NVIDIA CEO 黄仁勋在戴尔科技全球峰会上表示:“需求正迎来抛物线式增长,完全是抛物线式的”
本周一,黄仁勋与戴尔 CEO Michael Dell 共同登台,发布了 Dell AI Factory with NVIDIA 的最新更新 —— 旨在为自主智能体提供从桌面工作站到数据中心机架的全栈平台。 借助 NVIDIA Vera Rubin 平台,代理式 AI 推理的每 Token 成本降低至原来的十分之一。运行在 NVIDIA Vera 的智能体沙盒,相比于在传统 CPU 上的运行速度
关于「AI推理」的技术文章、设计资料与工程师讨论,持续更新。

本周一,黄仁勋与戴尔 CEO Michael Dell 共同登台,发布了 Dell AI Factory with NVIDIA 的最新更新 —— 旨在为自主智能体提供从桌面工作站到数据中心机架的全栈平台。 借助 NVIDIA Vera Rubin 平台,代理式 AI 推理的每 Token 成本降低至原来的十分之一。运行在 NVIDIA Vera 的智能体沙盒,相比于在传统 CPU 上的运行速度
人工智能 (AI) 已不再是孤立的技术门类,而是融入各类设备、企业工作流程与云基础设施的底层能力。在此背景下,行业面临的核心挑战,已不再局限于打造性能更强的 AI 模型,而是如何在实际业务环境中实现高效部署与规模化落地。 Moor Insights and Strategy 最新发布的《从设备到云端:AI 时代 Arm 的关键价值 (From Devices to the Cloud: Arm’s
内存市场今年面临严峻挑战。由于制造商优先为数据中心和大规模AI工作负载供应DDR5和高带宽内存(HBM),内存供应趋紧,成本大幅飙升:与2025年第三季度相比,价格已上涨了3至4倍,且市场信号表明价格峰值尚未到来。 据报道,即便是通常处于市场优先级的超大规模云厂商,也仅获得了约70%的分配容量。分析师预计,这种紧张局面将贯穿2026年全年,甚至可能延续至2027年。 这种压力并非均匀分布。价格涨幅
AI技术的普及不仅推动着以大模型训练为核心应用的大算力基础设施市场繁荣,同时也极大推动了边缘AI应用的快速普及。随着边缘AI应用场景的不断丰富,终端设备对核心处理器的要求已不再局限于基础的计算与控制功能,而是升级为“AI推理算力、低功耗、高集成、高可靠”的综合能力比拼。在此行业变革背景下,集成NPU的SoC产品异军突起,通过将CPU、NPU、GPU、ISP、存储控制器、接口模块等核心组件集成于单一
数字时代里,算力就是推动技术进步的核心引擎。ASIC芯片和GPU作为两种最核心的算力载体,各自在特定领域都有着不可替代的优势。 今天就把两者的技术差异、性能特点和适用场景说透,不管你是挖矿、做AI还是搞高性能计算,都能得到专业的参考。 1. 先给核心结论 ASIC是为单一任务优化的专用芯片,GPU是面向通用并行计算的灵活方案,两者没有绝对好坏,只看你用在什么地方。核心差异我整理了一张对比表,一目了
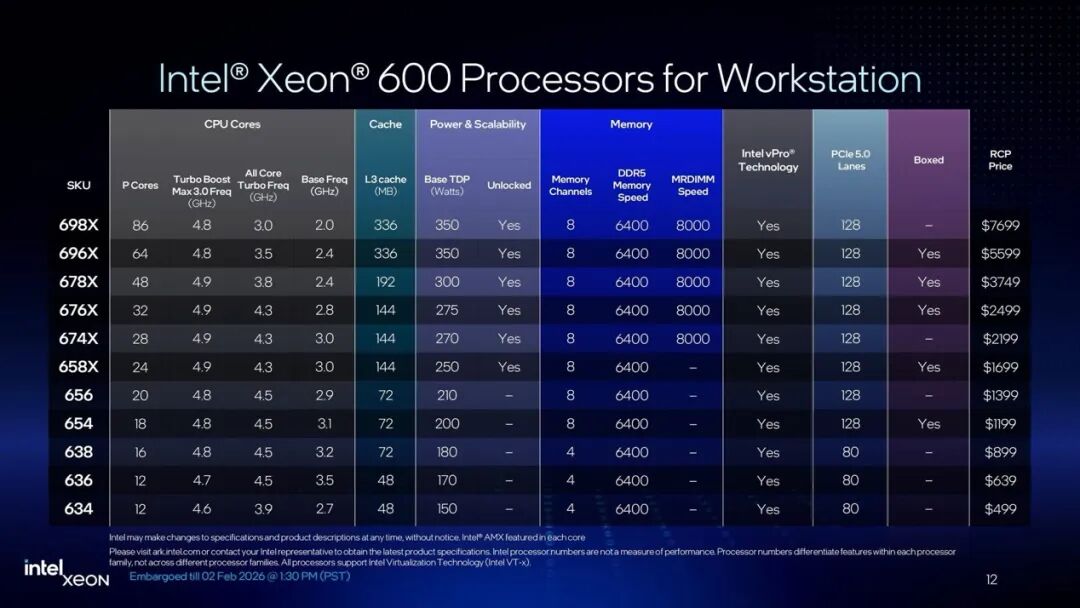
[ ](https://mp.weixin.qq.com/s?__biz=MzIxMDE0NTM0Nw==&mid=2649358184&idx=3&sn=83907863a30de303c57f3c565305c6bb&scene=21#wechat_redirect) 因为有AI的加成,强调AI能力的工作站出货量今年预计会增长65.2%(数据来源:IDC)。恰好
近日,中国移动自主研发的九天35B通用大模型即将正式发布。作为中国移动重要的生态合作伙伴及 “AI 能力联合舰队” 的核心算力成员,摩尔线程基于旗舰级AI训推一体全功能GPU MTT S5000,依托成熟的MUSA软件栈与高性能算子优化,已率先完成九天35B模型的全流程适配与推理验证。这不仅是国产GPU与央企大模型的深度协同,更意味着国产AI算力已具备支撑行业级大模型规模化落地的核心能力。 软硬协
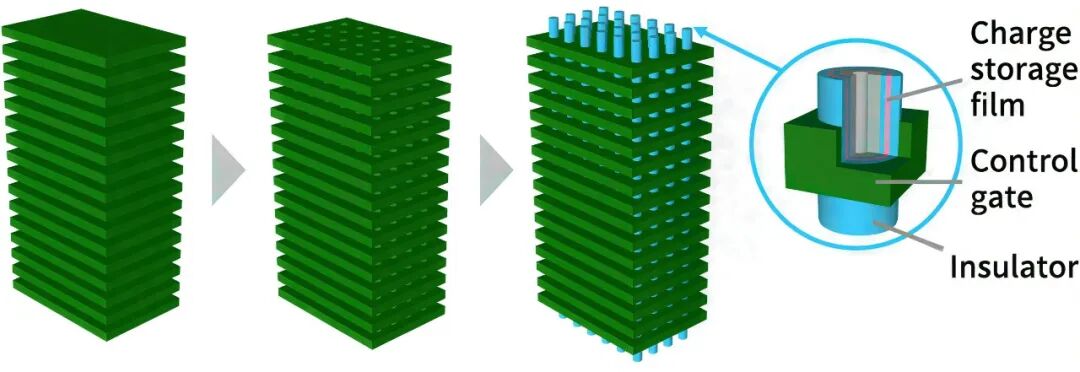
存储器行业素以强周期性著称,如今再次站在十字路口。这一切始于几年前的人工智能(AI)热潮:当时,高带宽内存(HBM)与AI加速器一同成为训练模型的首选。作为DRAM的一种特殊形式,HBM的利润率远高于NAND闪存。面对NAND价格下跌、利润缩水的困境,三星和SK海力士等大型厂商在扩大NAND产能上变得愈发谨慎。 技术层面同样挑战重重。随着NAND闪存层数突破200层大关,每一代新产品都需要先进的制