数秒克隆语音早已不是新鲜事,但能覆盖600+语种的语音克隆 TTS 模型,你见过吗!主流音色克隆 TTS 模型的多语言支持最多停留在几十种,大量低资源小语种始终难以覆盖,成为行业痛点。小米AI实验室新一代Kaldi团队全新推出 OmniVoice,以创新的极简架构打破这一局限,不仅在中英文场景达到顶尖性能,更在多语言任务中展现出超越商用系统的实力,是业内首个覆盖数百语种的语音克隆 TTS 模型,在低资源小语种上具备极强的泛化能力,你想得到的所有语种几乎都可以用 OmniVoice 来合成。
01
极简架构,超强实力,LLM 加持,彻底解决读不准问题
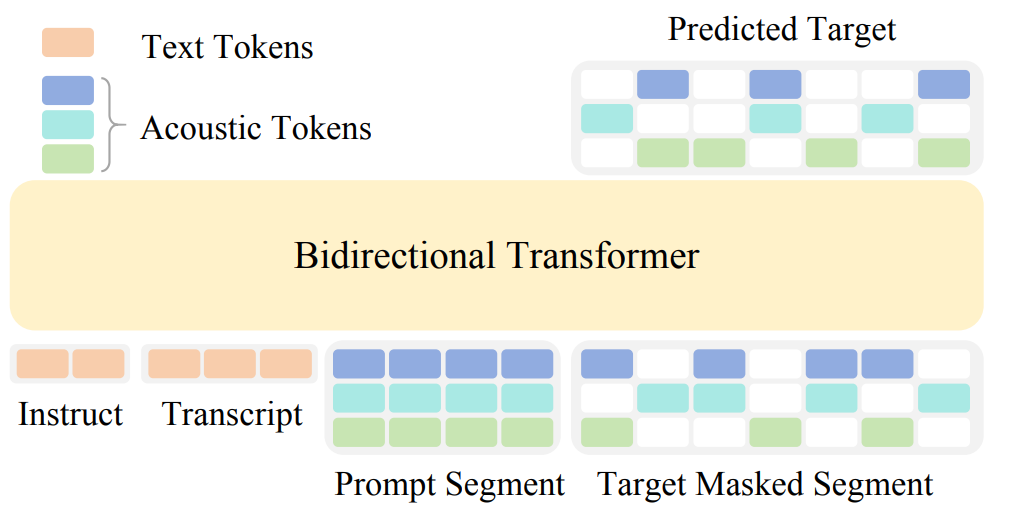
OmniVoice 模型架构
OmniVoice最亮眼的突破,莫过于它极简的模型架构。它仅用一个双向 Transformer 网络,就能直接实现文本到语音的转化,省去了多余的结构和环节:没有文本的单独建模,没有复杂的混合结构,也没有多层级的 token 预测,是目前最简单的非自回归 TTS 模型。不少人或许会产生疑问:如此简单的架构,性能能达标吗?答案是不仅达标,还远超预期。
我们对 OmniVoice 的中英文能力进行了严谨验证,OmniVoice 的语音合成质量优于目前同类主流模型,同时,训练和推理速度极具优势,一天完成10万小时训练,用 PyTorch 推理就可以达到40倍实时,轻松适配各类应用场景。
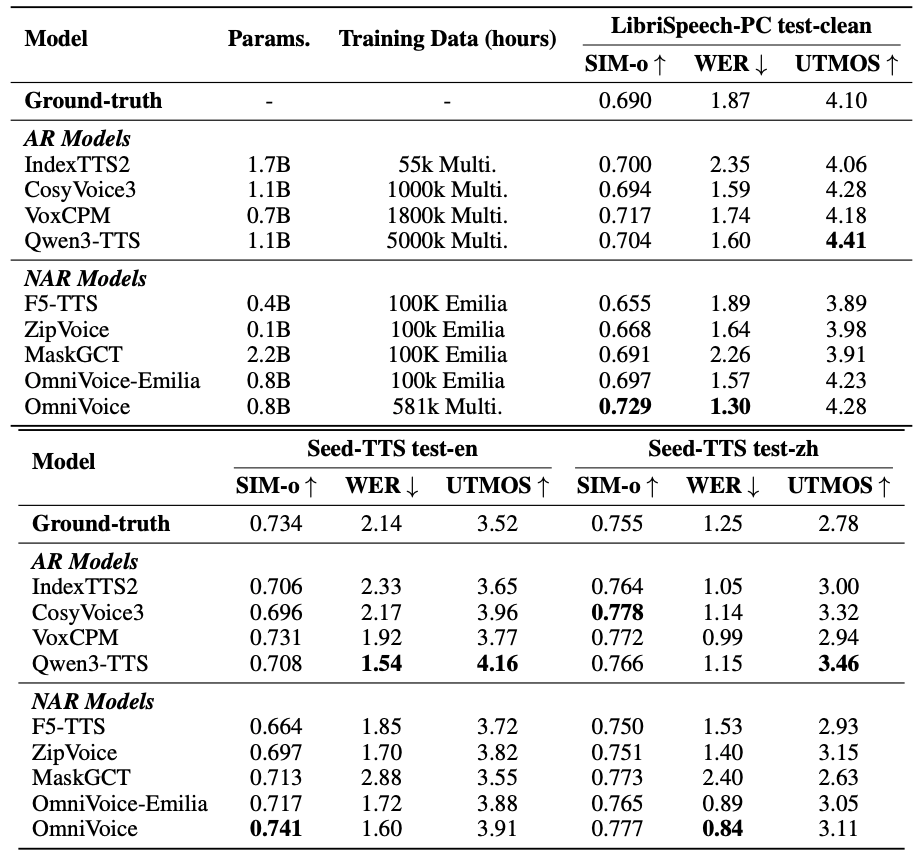
中英文测试集上的TTS性能对比
这份“极简却极强”的实力,源于两个关键设计:一是通过全码本随机掩蔽策略,显著提升模型的训练效率,进而全面提升模型能力;二是引入大语言模型作为模型的预训练参数,首次在非自回归 TTS 模型中有效利用大语言模型,让语音合成的可懂度大幅提升,彻底解决了“读不准”的问题。
02
纯开源数据打造,性能超越商用系统
要实现多语言语音合成,高质量的多语言数据集是核心。OmniVoice 依托开源社区的力量,收集了50个开源语音数据集,经过降噪、质量筛选等处理,最终构建了涵盖 646 种语种、总时长 58 万小时的多语言训练数据集。考虑到不同语种的数据量差异极大,我们采用低资源语种动态上采样训练策略,保证了低资源小语种的训练效果。
在多语言测试中,OmniVoice 表现惊艳:即便仅基于开源数据训练,在24语种的测试中,其语音相似度和可懂度均超越多款商用系统;在102种语种的测试中,它的语音可懂度逼近甚至优于真实语音,充分展现了其强大的多语言泛化能力;即便对于训练数据不足10小时的小语种,OmniVoice 也能实现高质量的语音合成,大大降低了低资源语种的语音合成门槛。
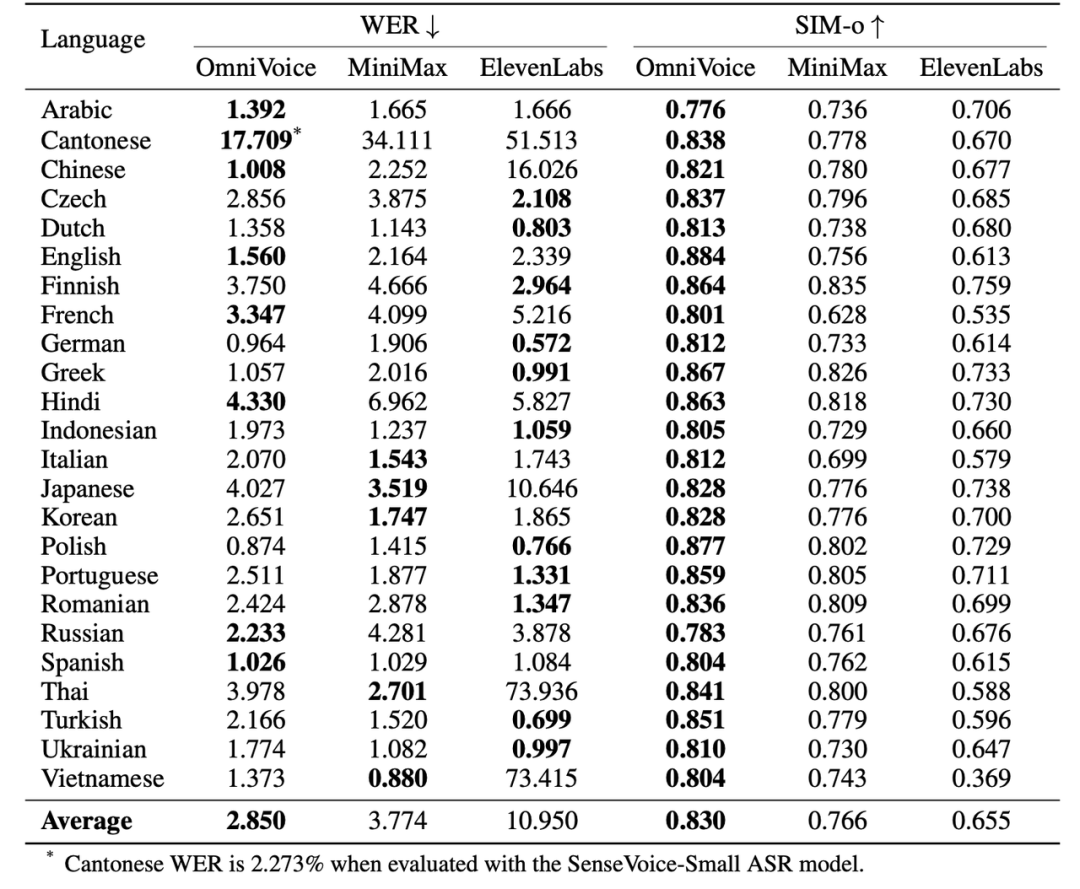
24个语种上 OmniVoice 与商用系统性能对比

102个语种上 OmniVoice 与真实语音的测试指标对比
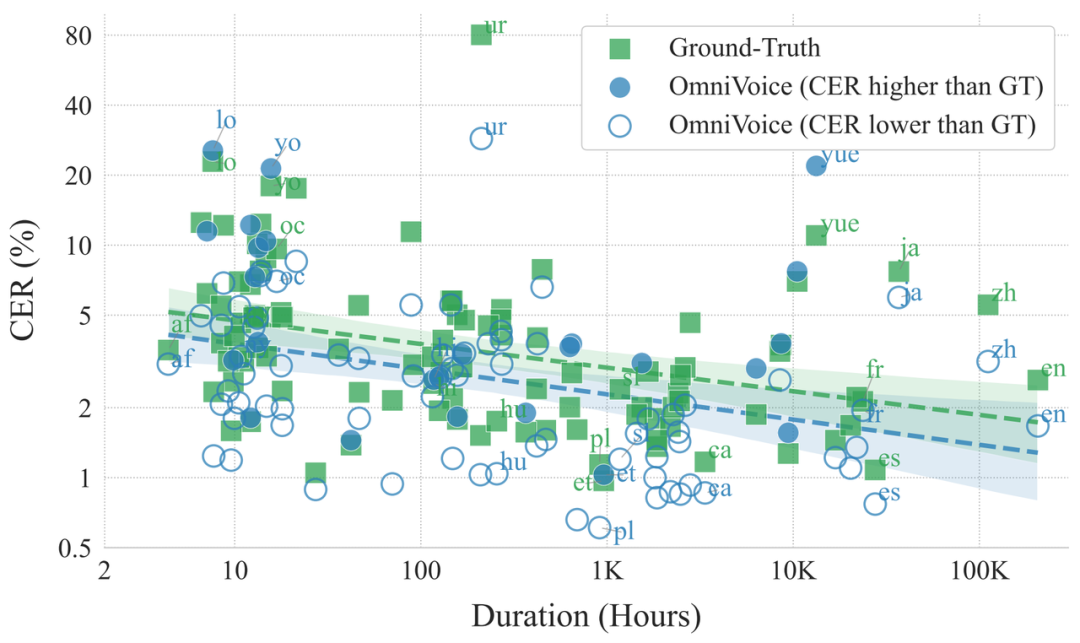
102个语种上的 OmniVoice 生成语音与真实语音的字错误率(CER)及对应训练数据时长
03
只要能说一种语言,就能说万国语言
语音克隆模型的核心功能就是模仿参考音频(prompt)的音色和情感生成以假乱真的音频,这自不消多说,OmniVoice 轻松搞定,OmniVoice 另一大特色是跨语言克隆能力,真正做到了只要能说一种语言,就能说万国语言!
下边是用中文参考音频生成的日韩两国语言的语音例子:
中文参考音频:
生成的日语语音:
生成的韩语语音:
04
多维度可控,你的音频你说了算
除了核心的多语言和语音克隆能力,OmniVoice 还新增了多个实用功能,让语音合成更灵活、更贴合实际需求:
1.自定义音色设计:无需参考音频,只需描述音色属性(如性别、年龄、音调、方言、口音等),就能生成符合预期的音色,还支持耳语等特殊风格。
比如,“为什么我的眼里常含泪水?因为我对这土地爱得深沉。这土地,这河流,这吹刮着的暴风。”这句话,就可以通过如下的指令词用不同的音色读出来:
“男,中年,极低音调”:
“女,青年,四川话”:
虽然训练过程中只有一些中英文数据进行了音色设计任务的训练,这一能力也可以一定程度上泛化到其他语种,比如对于韩语文本“그래도 관계자의 조언을 듣고 모든 표지판을 지키고, 안전 경고에 세심한 주의를 기울여야 합니다.”,也可以通过如下的指令合成不同的音色:
“Female, Young Adult, Whisper”:
2. 带噪参考音频适配:针对实际使用中参考音频音质不佳的问题,OmniVoice 能自动过滤噪声,提取清晰的音色特征,即便在嘈杂环境下录制的音频,也能克隆出高质量语音。
比如使用如下的带噪参考音频:
也可以生成干净的语音:
3. 丰富语气表达:支持插入笑声、叹气等语气符号,让合成语音更有表现力,更贴近真人交流。
使用文本“[dissatisfaction-hnn]这个结果我不太满意。[surprise-oh]原来你有备用方案?[laughter]那太好了。”可以合成:
4. 发音精准纠正:针对中英文多音字、专有名词易读错的问题,用户可通过简单设置,纠正发音错误,提升语音合成的可靠性。
比如对于含多音字的文本:“这批货物打折出售后他严重折本了,再也经不起折腾了。”,可以用如下的方式指定发音“这批货物打 ZHE2出售后他严重 SHE2本了,再也经不起 ZHE1腾了。”,从而可以生成:
05
全面开源,打开多语言 TTS 研发新范式
OmniVoice 不仅全部基于开源数据训练,其本身的训练、推理代码及模型权重也全面开源,无论是想体验600+语种的语音克隆,还是研究者、开发者进行二次创新,都能直接上手,源码面前,了无秘密!
OmniVoice 的推出,不仅打破了多语言语音克隆的语种局限,更以极简架构、顶尖性能和全开源特性,为 TTS 领域带来新的范式。其核心优势可概括为三点:
1. 架构极简高效:简单设计却实现顶尖性能,训练和推理速度远超同类模型;
2. 多语言能力顶尖:覆盖646种语种,低资源小语种也能实现高质量合成,性能超越商用系统;
3. 实用性极强:多维度可控,适配自定义音色、带噪参考音频使用、副语言控制、发音纠错等多种实际应用场景。
项目相关链接:
-
Huggingface Demo Space:https://huggingface.co/spaces/k2-fsa/OmniVoice(无需代码一键试用)
-
Huggingface Model:https://huggingface.co/k2-fsa/OmniVoice(模型权重直接调用)








评论区
登录后即可参与讨论
立即登录