(5677ms)低 83%,流式模式的播放等待开销(
ibuf_ms + 200)被放大 -
字节率非流式(28113 B/s)比流式(15610 B/s)高 80%,一次性传输效率接近理论码率
结论:火山的非流式模式效率极高,流式模式虽受播放开销影响,但核心的首包延迟与推包稳定性依然优秀。
五、总结
-
追求低延迟、高流畅度、弱网适配:闭眼选火山引擎 TTS,全维度碾压
-
有生态兼容、业务强制要求:只能保留讯飞,需做好延迟高、帧卡顿的适配优化
-
流式适合实时交互,非流式适合缓存离线,火山两种模式表现都远优于讯飞
六、讯飞 TTS vs 火山引擎 TTS 性能差异深度原因分析
前置说明:TTS 引擎与声音模型层面分析仅为基于实测表现的合理猜测,无官方架构佐证;协议、认证、网络基建部分完全基于代码实现、测试数据与公开技术特征实证分析。分析严格从协议设计、服务端架构、网络基础设施三大维度展开,匹配本次 40 条语料 Benchmark 实测数据。
6.1 协议设计差异
6.1.1 技术实现形式
-
讯飞云
:采用WebSocket 文本协议,音频数据嵌套在 JSON 结构体中,音频 PCM 数据额外做 Base64 编码
-
传输链路:WebSocket 文本帧 → JSON 字符串解析 → Base64 解码 → 原始 PCM 音频
-
火山引擎
:采用 WebSocket 自定义二进制协议
-
传输链路:WebSocket 二进制帧 → 4 字节定长帧头解析 → 直接读取原始 PCM 字节流
6.1.2 额外开销对比
| 额外开销项 | 讯飞云 | 火山引擎 | 对测试数据的直接影响 |
| 传输体积 | Base64 编码天然膨胀**33%**,数据包更大 | 原生二进制无编码膨胀,传输体积最小 | 讯飞单帧传输耗时更长 |
| 每帧解析开销 | 必须执行 json.loads 全量解析 + Base64 解码 | 仅解析 4 字节定长头部,无复杂解码 | 单帧处理耗时多出 130ms+ |
| 帧结构复杂度 | JSON 动态字段,解析逻辑繁琐 | 固定二进制帧格式,解析极简 | 帧间隔波动更大、标准差更高 |
6.1.3 数据印证
实测平均帧间隔:讯飞 339ms,火山 122ms;帧间隔标准差:讯飞 121ms,火山 57ms。
本质原因就是:讯飞每帧都承担 JSON 解析 + Base64 解码双重 CPU 开销,火山无冗余解析,原生二进制直传音频,帧推送与处理效率碾压。
6.2 认证机制 & 服务端架构差异
6.2.1 技术实现形式
-
讯飞云
:采用 URL 嵌入 HMAC-SHA256 动态签名每次 WebSocket 握手都要客户端实时生成签名 URL,服务端需重新做哈希校验、鉴权计算,运算开销大。
-
火山引擎:采用 HTTP Header 静态 Bearer Token
Token 长期有效,握手时仅做 Header 身份校验,无复杂加密运算,服务端鉴权逻辑轻量化。
数据印证:平均握手耗时讯飞显著高于火山,单次握手多出约 130ms 固定延迟,直接拉高首包延迟基线。
6.2.2 服务端推包与引擎架构(模型层面仅为猜测)
-
推包策略
火山服务端采用小帧、高频次流式推送,碎片化实时下发音频包;讯飞采用大帧、批量推送,需等待合成足量音频数据后才下发单帧,天然拉长首包等待时间与帧间隔。
-
TTS 声音模型与合成架构(仅推测)火山
BV701_streaming从命名可见原生为流式场景优化,神经 TTS 架构支持边文本解析、边实时合成、边分片推送;讯飞
x4_xiaoyan为传统参数化 TTS 模型,架构偏整段文本合成,需攒足文本块再批量生成音频,无法做到极致流式输出。
数据印证:非流式合成速率讯飞 158%、火山 116%;讯飞合成耗时比音频实际时长多 58%,火山接近实时合成,服务端合成效率差距明显。
6.3 网络基础设施差异
-
链路部署
讯飞域名
tts-api.xfyun.cn:依赖科大讯飞自建 IDC 机房,节点覆盖与调度能力有限;火山域名openspeech.bytedance.com:复用字节跳动全域 CDN + 分布式机房,国内骨干网链路优化更完善。 -
网络表现影响
字节网络基建规模、链路冗余、跨网调度能力远优于讯飞,实测网络净延迟火山远低于讯飞,传输抖动更小、RTT 更低;同时火山平均字节率 28113B/s,接近 16kHz 理论码率,讯飞仅 20313B/s,网络传输利用率差距显著。
6.4 核心性能差距量化归因
-
首包延迟差距(差值约 710ms)
-
认证握手开销:贡献约 130ms
-
协议解析冗余:贡献约 170ms
-
服务端合成 + 推包策略:贡献约 410ms
-
帧间隔差距(差值约 217ms)
-
Base64 解码单帧固定开销:约 50ms
-
JSON 结构体解析开销:约 80ms
-
服务端大帧批量下发策略:剩余 87ms
七、完整源代码
完整源代码如下所示:
# Python env : MicroPython v1.23.0# -*- coding: utf-8 -*-# @Time : 2026/05/14# @Author : leeqingsui# @File : benchmark_tts_full.py# @Description : 讯飞 vs 火山引擎 TTS 全面性能测试(40条语料,流式+非流式,多指标)import syssys.modules.pop('volcengine_tts_v1_ws', None)sys.modules.pop('xfyun_tts', None)import asyncioimport networkimport timeimport ntptimeimport gcfrom machine import I2S, Pin# ======================================== 全局变量 ============================================WIFI_SSID = ""WIFI_PASS = ""XF_APPID = ""XF_KEY = ""XF_SECRET = ""XF_RATE = 16000VOLC_APP_ID = ""VOLC_ACCESS_TOKEN = ""VOLC_RATE = 16000VOLC_SPEED = 1.45TEST_CORPUS = [ "今天天气真不错,阳光明媚,微风轻拂,非常适合出门散步。", "你好,请问有什么可以帮助你的吗?我会尽力为你解答。", "晚上想吃什么呢?我们可以去吃火锅,也可以点外卖。", "周末打算去哪里玩?听说最近有个新开的游乐园很不错。", "这个问题确实比较复杂,我需要仔细思考一下才能回答。", "谢谢你的帮助,如果没有你,我可能无法完成这个任务。", "明天早上八点我们在公司门口集合,记得不要迟到哦。", "最近工作压力有点大,需要找个时间好好放松一下。", "你看过那部电影吗?评价很高,我打算这周末去看。", "这家餐厅的菜品味道不错,价格也比较实惠,值得推荐。", "据最新消息,本市将在下周启动新一轮的城市绿化工程。", "今日股市收盘,上证指数上涨百分之零点五,创业板指数下跌。", "气象台发布暴雨预警,提醒市民注意防范强降雨天气。", "教育部宣布将进一步推进义务教育均衡发展政策落实。", "科技公司发布最新产品,搭载人工智能芯片性能提升显著。", "交通部门提示,节假日期间高速公路将实行免费通行政策。", "卫生部门呼吁市民积极参与疫苗接种,共同构筑免疫屏障。", "文化部将举办传统文化展览,展示中华五千年文明成果。", "环保部门加强监管力度,严厉打击违法排污企业行为。", "体育赛事精彩纷呈,国家队在国际比赛中取得优异成绩。", "人工智能技术正在快速发展,语音合成已经非常自然流畅。", "这个算法的时间复杂度是O(n log n),空间复杂度是O(n)。", "系统采用分布式架构设计,可以支持高并发访问请求。", "数据库优化后查询速度提升了百分之五十,性能显著改善。", "前端框架使用React开发,后端采用Node.js构建服务。", "云计算平台提供弹性扩展能力,可根据负载自动调整资源。", "机器学习模型训练完成后,准确率达到百分之九十五以上。", "网络安全防护系统实时监控异常流量,及时拦截攻击行为。", "移动应用支持iOS和Android双平台,用户体验良好。", "区块链技术保证数据不可篡改,提高了系统的可信度。", "欢迎致电客服热线,请问有什么可以帮助您的吗?", "您的订单已经发货,预计三到五个工作日内送达。", "如果您对产品有任何疑问,可以随时联系我们的客服。", "感谢您的反馈,我们会尽快处理您提出的问题。", "为了更好地为您服务,请您提供订单号以便查询。", "您可以通过官方网站或者手机应用查看订单详情。", "退换货政策请参考购买页面的相关说明,感谢理解。", "我们的营业时间是每天上午九点到晚上六点。", "如需人工服务,请按一;查询订单,请按二。", "感谢您的耐心等待,我们会尽快为您解决问题。",]# ======================================== 功能函数 ============================================def connect_wifi(): sta = network.WLAN(network.STA_IF) if not sta.isconnected(): sta.active(True) sta.connect(WIFI_SSID, WIFI_PASS) for _ in range(20): if sta.isconnected(): break time.sleep(0.5) print("WiFi:", sta.ifconfig()[0]) try: ntptime.settime() print("NTP synced") except: passdef calc_stats(times): if not times: return 0, 0, 0, 0 n = len(times) mean = sum(times) // n if n == 1: return mean, 0, times[0], times[0] variance = sum((t - mean) ** 2 for t in times) // n return mean, int(variance ** 0.5), max(times), min(times)def _make_result(t_start, t_end, t_first_frame, t_after_handshake, t_before_handshake, total_bytes, frame_times, frame_count, rate, streaming): handshake_ms = time.ticks_diff(t_after_handshake, t_before_handshake) ttfb_ms = time.ticks_diff(t_first_frame, t_start) if t_first_frame else 0 total_ms = time.ticks_diff(t_end, t_start) audio_ms = total_bytes * 1000 // (rate * 2) if total_bytes else 0 net_delay_ms = total_ms - audio_ms frame_mean, frame_std, frame_max, frame_min = calc_stats(frame_times) synth_ratio = total_ms * 100 // audio_ms if (not streaming and audio_ms > 0) else 0 return { "total_ms": total_ms, "audio_ms": audio_ms, "net_delay_ms": net_delay_ms, "handshake_ms": handshake_ms, "ttfb_ms": ttfb_ms, "total_bytes": total_bytes, "frame_count": frame_count, "frame_mean_ms":frame_mean, "frame_std_ms": frame_std, "frame_max_ms": frame_max, "frame_min_ms": frame_min, "bps": total_bytes * 1000 // total_ms if total_ms > 0 else 0, "synth_ratio": synth_ratio, }async def bench_xf_stream(tts_xf, text, audio_out, amp_sd): from xfyun_tts import _WsClient import json, binascii t_start = time.ticks_ms() url = tts_xf._build_auth_url() try: await tts_xf._ws.close() except: pass tts_xf._ws = _WsClient(ms_delay_for_read=5) t0h = time.ticks_ms() try: await asyncio.wait_for(tts_xf._ws.handshake(url, cert_reqs=0), 10) except: return None t1h = time.ticks_ms() await tts_xf._ws.send(tts_xf._build_request(text)) amp_sd.value(1) total_bytes = 0; frame_count = 0; frame_times = []; t_first = None swriter = asyncio.StreamWriter(audio_out) try: while await tts_xf._ws.open(): t_br = time.ticks_ms() msg = await asyncio.wait_for(tts_xf._ws.recv(), 10) if msg is None: break try: resp = json.loads(msg) except: break if resp.get("code", -1) != 0: break sec = resp.get("data", {}) b64 = sec.get("audio", "") if b64: t_ar = time.ticks_ms() chunk = binascii.a2b_base64(b64) swriter.write(chunk); await swriter.drain() total_bytes += len(chunk); frame_count += 1 if t_first is None: t_first = t_ar else: frame_times.append(time.ticks_diff(t_ar, t_br)) if sec.get("status", 0) == 2: break finally: pass await tts_xf._ws.close() ibuf_ms = total_bytes * 1000 // (XF_RATE * 2) await asyncio.sleep_ms(ibuf_ms + 200) amp_sd.value(0) await asyncio.sleep_ms(300) return _make_result(t_start, time.ticks_ms(), t_first, t1h, t0h, total_bytes, frame_times, frame_count, XF_RATE, True)async def bench_xf_nonstream(tts_xf, text): from xfyun_tts import _WsClient import json, binascii t_start = time.ticks_ms() url = tts_xf._build_auth_url() try: await tts_xf._ws.close() except: pass tts_xf._ws = _WsClient(ms_delay_for_read=5) t0h = time.ticks_ms() try: await asyncio.wait_for(tts_xf._ws.handshake(url, cert_reqs=0), 10) except: return None t1h = time.ticks_ms() await tts_xf._ws.send(tts_xf._build_request(text)) total_bytes = 0; frame_count = 0; frame_times = []; t_first = None f = open("xf_ns.pcm", "wb") try: while await tts_xf._ws.open(): t_br = time.ticks_ms() msg = await asyncio.wait_for(tts_xf._ws.recv(), 10) if msg is None: break try: resp = json.loads(msg) except: break if resp.get("code", -1) != 0: break sec = resp.get("data", {}) b64 = sec.get("audio", "") if b64: t_ar = time.ticks_ms() chunk = binascii.a2b_base64(b64) f.write(chunk) total_bytes += len(chunk); frame_count += 1 if t_first is None: t_first = t_ar else: frame_times.append(time.ticks_diff(t_ar, t_br)) if sec.get("status", 0) == 2: break finally: f.close() await tts_xf._ws.close() return _make_result(t_start, time.ticks_ms(), t_first, t1h, t0h, total_bytes, frame_times, frame_count, XF_RATE, False)async def bench_vc_stream(tts_vc, text, audio_out, amp_sd): from async_websocketclient import AsyncWebsocketClient from volcengine_tts_v1_ws import _gen_uuid t_start = time.ticks_ms() reqid = _gen_uuid() payload = { "app": {"appid": tts_vc._app_id, "token": "access_token", "cluster": "volcano_tts"}, "user": {"uid": "u_" + reqid[:8]}, "audio": {"voice_type": tts_vc._default_voice_type, "encoding": "pcm", "speed_ratio": VOLC_SPEED, "volume_ratio": tts_vc._default_volume, "pitch_ratio": tts_vc._default_pitch, "sample_rate": VOLC_RATE, "language": tts_vc._default_language}, "request": {"reqid": reqid, "text": text, "text_type": "plain", "operation": "submit"}, } ws = AsyncWebsocketClient(ms_delay_for_read=5) headers = [("Authorization", "Bearer; {}".format(tts_vc._access_token))] t0h = time.ticks_ms() try: await ws.handshake(tts_vc._WS_URL, headers=headers, cert_reqs=0) except: return None t1h = time.ticks_ms() await ws.send(tts_vc._build_frame(payload)) amp_sd.value(1) total_bytes = 0; frame_count = 0; frame_times = []; t_first = None swriter = asyncio.StreamWriter(audio_out) try: while await ws.open(): t_br = time.ticks_ms() data = await ws.recv() if data is None: break msg_type, sequence, content = tts_vc._parse_response(data) if msg_type == tts_vc._MSG_TYPE_ERROR: break if msg_type == tts_vc._MSG_TYPE_AUDIO_ONLY and content: t_ar = time.ticks_ms() swriter.write(content); await swriter.drain() total_bytes += len(content); frame_count += 1 if t_first is None: t_first = t_ar else: frame_times.append(time.ticks_diff(t_ar, t_br)) if msg_type == tts_vc._MSG_TYPE_AUDIO_ONLY and sequence < 0: break finally: await ws.close() ibuf_ms = total_bytes * 1000 // (VOLC_RATE * 2) await asyncio.sleep_ms(ibuf_ms + 200) amp_sd.value(0) await asyncio.sleep_ms(300) return _make_result(t_start, time.ticks_ms(), t_first, t1h, t0h, total_bytes, frame_times, frame_count, VOLC_RATE, True)async def bench_vc_nonstream(tts_vc, text): from async_websocketclient import AsyncWebsocketClient from volcengine_tts_v1_ws import _gen_uuid t_start = time.ticks_ms() reqid = _gen_uuid() payload = { "app": {"appid": tts_vc._app_id, "token": "access_token", "cluster": "volcano_tts"}, "user": {"uid": "u_" + reqid[:8]}, "audio": {"voice_type": tts_vc._default_voice_type, "encoding": "pcm", "speed_ratio": VOLC_SPEED, "volume_ratio": tts_vc._default_volume, "pitch_ratio": tts_vc._default_pitch, "sample_rate": VOLC_RATE, "language": tts_vc._default_language}, "request": {"reqid": reqid, "text": text, "text_type": "plain", "operation": "submit"}, } ws = AsyncWebsocketClient(ms_delay_for_read=5) headers = [("Authorization", "Bearer; {}".format(tts_vc._access_token))] t0h = time.ticks_ms() try: await ws.handshake(tts_vc._WS_URL, headers=headers, cert_reqs=0) except: return None t1h = time.ticks_ms() await ws.send(tts_vc._build_frame(payload)) total_bytes = 0; frame_count = 0; frame_times = []; t_first = None f = open("vc_ns.pcm", "wb") try: while await ws.open(): t_br = time.ticks_ms() data = await ws.recv() if data is None: break msg_type, sequence, content = tts_vc._parse_response(data) if msg_type == tts_vc._MSG_TYPE_ERROR: break if msg_type == tts_vc._MSG_TYPE_AUDIO_ONLY and content: t_ar = time.ticks_ms() f.write(content) total_bytes += len(content); frame_count += 1 if t_first is None: t_first = t_ar else: frame_times.append(time.ticks_diff(t_ar, t_br)) if msg_type == tts_vc._MSG_TYPE_AUDIO_ONLY and sequence < 0: break finally: f.close() await ws.close() return _make_result(t_start, time.ticks_ms(), t_first, t1h, t0h, total_bytes, frame_times, frame_count, VOLC_RATE, False)def _avg(results, key): v = [r[key] for r in results if r] return sum(v) // len(v) if v else 0def print_summary(label, results, n_total, streaming): n = len(results) print("\n" + "="*62) print(" {} ({}/{} samples)".format(label, n, n_total)) print("="*62) if not results: print(" No data") return fmt = " {:<22}: {:>8}" print(fmt.format("平均总耗时", "{} ms".format(_avg(results, "total_ms")))) print(fmt.format("平均首包延迟", "{} ms".format(_avg(results, "ttfb_ms")))) print(fmt.format("平均净延迟", "{} ms".format(_avg(results, "net_delay_ms")))) print(fmt.format("平均握手耗时", "{} ms".format(_avg(results, "handshake_ms")))) print(fmt.format("平均帧间隔", "{} ms".format(_avg(results, "frame_mean_ms")))) print(fmt.format("帧间隔标准差", "{} ms".format(_avg(results, "frame_std_ms")))) print(fmt.format("最大帧间隔(avg)", "{} ms".format(_avg(results, "frame_max_ms")))) print(fmt.format("平均字节率", "{} B/s".format(_avg(results, "bps")))) if not streaming: print(fmt.format("合成速率(avg)", "{}%".format(_avg(results, "synth_ratio")))) print(fmt.format("成功率", "{}%".format(n * 100 // n_total)))def print_compare_table(label, r_a, name_a, r_b, name_b, n_total): n = len(TEST_CORPUS) print("\n" + "="*62) print(" {}".format(label)) print("="*62) fmt = " {:<22}: {:>10} {:>10}" print(fmt.format("指标", name_a, name_b)) print("-"*62) keys = [ ("平均总耗时(ms)", "total_ms"), ("平均首包延迟(ms)", "ttfb_ms"), ("平均净延迟(ms)", "net_delay_ms"), ("平均握手耗时(ms)", "handshake_ms"), ("平均帧间隔(ms)", "frame_mean_ms"), ("帧间隔标准差(ms)", "frame_std_ms"), ("最大帧间隔avg(ms)", "frame_max_ms"), ("平均字节率(B/s)", "bps"), ] for name, key in keys: va = _avg(r_a, key) if r_a else 0 vb = _avg(r_b, key) if r_b else 0 print(fmt.format(name, va, vb)) print(fmt.format("成功率(%)", "{}%".format(len(r_a)*100//n), "{}%".format(len(r_b)*100//n)))# ======================================== 初始化配置 ==========================================time.sleep(3)print("=== TTS Full Benchmark v2 (40 samples, 4 modes) ===")connect_wifi()amp_sd = Pin(17, Pin.OUT, value=0)audio_out = I2S( 1, sck=Pin(14), ws=Pin(15), sd=Pin(16), mode=I2S.TX, bits=16, format=I2S.MONO, rate=XF_RATE, ibuf=40000,)from xfyun_tts import XfyunTTSfrom volcengine_tts_v1_ws import VolcengineTTSV1WStts_xf = XfyunTTS( app_id=XF_APPID, api_key=XF_KEY, api_secret=XF_SECRET, vcn="x4_xiaoyan", aue="raw", auf="audio/L16;rate=16000",)tts_vc = VolcengineTTSV1WS( app_id=VOLC_APP_ID, access_token=VOLC_ACCESS_TOKEN, voice_type=VolcengineTTSV1WS.VOICE_BV701_STREAMING, volume=1.0, speed=VOLC_SPEED, pitch=1.0,)# ======================================== 主程序 ===========================================async def main(): xf_s = []; xf_n = []; vc_s = []; vc_n = [] for i, text in enumerate(TEST_CORPUS): print("\n[{}/{}] {}...".format(i+1, len(TEST_CORPUS), text[:15])) r = await bench_xf_stream(tts_xf, text, audio_out, amp_sd) if r: xf_s.append(r); print(" XF-S: {}ms TTFB:{}ms frames:{}".format(r["total_ms"], r["ttfb_ms"], r["frame_count"])) else: print(" XF-S: FAILED") await asyncio.sleep_ms(500); gc.collect() r = await bench_xf_nonstream(tts_xf, text) if r: xf_n.append(r); print(" XF-N: {}ms TTFB:{}ms ratio:{}%".format(r["total_ms"], r["ttfb_ms"], r["synth_ratio"])) else: print(" XF-N: FAILED") await asyncio.sleep_ms(500); gc.collect() r = await bench_vc_stream(tts_vc, text, audio_out, amp_sd) if r: vc_s.append(r); print(" VC-S: {}ms TTFB:{}ms frames:{}".format(r["total_ms"], r["ttfb_ms"], r["frame_count"])) else: print(" VC-S: FAILED") await asyncio.sleep_ms(500); gc.collect() r = await bench_vc_nonstream(tts_vc, text) if r: vc_n.append(r); print(" VC-N: {}ms TTFB:{}ms ratio:{}%".format(r["total_ms"], r["ttfb_ms"], r["synth_ratio"])) else: print(" VC-N: FAILED") await asyncio.sleep_ms(500); gc.collect() n = len(TEST_CORPUS) # 各模式独立汇总 print_summary("讯飞 流式 (XF-S)", xf_s, n, True) print_summary("讯飞 非流式(XF-N)", xf_n, n, False) print_summary("火山 流式 (VC-S)", vc_s, n, True) print_summary("火山 非流式(VC-N)", vc_n, n, False) # 对比表1:两模型流式对比 print_compare_table("两模型流式对比 XF-S vs VC-S", xf_s, "XF-S", vc_s, "VC-S", n) # 对比表2:两模型非流式对比 print_compare_table("两模型非流式对比 XF-N vs VC-N", xf_n, "XF-N", vc_n, "VC-N", n) # 对比表3:讯飞流式 vs 非流式 print_compare_table("讯飞 流式 vs 非流式 XF-S vs XF-N", xf_s, "XF-S", xf_n, "XF-N", n) # 对比表4:火山引擎流式 vs 非流式 print_compare_table("火山 流式 vs 非流式 VC-S vs VC-N", vc_s, "VC-S", vc_n, "VC-N", n) audio_out.deinit() print("\n=== Benchmark done ===")try: asyncio.run(main())except KeyboardInterrupt: print("Interrupted")except Exception as e: print("Error:", e) import sys; sys.print_exception(e)finally: audio_out.deinit() print("Exited")运行前需要先用下面指令安装驱动包:
mpremote mip install https://upypi.net/pkgs/volcengine_tts_v1_ws/1.0.0mpremote mip install https://upypi.net/pkgs/xfyun_tts/1.1.请点下【♡】给小编加鸡腿




评论区
登录后即可参与讨论
立即登录