冲上热搜!DeepSeek又崩了:一月宕机三次
今日(5月24日),DeepSeek再次出现大规模服务故障,“DeepSeek崩了”话题迅速冲上微博热搜。 有大量用户反馈,使用时遭遇“服务器繁忙”提示,平台服务波动频繁,正常使用受到严重影响。 据悉,这已是本月以来DeepSeek第三次发生大范围宕机,服务稳定性问题愈发突出。 回顾近期故障,DeepSeek的运行状态持续不稳。 5月21日下午,其网页端与App出现大规模异常,深度思考等高负载功能
关于「DeepSeek」的技术文章、设计资料与工程师讨论,持续更新。
今日(5月24日),DeepSeek再次出现大规模服务故障,“DeepSeek崩了”话题迅速冲上微博热搜。 有大量用户反馈,使用时遭遇“服务器繁忙”提示,平台服务波动频繁,正常使用受到严重影响。 据悉,这已是本月以来DeepSeek第三次发生大范围宕机,服务稳定性问题愈发突出。 回顾近期故障,DeepSeek的运行状态持续不稳。 5月21日下午,其网页端与App出现大规模异常,深度思考等高负载功能
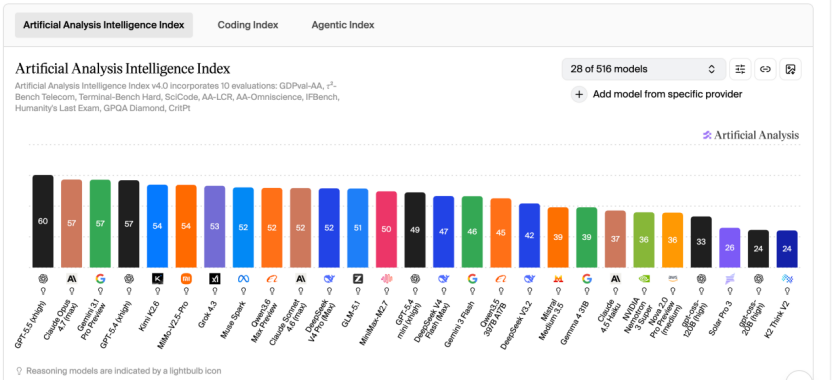
AI全栈,一定是少数者的游戏。 AI即将迎来它的“寡头时代”。 执掌阿里的吴泳铭明确表示:阿里全栈AI技术投入已正式跨越初期培育阶段,进入正向的规模商业化回报周期。 意思是,AI能帮阿里赚钱了。 但帮其赚钱的不仅仅是千问、也不仅仅是阿里云,而是凭借“自研平头哥芯片+千问大模型+阿里云+应用生态”形成的全栈AI能力。 而目前像阿里一样依靠AI全栈能力“稳坐中军帐”的厂商,全球只有大洋彼岸的谷歌。当A
AI芯片目前是国内半导体被卡脖子最严重的领域之一,但它同时也是国产芯片机遇最明确的,而且这一次的逆袭会来得很快,10年时间就能完成全面国产替代。 根据摩根斯坦利公布的一项研究结果,国产AI芯片自给率(主要是GPU类型)在2021年才只有10%,但是发展速度非常快,今年就能达到41%,四年时间份额3倍提升。 接下来的5年中,AI芯片的自给率还会快速提升,到2030年将提升到86%,意味着进口的所有A

距离2026年美加墨世界杯的开幕只剩一个多月了,但这届世界杯在中国大陆地区的转播权方案还没谈拢。最新消息显示,央视拒绝了FIFA开出的价码,双方估计还要进行多轮谈判。无论转播权最后以何种形式落地,大概率都不会影响普通观众的观赛热情。 不管怎么说,世界杯都是个超级大IP,背后有着巨大的流量池,这样的一个舞台自然也少不了AI的表演。 (图源:FIFA) 雷科技(ID:leitech)注意到,2026年
最近几天,一个叫 DeepSeek-TUI 的开源项目突然在 GitHub 彻底火了,仅仅在过去一天,Star 数量直接从 8.7k 又涨到了 16.3k。 DeepSeek-TUI 不是 DeepSeek 官方产品,而是个人开发者基于 DeepSeek V4 开发的终端原生编程智能体。但它涨星的速度很快,吸引了国内外很多 AI 开发者的关注,短短几天时间就冲上了 GitHub Trending

5月6日,一则报道引发市场高度关注:国家集成电路产业投资基金(简称“国家大基金”)正在洽谈领投DeepSeek首轮融资,估值约450亿美元。 几周前,这一数字还停留在200亿美元左右,短短数周翻倍有余,市场用真金白银给出了答案。 国家大基金向来被视为中国半导体产业的“国家队”,重点投向材料、设备、芯片制造等产业链,此前从未公开投资任何一家大语言模型公司。一旦本轮投资落地,这将是大基金首次公开注资本
5月6日消息,据《金融时报》最新报道,国家集成电路产业投资基金(简称“国家大基金”)正在与国内领先的大语言模型公司DeepSeek洽谈主导其首轮融资事宜,该轮融资对DeepSeek的估值有望达到450亿美元(约合3077.95亿元人民币)左右。这一估值较数周前谈判早期阶段的200亿美元直接翻了一番。 就在数周前的谈判早期阶段,外界对DeepSeek的估值还处于200亿美元左右,而现在直接翻了一番,
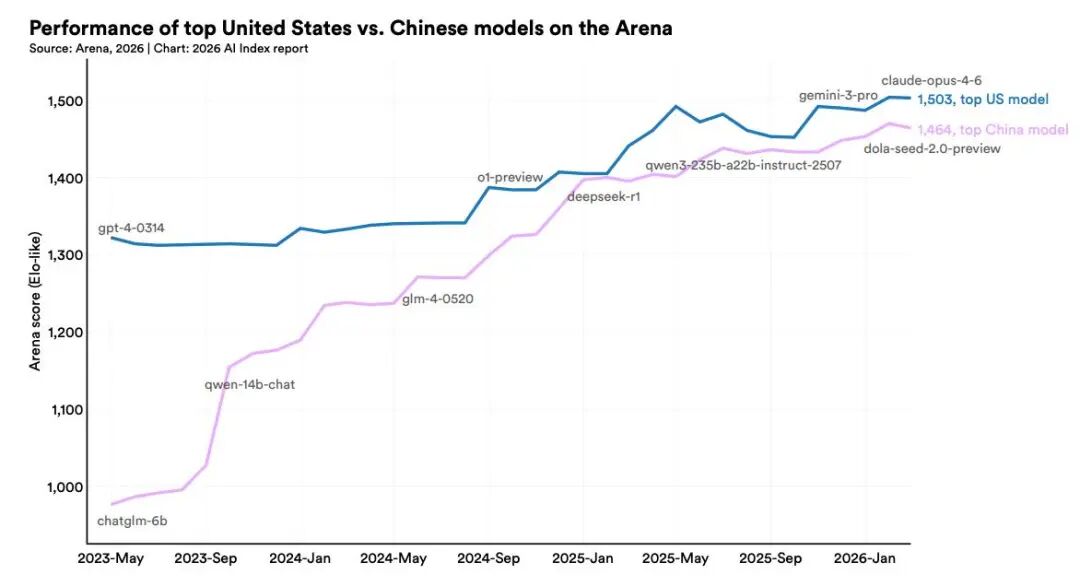
导语 DeepSeek正进行首轮融资,金额高达500亿元人民币,其中创始人梁文锋个人或出资200亿。若顺利完成将刷新中国AI公司融资纪录,其估值也将飙升至515亿美元,重塑全球大模型产业格局。 更值得关注的是,DeepSeek V4.1或于6月登场,主打MCP协议适配与多模态能力。而大洋彼岸OpenAI发布GPT-5.5系列的同时,Anthropic年化收入已突破440亿美元。 在多模态理解、长程
近日,摩尔线程依托旗舰级AI训推一体智算卡MTT S5000与自研MUSA软件栈,基于SGLang 开源推理框架,成功完成DeepSeek-V4的完整运行验证。该成果表明,面向新一代MoE大模型,摩尔线程已构建起从硬件架构核心计算引擎承接、热点算子支持**,**再到端到端部署验证的系统化适配链路,验证了国产GPU平台对前沿大模型“框架级兼容、开箱即落地”的承载实力及工程化落地能力。 随着大模型架构
导语 News Today 2026年4月27日,外商投资安全审查工作机制办公室(国家发展改革委)发布《对外资收购Manus项目作出安全审查决定》。外商投资安全审查工作机制办公室(国家发展改革委)依法依规对外资收购Manus项目作出禁止投资决定,要求当事人撤销该收购交易。 这是《外商投资安全审查办法》2020年实施以来,首个被公开叫停的AI领域外资收购案。从国际比较视角来看,世界主要经济体近年来均
4月28日凌晨,小米技术官方宣布旗舰大模型MiMo-V2.5-Pro及全模态模型MiMo-V2.5正式全球开源。 该系列模型权重已全量开放于Hugging Face等平台,采用宽松的MIT协议,允许全球开发者自由商用、微调及二次训练,无需额外授权。与此同时,小米推出MiMo Orbit计划,宣布于30天内面向全球开发者发放总计100万亿免费Token权益,并与OpenCode、Hermes Age
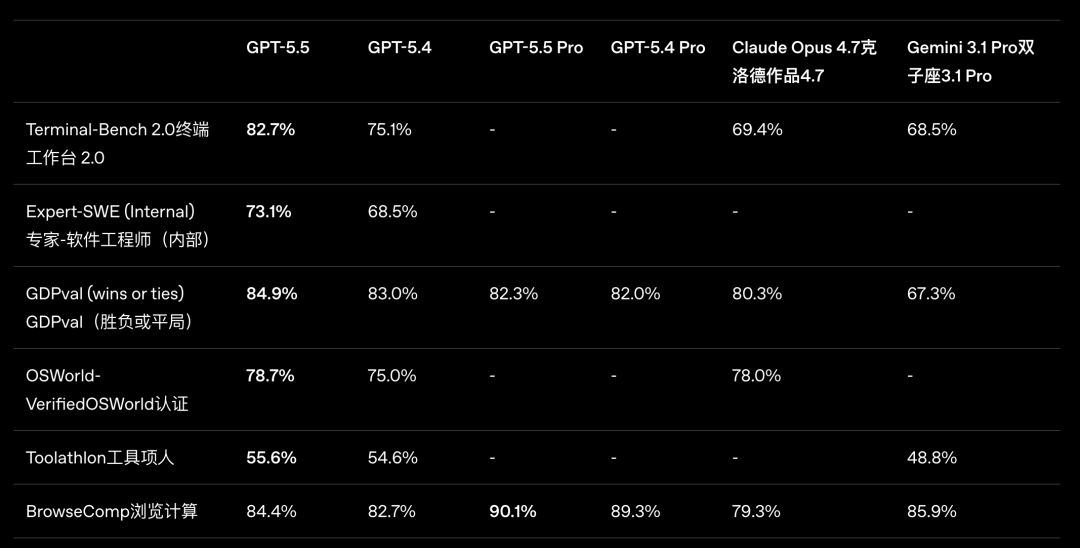
北京时间 4 月 24 日凌晨,OpenAI 突然发布了 GPT-5.5,以及更高规格的 GPT-5.5 Pro。 这不是一次常规的小版本迭代。在 OpenAI 看来,GPT-5.5 不仅是他们最强的模型,更是新的智能模型,即专为真实工作和智能体任务打造的模型。 说白了,其实就是各家最近都在讲的「智能体模型」,模型的定位更多是作为智能体的「智能引擎」。 所以不出意外,围绕「聊天」的各项能力就没那么

今日,DeepSeek-V4正式开源发布,将模型上下文窗口提升至1M,使模型在长序列推理与复杂任务链处理中的表现更加高效与稳定。华为AI数据平台深度适配DeepSeek-V4,将进一步推动大模型从实验阶段走向生产级应用。 DeepSeek-V4发布 带来KV Cache存储的全新挑战 DeepSeek-V4新版本支持100万Tokens的上下文能力。为提升上下文理解能力同时控制显存占用,DeepS
4月24日,摩尔线程宣布,其基于TileLang 0.1.8版本深度优化并已成为TileLang官方主线版本的TileLang-MUSA,已率先在国产全功能GPU上,实现对DeepSeek-V4最新TileLang算子库TileKernels的“Day-0”支持,为大模型关键算子的快速迁移、验证与性能优化奠定了可直接复用的工程基础。 ▼ TileKernels算子库开源地址: https://gi
4月24日,DeepSeek-V4模型正式发布并开源,华为云首发适配。DeepSeek-V4拥有百万Token超长上下文,在Agent能力、世界知识和推理性能上均实现国内与开源领域的领先。其中,DeepSeek-V4-Flash模型参数下降至284B,推理成本进一步降低,模型参数和激活更小,V4-Flash能够提供更加快捷、经济的API服务,实现百万上下文普惠。当前,华为云MaaS模型即服务平台已
2026年4月24日,DeepSeek V4-Pro和DeepSeek V4-Flash正式发布并开源,模型上下文处理长度由原有的128K显著扩展至1M,实现近10倍的容量提升,首次增加了KV Cache滑窗和压缩算法,大幅减少Attention计算和访存开销,并通过模型架构创新更好地支持了Agent和Coding场景。昇腾一直同步支持DeepSeek系列模型,本次通过双方芯模技术紧密协同,实现昇
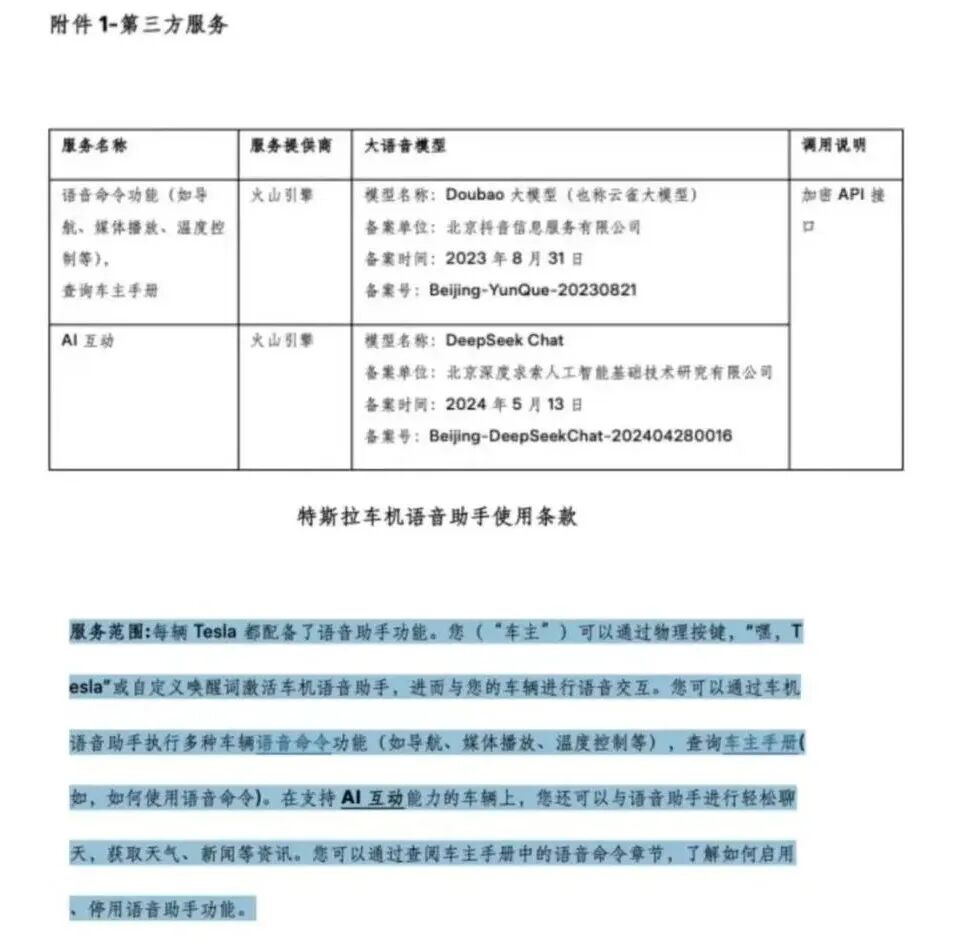
据网信上海消息,特斯拉车机语音大模型服务于4月20日完成备案。这也是自2013年进入中国市场以来,特斯拉车机语音助手的一次大更新。 备受关注的特斯拉中国车机语音大模型服务终于尘埃落定。据科创板日报从知情人士处获悉,特斯拉车机语音服务将接入豆包大模型。按照相关规定,已上线的生成式人工智能应用应在显著位置或产品详情页面公示所使用已备案生成式人工智能服务情况,注明模型名称及备案号,并根据《人工智能生成合

“深度调研426位资深工程师:国产大模型反超?5天工作3天完?AI正如何重塑芯片与嵌入式开发?” 2026年,AI在电子工程领域早已不是“新鲜感驱动”的玩具,而是实实在在的“数字化副驾”。 你是否也在用DeepSeek调优底层的C语言代码? 是否在利用豆包快速解构几百页的DataSheet? 或者正在纠结:AI究竟会成为我的“外挂”,还是会取代我的“岗位”? 为了看清行业的真实底色

据外媒The Information援引多位知情人士透露,中国大模型领域的“技术黑马”DeepSeek(深度求索)正启动成立以来的首次外部股权融资。这家曾长期坚持“自我供血”、多次婉拒资本橄榄枝的企业,计划以不低于100亿美元的估值,募集至少3亿美元资金。 这或标志着DeepSeek正式告别由母公司幻方量化独家输血,转而拥抱资本市场,加入全球AI巨头的资本军备赛。截至发稿,DeepSeek方面尚
4月10日,华为云MaaS模型即服务在海外正式发布,为新加坡、泰国、印尼、巴西、墨西哥、沙特、阿联酋、南非、土耳其9国用户提供高可靠、低时延的优质Tokens服务。本次上线的模型包含DeepSeek V3.2、Qwen3-32B、智谱GLM-5等多款主流开源模型。 卓越性能,重塑生产力 开放的模型生态策略:华为云积极引入中国开源SOTA大模型,本次上线的模型包含智谱GLM-5/DeepSeek V