AI技术的普及不仅推动着以大模型训练为核心应用的大算力基础设施市场繁荣,同时也极大推动了边缘AI应用的快速普及。随着边缘AI应用场景的不断丰富,终端设备对核心处理器的要求已不再局限于基础的计算与控制功能,而是升级为“AI推理算力、低功耗、高集成、高可靠”的综合能力比拼。在此行业变革背景下,集成NPU的SoC产品异军突起,通过将CPU、NPU、GPU、ISP、存储控制器、接口模块等核心组件集成于单一芯片,实现了“算力、功耗、集成度”的最优平衡,完美适配边缘AI应用的核心需求。近年来,全球半导体厂商纷纷加大集成NPU的SoC研发投入,产品迭代速度加快,应用场景持续拓宽,集成NPU的SoC已逐渐取代传统MPU,成为边缘AI终端的首选处理器,一跃成为半导体与智能硬件市场的新宠儿。
边缘AI应用倒逼传统MPU升级
所谓边缘AI,本质是在终端设备本地完成AI推理任务,例如视觉识别、语音交互、异常检测、预测性维护等。这一变化直接带来了三个核心需求跃迁:
第一,低延迟与实时响应成为刚需
工业视觉检测、自动驾驶辅助、智能安防等场景,要求毫秒级甚至亚毫秒级响应,而云端往返延迟难以满足。
第二,数据隐私与安全需求显著增强
医疗设备、智能家居、车载系统等应用中,数据本地处理可避免敏感信息上传云端。
第三,能效比成为决定性指标
边缘设备往往受限于电池供电或低功耗设计,传统高算力架构难以直接迁移。
这些需求共同指向一个结论:传统以通用计算为核心的处理器架构(MPU/MCU),已经难以独立承担AI时代的边缘计算任务。
面对边缘AI应用的需求挑战,传统MPU的升级方向已明确:必须集成专用的AI处理单元(NPU),通过NPU与CPU的协同工作,实现AI推理算力与通用计算能力的平衡,同时控制功耗、提升集成度。NPU(神经网络处理器)是专门为神经网络计算设计的处理器,采用并行架构,能够高效处理AI推理任务,其核心优势在于“高算力、低功耗、高适配性”,成为边缘AI处理器的核心组成部分,也是传统处理器升级的必由之路。
NPU作为专用AI处理器,其架构设计完全围绕神经网络计算的需求展开,NPU采用大规模并行计算架构,内置大量的运算单元(如MAC单元),能够同时处理多个神经网络计算任务,大幅提升AI推理效率。与传统CPU的串行计算不同,NPU能够将AI算法中的卷积、池化等操作分解为多个并行任务,同时进行运算,从而缩短推理延迟。
NPU内置专用的神经网络加速模块,能够针对主流的AI算法(如CNN、RNN、Transformer等)进行硬件加速,支持多种模型格式(如ONNX、TensorFlow Lite等),能够快速适配不同边缘AI应用的算法需求。同时,NPU支持模型量化(如INT8、INT4量化),能够在不影响推理精度的前提下,减小模型体积,降低存储需求和数据传输带宽,适配边缘设备的存储和带宽限制。
NPU采用专用架构,仅针对神经网络计算进行优化,无需承担通用计算任务,因此功耗远低于传统CPU。同时,NPU支持动态算力调节,能够根据AI推理任务的负载,自动调节运算单元的工作状态,避免无效功耗消耗。例如,当边缘设备处于低负载状态(如无AI推理任务)时,NPU可进入休眠模式,功耗降至微瓦级;当有AI推理任务时,NPU快速唤醒,输出所需算力,实现“算力按需分配”,大幅降低设备整体功耗。
集成NPU的SoC中,NPU负责处理AI推理任务,CPU负责处理通用计算、控制、接口通信等任务,两者协同工作,实现算力的最优分配。这种协同架构,既保证了AI推理任务的高效运行,又兼顾了边缘设备的基础控制和数据处理需求,避免了单一处理器的短板。例如,在智慧安防摄像头中,NPU负责实时处理图像识别、人脸检测等AI任务,CPU负责控制摄像头的拍摄、存储、网络传输等功能,两者协同工作,实现“实时识别+快速传输”的核心需求,同时控制设备整体功耗。
对于边缘AI应用而言,内置NPU不是“可选配置”,而是“必备配置”,其核心原因在于:传统MPU即便通过提升主频、增加核心数来提升算力,也无法解决AI推理的效率和功耗问题,只有集成专用NPU,才能实现“高算力、低功耗、高集成”的三重目标,NPU不仅是提升AI推理算力的核心支撑,还是控制边缘设备功耗的关键,从而提升MPU在边缘AI应用中的竞争力。
除了内置NPU带来的AI算力优势外,SoC本身的架构特性,使其相比传统MPU、MCU以及独立NPU,更适合边缘AI应用。SoC的核心优势在于“一体化集成、协同优化、灵活适配”,能够完美匹配边缘AI应用的“实时性、低功耗、小型化、高可靠性”需求,成为边缘AI应用的最优处理器选择。相比传统分立方案(多个芯片组合),SoC的单位算力成本和单位功耗成本更低,能够帮助边缘设备厂商降低整体硬件成本,提升产品的市场竞争力。
主流大厂主推集成NPU的边缘AI SoC
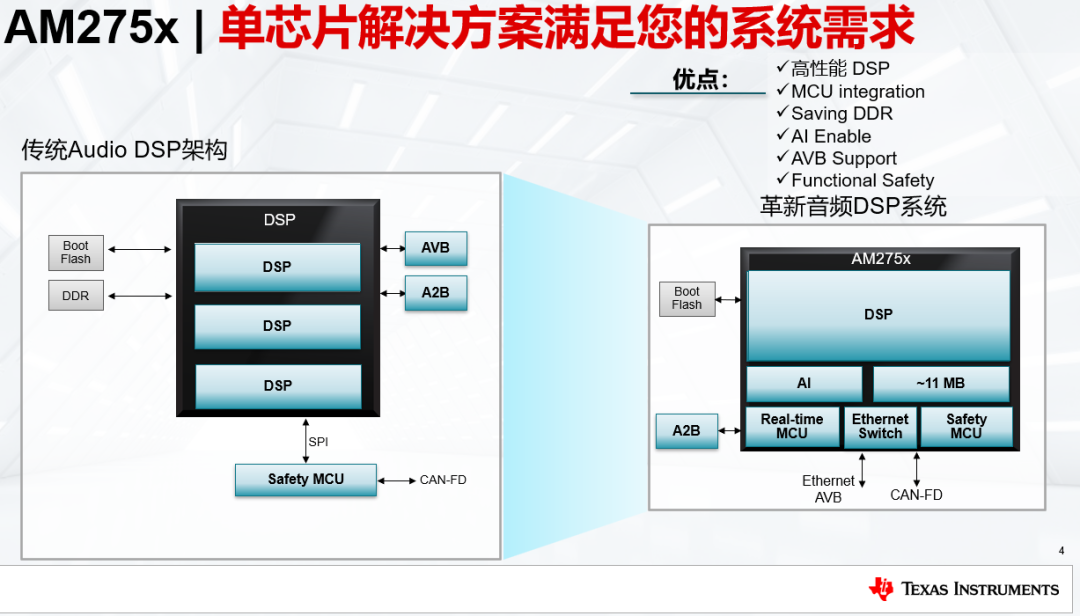
德州仪器(TI)在边缘AI SoC领域布局完善,使用支持 AI 的微控制器 (MCU)、处理器、无线连接和雷达传感器产品系列,在各种应用中部署边缘 AI,通过聚焦低功耗物联网和工业控制场景,提供低功耗、高可靠性和强兼容性的AI应用。借助集成到 TI MCU 中的 TinyEngine NPU,可以将延迟减少 10 至 90 倍,从而直接在器件上更快地进行实时决策。与此同时,TinyEngine NPU的推理能耗较基于 CPU 的实现方案降低超过 120 倍,可实现超高效率的 AI 处理。其结果是在不影响响应能力的情况下,延长电池寿命并提供常开性能。另一方面,集成 C7 NPU的高性能处理器,算力最高可达1200 TOPS,并持续优化每瓦性能。
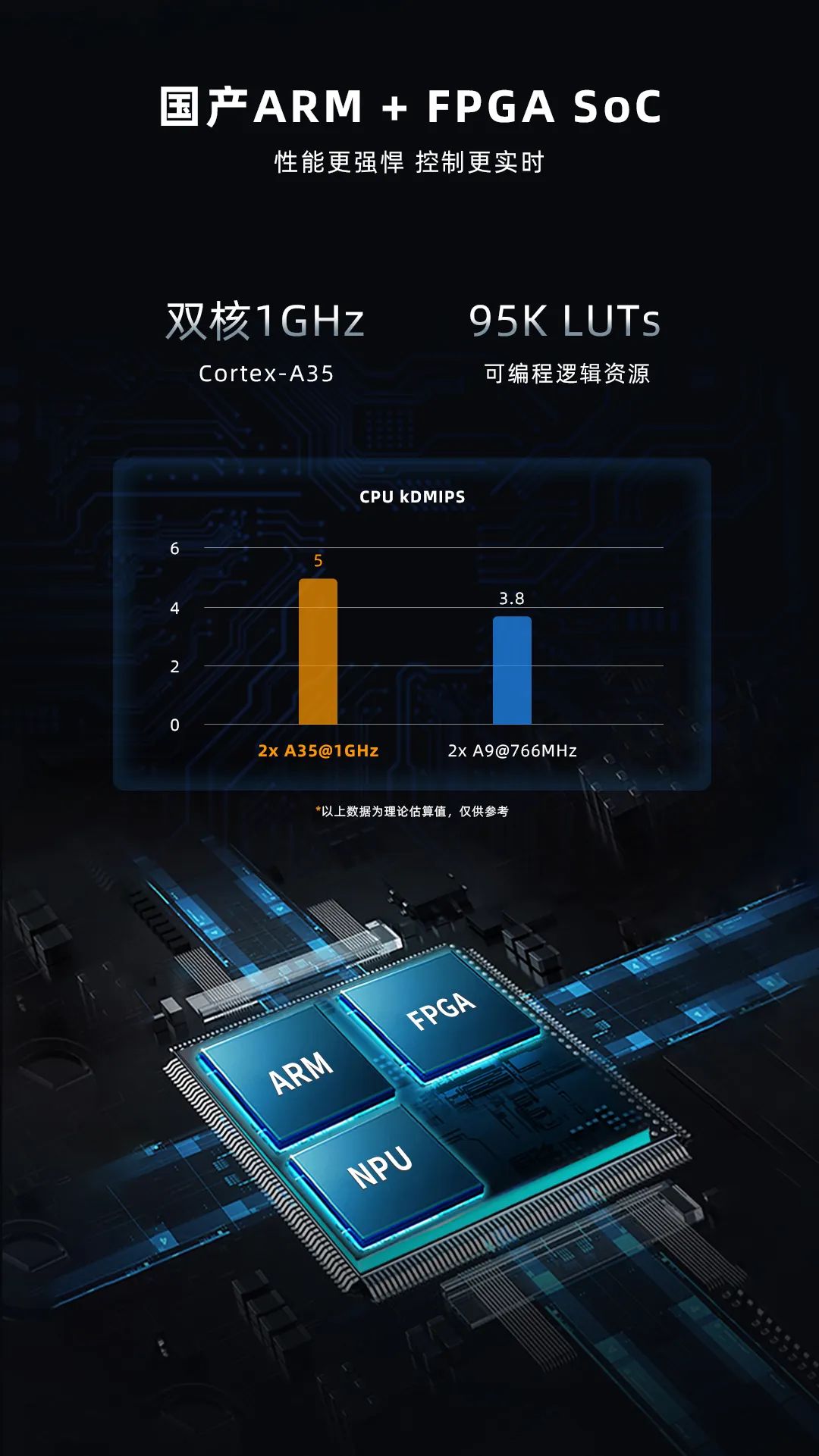
依托其强大的STM32 MCU生态,意法半导体(ST)推出了多款集成NPU的边缘AI SoC产品,重点面向低成本、低功耗的物联网和消费电子场景,核心优势是高集成度、低成本和易开发。代表性产品包括STM32N6系列SoC和STM32MP2系列SoC。STM32N6是ST首款集成NPU的MCU级SoC产品,基于Cortex-M55 CPU,集成意法半导体自主研发的神经处理单元 (NPU)——ST Neural-ART accelerator,计算性能可达可达600 GOPS,支持INT8量化,能够运行简单的AI算法(如人脸检测、手势识别),功耗低、成本低,集成多种物联网接口,适配智能穿戴、智能家居、小型物联网终端等场景。实际测试中,STM32N6支持高达500万像素的图像传感器,能够以每秒30帧的速度处理图像。STM32MP2系列则针对中高端边缘AI场景,采用双核A35+M33架构,搭载高算力NPU,支持多摄像头输入和视频处理,适配工业控制、智能网关等场景,兼容传统STM32开发生态,方便开发者快速迁移。
恩智浦集成NPU的边缘AI SoC产品重点面向车载和工业场景,核心优势是高可靠性、高安全性和强算力。代表性产品包括i.MX 93系列SoC、i.MX 93W系列SoC。i.MX 93系列基于Cortex-A55 CPU(2核),集成Arm Ethos U65 microNPU,NPU算力可达1.5TOPS,支持INT8/INT4量化,能够运行主流的AI算法,集成多种工业和物联网接口,支持低功耗运行,适配工业控制、智能网关等场景。i.MX 93 系列集成 Arm Ethos-U65 microNPU,面向低功耗边缘机器学习;i.MX 93W 在此基础上把无线连接模块集成进单一封装,支持 Wi-Fi 6、Bluetooth LE 和 802.15.4,可减少分立器件数量并降低 RF 设计复杂度。同时集成EdgeLock安全区域,适配医疗设备、工业网关、智能家居中心等场景。恩智浦自研eIQ Neutron可扩展NPU架构,AI性能最高提升172倍,覆盖从MCU到MPU全产品线,配套工具链业内首批支持边缘端LLM部署。
瑞萨电子集成NPU的边缘AI SoC产品重点面向工业控制和车载电子场景,核心优势是高算力、低功耗和高可靠性。瑞萨集成NPU的处理器产品RZ/V系列现已覆盖从低端RZ/V2L(0.5TOPS)到高端RZ/V2H(高达80TOPS)的全系列市场。该系列集成了瑞萨专有AI加速器DRP(动态可重配置处理器)-AI3。得益于先进的剪枝技术,可实现10TOPS/W(每瓦每秒万亿次运算)的能效和高达15TOPS的AI推理性能。其中,最新的RZ/V2N MPU的体积较RZ/V2H显著缩小,封装面积仅为15mm2;安装面积减少38%。RZ/V2N继承RZ/V系列的先进特性,将高性能AI与低功耗相结合。这些优化特性可减少热量产生,无需额外冷却风扇,从而缩减嵌入式系统的尺寸和成本。开发人员可以轻松地在广泛应用中实现视觉AI,从商业设施中用于交通和拥堵分析的AI摄像头、生产线上的视觉检测工业摄像头,到用于行为分析的驾驶员监控系统等。
国内厂商在集成NPU的SoC产品方面也有诸多亮点之作。瑞芯微在边缘AI SoC领域布局完善,推出了多款集成NPU的产品,重点面向消费电子和工业控制场景,核心优势是高算力、高性价比和完善的生态。代表性产品包括RK3568系列SoC、RK3588系列SoC。RK3568系列基于Cortex-A55 CPU(4核),集成自研NPU,NPU算力可达1TOPS,支持INT8量化,能够运行简单的AI算法,成本低、功耗低,集成多种物联网接口,适配智能穿戴、智能家居、物联网终端等场景。RK3588系列则针对高端边缘AI场景,采用Cortex-A76 CPU(4核)+Cortex-A55 CPU(4核)架构,集成自研NPU,NPU算力可达6TOPS,支持INT8/INT16量化,能够运行复杂的AI算法(如YOLOv5目标识别),支持8K视频处理和多摄像头输入,适配智能安防、工业视觉、AI机器人等场景,配套RKNN工具链,方便开发者快速优化和部署AI模型。
边缘AI的规模化普及,彻底改写了终端处理器的市场格局。集成NPU的SoC凭借架构一体化、算力硬件加速、低功耗、高集成、易开发等多重优势,精准匹配边缘AI全场景需求,已然成为市场新宠儿。基于上述多个厂商的参考方案已经可以实现诸多工业和车载场景处理任务全部交给本地SoC运行,无需云端连接,至此本地推理不再是实验,而是下一代工业、物联网、汽车设备的设计标准。











评论区
登录后即可参与讨论
立即登录