现在我们用的GPU早就不是当年只用来画游戏画面的显卡了,从AI大模型训练到科学模拟,所有高算力需求的场景里,GPU都是绝对的核心。
今天我们就拿NVIDIA RTX 30系用的GA102芯片来举例,一层一层拆开讲清楚,现代GPU到底是怎么设计出这么恐怖的算力的。
1. GPU算力的增长有多夸张?
先来直观感受一下GPU这三十年的进步:
1996年跑《超级马里奥64》的3D画面,只需要每秒1亿次计算;
2011年玩《我的世界》,就需要每秒1000亿次;
现在玩《赛博朋克2077》开光追跟实时光影,单颗GPU需要每秒36万亿次计算才能流畅运行。

换个更直观的对比:全球80亿人,每个人每秒做一次乘法,加起来也才每秒80亿次运算。这个集体算力,还不到一颗高端GPU的四千五百分之一。
这种差距不是堆核心就能堆出来的,是GPU从设计底层就针对大规模并行计算做了优化,才有今天的结果。
2. CPU和GPU:完全不一样的设计思路
很多人分不清CPU和GPU到底差在哪,用一个很经典的类比就能讲清楚:
CPU就像大型客机,核心数量少,但每个核心都很强,也很灵活,能处理各种各样的任务。跑操作系统、管理外设、处理复杂的分支逻辑,靠的都是CPU的低延迟单线程性能,就像客机能飞到全世界各个机场,通用性极强。
GPU就像大型货轮,造了几千上万个简单的小核心,不追求单任务的低延迟,追求的是整体吞吐量。它一次就能拉海量的数据,比如图形顶点、像素值、AI矩阵参数,批量做重复的运算。虽然单个操作的延迟比CPU高,但一次拉的货是飞机的几十上百倍,总效率高太多了。
我整理了两者核心差异对比:
CPU一般是6到24个高性能x86核心,能跑操作系统、复杂分支逻辑、网络协议栈各种任务,特点是低延迟、低吞吐量,接口支持硬盘、网络、USB各种类型,适合处理串行、控制密集的复杂任务。
GPU一般是一万个以上CUDA核心再加几百个专用核心,只需要处理算术、向量计算、着色这类窄指令集,特点是高吞吐量、单个操作延迟高,接口只有PCIe、NVLink、显示接口这类高带宽专用通道,天生适合跑高度并行的任务:3D渲染、AI训练、加密哈希计算都是典型。
简单说就是,CPU管灵活应变的杂事,GPU管批量重复的算力活,分工不同,设计思路完全不一样。
3. 现代GPU物理架构拆解:GA102为例
我们以NVIDIA RTX 30系列用的GA102芯片为例子,把GPU一层层拆开看。

GA102核心GPU拆解图,露出散热风扇、PCB各组件
几十亿晶体管的硅芯片
GPU核心就是一块几平方厘米的硅片,GA102这块小小的芯片里,塞了283亿个晶体管。晶体管就是数字开关,一开一关代表0和1,没有这么高的晶体管密度,每秒万亿次计算就是天方夜谭。
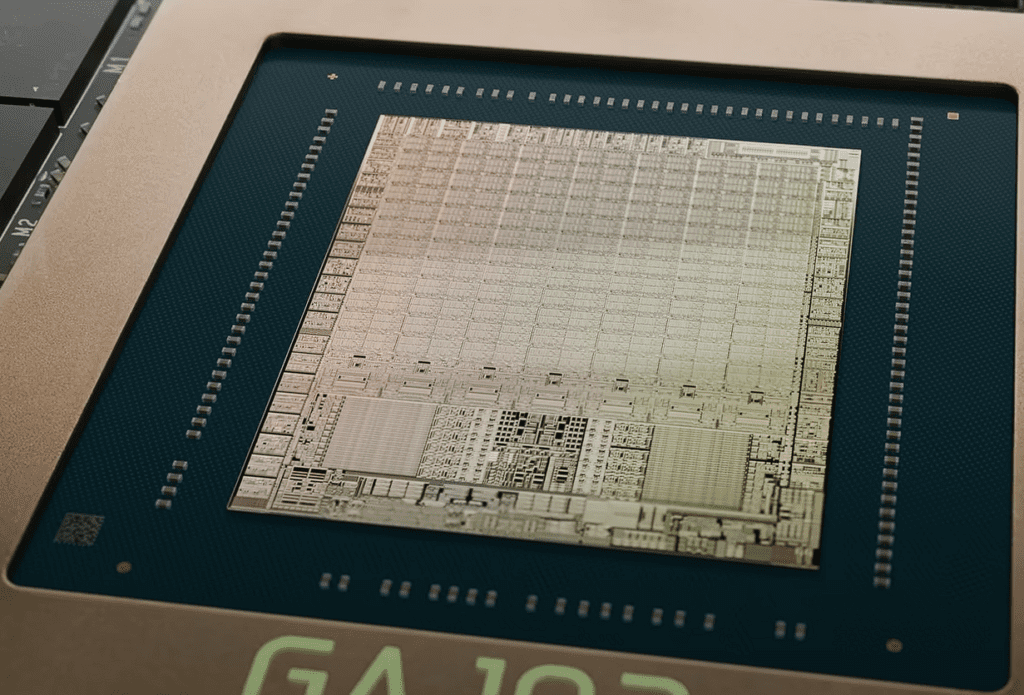
GA102芯片上剖片图
分层设计的计算单元
这么多晶体管不能乱堆,现代GPU用的是分层嵌套的结构来组织计算资源:
第一层是图形处理集群(GPC),GA102一共做了7个GPC,每个GPC都是一个独立的模块,各自处理一部分渲染任务。

每个GPC里面又分了12个流多处理器(SM),GA102总共有84个SM,SM就是GPU里真正负责分发执行线程的主力干活单元。

GA102的GPC内部84个流多处理器(SM)网格布局图
SM(流处理器)再往下细分,到最核心的计算单元:
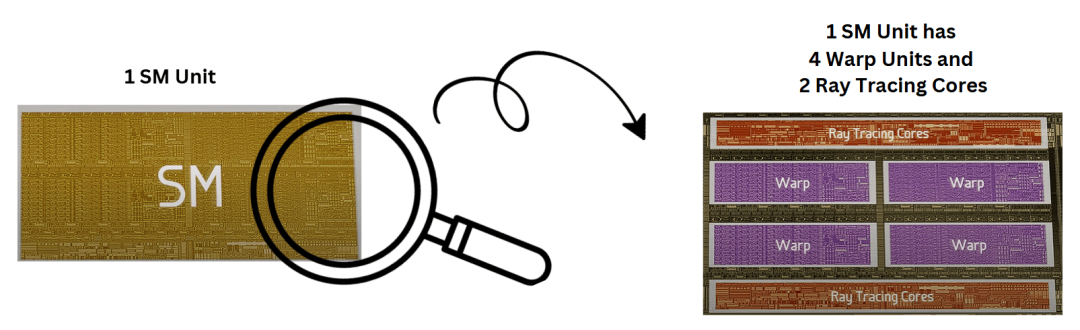
单个流多处理器(SM)放大图,显示四个Warp单元和两个RT核心

Warp:一个Warp就是32个线程组成的小组,一起并行执行同一个指令序列。
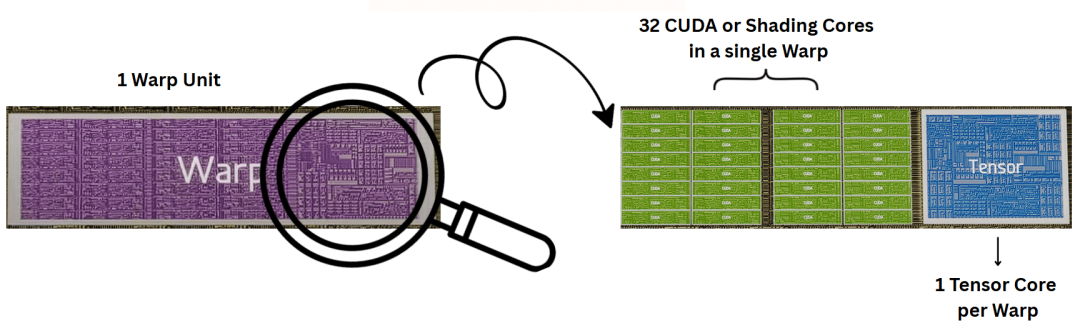
单个Warp放大图,展示32个CUDA核心加1个Tensor核心的布局
CUDA核心(着色核心):每个Warp配32个简单算术单元,GA102总共有10752个CUDA核心,专门负责加减乘、按位逻辑这类基础操作,速度极快。

Tensor核心(张量核心):每个Warp配1个,GA102一共336个,专门做矩阵乘加运算,是AI计算的核心专用单元。
RT核心(光追核心):每个SM配1个,GA102一共84个,专门负责处理光追的加速结构和光线碰撞检测,是实时光追的硬件基础。
总结一下:GA102芯片核心计算单元,一共有10752个CUDA核心、336个Tensor核心、84个RT核心。
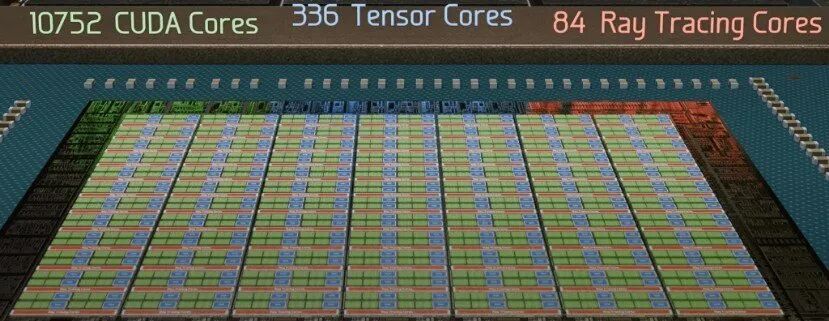
GA102芯片核心分区图,标注10752个CUDA核心、336个Tensor核心、84个RT核心
这种分层设计能把大任务拆成小任务,调度效率特别高,能让芯片上几乎所有计算资源都跑满,不浪费。
单个CUDA核心里有什么?
别看CUDA核心小,一个里面就藏了差不多41万个晶体管。其中大约5万个用来做乘加单元(FMA),能在一个时钟周期里就算完A×B + C,剩下的晶体管用来做移位、掩码、控制逻辑。

GA102的boost频率是1.7GHz,每个核心每秒就能做17亿次乘加运算,RTX 3090开起boost来,总共有10496个活跃核心,算下来就是每秒大约35.6万亿次浮点运算(FLOPS),这个算力放在十年前,要一整个超级计算机机房才能做到。
每个SM还配了4个特殊功能单元,负责处理除法、平方根、三角函数这类没法直接用乘加单元算的复杂操作。
存储控制、缓存和输入输出
计算集群周围,就是支撑计算的配套电路:

GA102芯片标注图,标出L2缓存、Gigathread引擎、PCIe接口位置
存储控制器:GA102用12通道GDDR6X显存,拼出384位的总线,持续带宽能做到每秒1.15TB,这个速度能一秒传完差不多300部普通高清电影。
片上缓存:所有SM共享两个3MB的L2 SRAM缓存,每个SM自己还有128KB的L1缓存,这么设计就是为了减少对外部显存的访问,毕竟访问显存比访问片上缓存慢太多也费电太多。
Gigathread引擎:负责管理所有GPC和SM的任务调度,平衡负载。
PCIe和NVLink:高速串行通道,用来把GPU连到CPU、主板,或者连其他GPU做多卡并行。
显示输出:一般是1个HDMI加3个DisplayPort,直接输出画面到显示器。

GPU PCB边缘特写,展示3个DisplayPort和1个HDMI接口
供电和散热设计
这么大的算力,要喂饱还要压得住温度,可不是一件容易事:
电压调节模块(VRM):把PCIe供电进来的12V电压,降到GPU核心需要的1.1V左右,同时能输出几百瓦的功率,保证核心满载的时候不会掉电压。
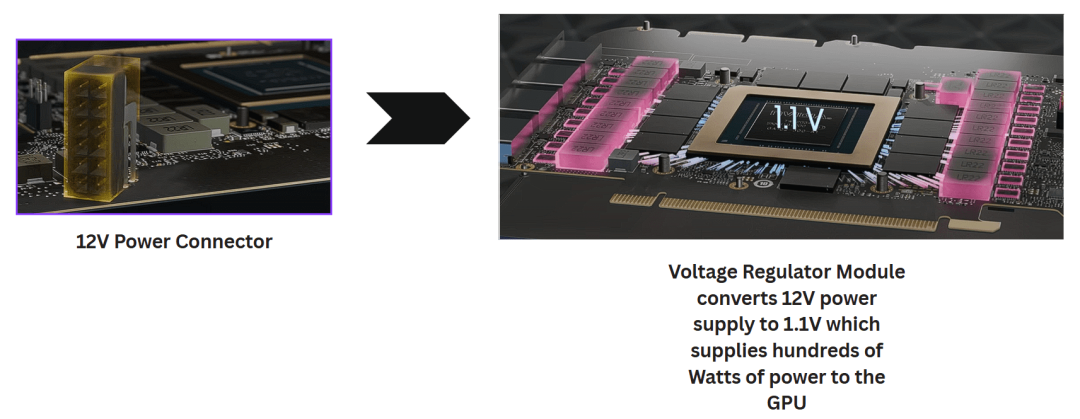
12V供电输入到VRM,降压到约1.1V供给GPU核心的示意图
散热:一般都是大体积铝鳍片加铜热管,把核心的热量导出来,再用高风量风扇吹到空气中,把热量带走,保证核心不会因为温度太高降频。

GPU大型散热套件:带铜热管和高风量风扇
芯片分级:同一颗晶圆做不同产品
晶圆生产出来,难免会有部分小缺陷,直接扔掉太浪费,厂商就会做分级:把不同缺陷程度的芯片,屏蔽掉有问题的部分,做成不同档次的产品卖。
GA102就分出了四个常见产品:
RTX 3090 Ti:全规格无缺陷,10752个CUDA核心,是顶级旗舰
RTX 3090:屏蔽了两个有缺陷的SM,剩10496个CUDA核心,次旗舰
RTX 3080 Ti:屏蔽四个,剩10240个,中端主力
RTX 3080:屏蔽十六个,剩8704个,入门高端
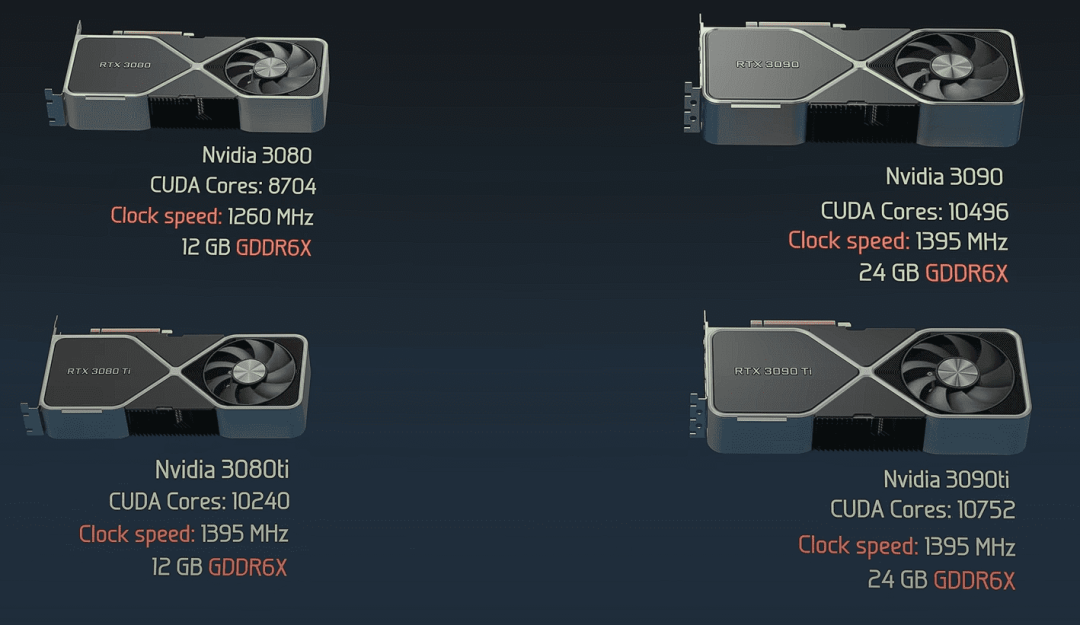
四款基于GA102的GPU对比图,标注核心数、频率、显存容量差异
除了核心数,不同型号的频率、显存容量(10G到24G不等)、功耗限制也会做区分,覆盖不同价位的需求,这也是半导体行业通用的做法,能最大限度降低成本。
喂饱算力:不同显存技术对比
GPU是出了名的数据黑洞,几千个核心要不停干活,必须持续不断喂数据,现在主流的高端显存技术有三种,各有各的特点:
GDDR6X SDRAM
高端卡一般用24颗1GB的芯片,总容量24GB。它用了PAM-4信号技术,一个时钟周期每个针脚能传2个bit,用四种不同电压表示,不用增加针脚数量就能把吞吐量翻一倍,384位总线的总带宽能超过每秒1.15TB。
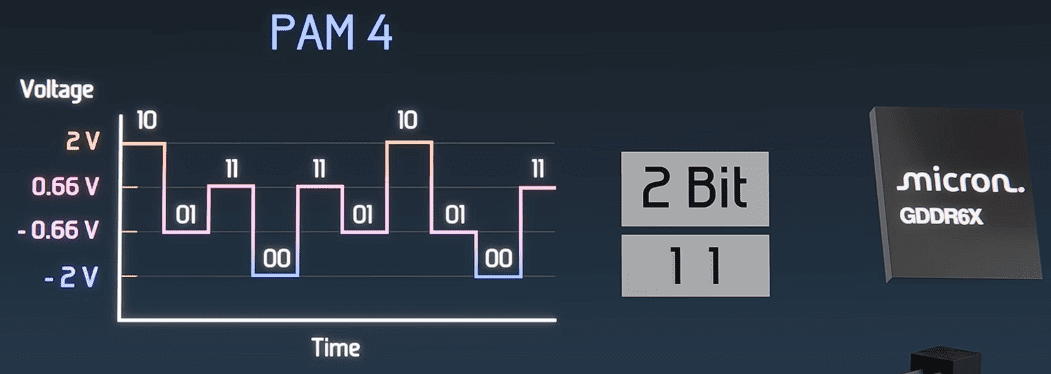
PAM-4信号示意图,四种电压等级每个周期编码2bit
对比一下,CPU的内存总线位宽一般是64位,带宽大约每秒6GB,差了快两百倍,就能看出来GPU对显存带宽的需求有多大。
GDDR7 SDRAM
GDDR7用了PAM-3编码,用-1、0、+1三种电压等级编码数据,比PAM-4更省电,信号完整性也更好,能把传输效率再提一档。
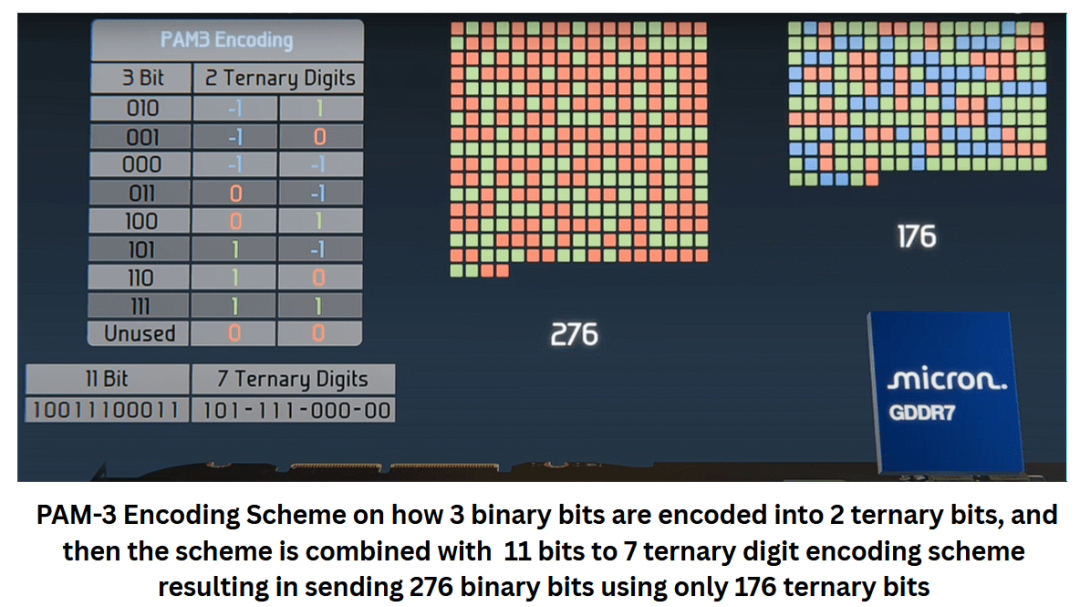
GDDR7的PAM-3编码二进制转三进制示意图
HBM高带宽显存
HBM是现在AI加速卡最喜欢用的显存技术,它把DRAM芯片叠起来堆成立方,用硅通孔(TSV)把不同层连起来,做成一个整体的存储芯片。
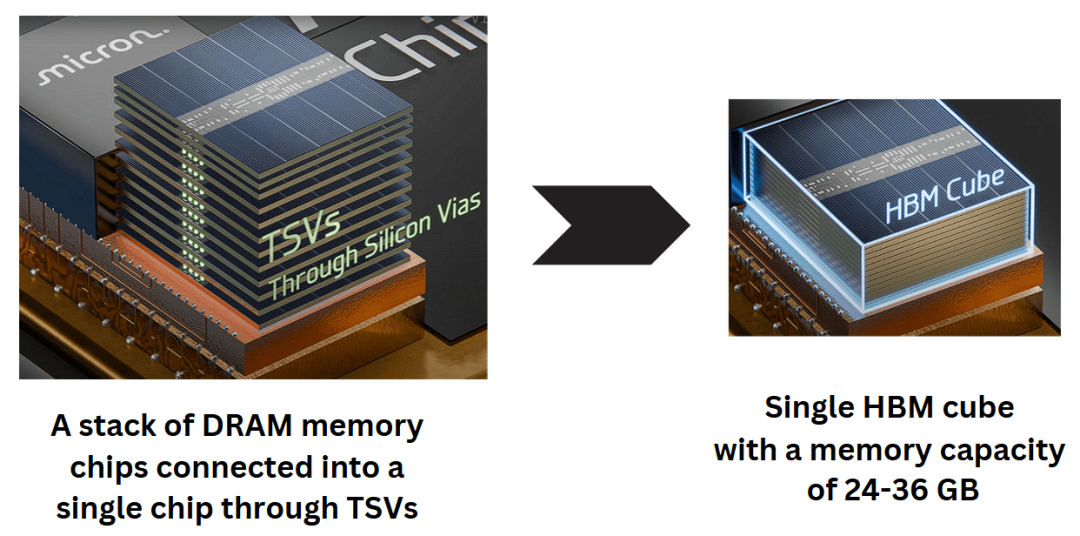
堆叠DRAM芯片通过TSV互联,组成高带宽存储立方示意图
单颗HBM3E立方就能做到24GB到36GB容量,单颗带宽就能做到每秒192GB,非常适合AI加速卡用。
4. 并行计算模型:从SIMD到SIMT
GPU天生适合跑高度并行任务——也就是同一个操作,独立套用到海量不同数据上的任务,比如3D顶点变换、图片像素滤镜、加密哈希计算、神经网络矩阵运算,都是典型的并行任务。
GPU处理并行任务的模型,也走过两代进化:
SIMD:单指令多数据
早期的并行模型,一条指令同时驱动一组固定宽度的数据通道,同步执行。好处是适合完全统一的任务,但如果遇到分支跳转,灵活性就很差,会卡。说人话就是,早期GPU一条指令管一堆数据,必须所有人同步走,不能有人走快有人走慢。

早期SIMD模型示意图:单指令广播到所有数据通道,同步执行
SIMT:单指令多线程
这是NVIDIA搞出来的创新,每个线程都有自己的程序计数器,解决了分支的问题:
同一个Warp里的线程哪怕走了不同的分支路径,也能分开处理,之后再重新汇合,这叫Warp分歧处理,比SIMD灵活太多。

SIMT模型示意图:每个线程有独立程序计数器,支持灵活执行

SIMT的Warp分歧示意图:线程共享L1缓存,可以分歧后重新汇合
整个SIMT也是分层的:
单个线程:在一个CUDA核心上执行一个指令数据对
一个Warp:32个线程,一起发同一个指令,但支持管理分歧
一个线程块:一组Warp,分配给同一个SM
一个网格:一个内核启动的所有线程块
Gigathread引擎:硬件调度器,负责把线程块分配到SM,平衡负载
这个灵活的模型,让开发者能写通用GPU代码,同时还能保留大规模并行的性能,现在我们用GPU做AI、做科学计算,都是靠这个模型撑起来的。
5. 实际场景的GPU干活例子
3D图形渲染
举个简单的例子,给一个14000个顶点的牛仔帽模型做坐标转换:模型本身的顶点是相对于自己原点的,要放到整个场景里,就要给每个顶点坐标加上模型在场景里的位置向量。
这个操作就是典型的并行任务——每个顶点的计算完全不影响其他顶点,上千个CUDA核心可以同时开工,一下子就算完了。从旋转、缩放、投影到光栅化、着色,每个步骤都能拆成并行任务,几千个核心一起跑,速度自然快。
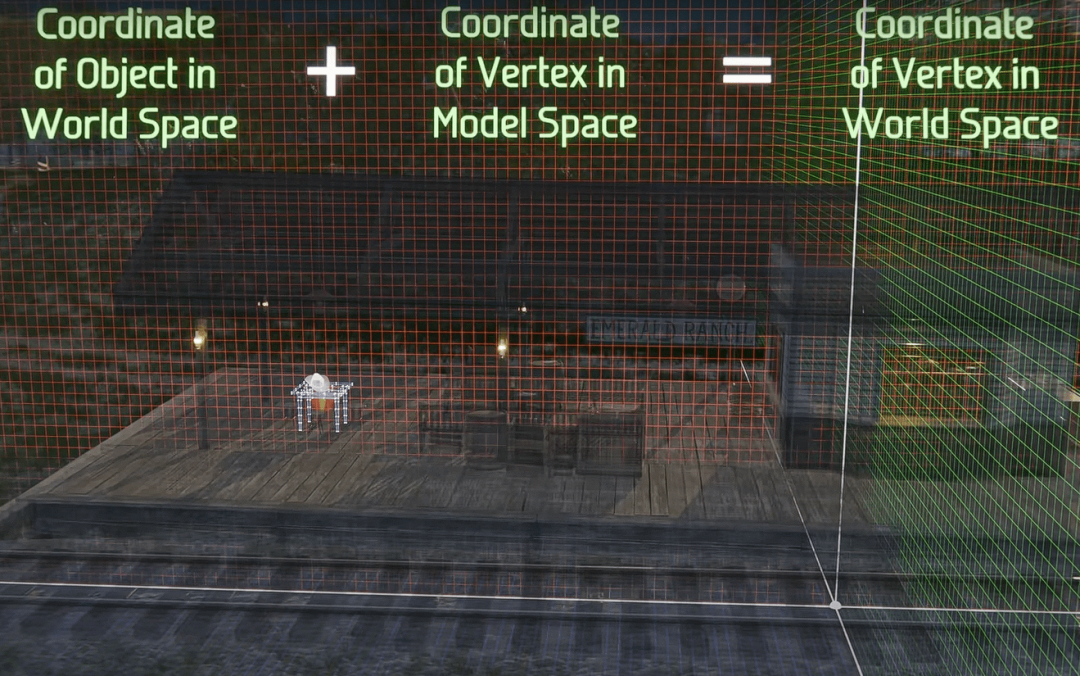
顶点变换示意图:给模型空间每个顶点加上世界位置坐标
加密货币挖矿
早年比特币挖矿,GPU一秒能算9500万次SHA-256哈希,每个nonce(随机数)都是独立计算,刚好适合GPU并行。现在ASIC专用矿机已经能做到每秒250万亿次哈希,把GPU远远甩在后面,也能看出来越专用的硬件,在特定任务上性能越强。

GPU每秒计算9500万次SHA-256哈希示意图
神经网络训练和推理
AI现在能发展这么快,GPU的Tensor核心功不可没。Tensor核心直接在硬件里做D = A×B + C的矩阵乘加运算,这正是神经网络里最常见的操作。

Tensor核心执行矩阵乘加D=A×B+C运算,适配神经网络任务示意图
它还支持混合精度计算,用FP16/INT8算术提升吞吐量,同时不损失精度。现在训练一个大模型,一次就要完成几万亿到几百万亿次矩阵运算,没有Tensor核心的加速,根本不可能在可接受的时间里训完。
6. 总结
现代GPU是半导体创新、并行计算理论和工程实践结合到极致的产物。从几平方厘米硅片上的几十亿晶体管,到分层调度的计算单元,再到专门优化的显存技术,GPU硬是把过去只有超级计算机才能有的算力,塞进了每个人电脑里的一块卡。
不管是渲染虚拟游戏世界,还是加速AI大模型训练,或是做科学模拟,GPU一直在重新定义计算的边界。
接下来随着新显存标准普及、更灵活的并行模型落地,还有和CPU更紧密的集成,GPU的创新速度只会越来越快。
接下来还能跑出什么新的可能性,我们拭目以待。
参考:
1.https://learnopencv.com/modern-gpu-architecture-explained/
2.https://www.youtube.com/watch?v=h9Z4oGN89MU
END 不代表中国科学院半导体所立场





评论区
登录后即可参与讨论
立即登录