引言:边缘AI涉及的问题不仅是算力芯片,还与存储、设计工具、测试等方方面面有关…
AI从数据中心走向边缘、端侧的原因这两年探讨得够多了,包括数据中心资源限制(与海量IoT设备与数据涌入的矛盾)、部分应用的低延迟或实时决策需求、隐私与安全性、AI应用的个性化要求等;与此同时,随着AI全栈技术的发展,边缘或端侧AI也正走向成熟——无论是硬件还是包括AI模型在内的软件。
前不久IIC Shanghai 2026同期举办的边缘AI与算力芯片论坛上,华邦电子资深工程师雷家锋在主题演讲中给出了一组边缘AI市场发展趋势数据:2023-2030年,边缘AI市场的CAGR(年复合增长率)在21%左右(来源:华邦)。
这是边缘AI与算力芯片论坛近两年持续火热的重要背景,也是市场海量玩家未来发展的关注点。恰巧参与本届论坛主题演讲的企业涉及NPU、GPU、存储、测试、市场研究。本文就从这几个方面做边缘AI技术发展现状的零散呈现——或许读者也有机会从中发现更多当代边缘AI技术的特点。
NPU进化:要满足当代大模型推理需求
去年国际电子商情杂志4月刊封面故事就提到,在短短2年时间里,达到GPT-3相似智能水平的AI模型,推理成本下降了多达1200倍:这是AI技术全栈发展所致,不仅是芯片或硬件的性能提升。国科微AI算法部部长倪亚宇在主题演讲中就谈到了FlashAttention-4,就是Transformer模型之中的典型算法优化;并由此引出NPU架构设计的思考与实践。
倪亚宇介绍说FlashAttention“通过这一软件方案、借助流水线的编排、带宽压缩等,第4代实现了将近5倍的推理加速。”FlashAttention V4相比V3在部分场景下可达2倍以上提升,“还加入了AI预编译技术”——“对不管GPU还是NPU而言,都是个无本万利的技术。”
“从以往更强调tensor的GPU和NPU来看,LLM推理面临的瓶颈往往在注意力计算上,矩阵乘算力利用率低。”尤其是在decode阶段,注意力成为主要瓶颈。FlashAttention则“通过一个有趣的数学变换,最后落在GPU上将计算过程藏在矩阵乘之中,最终能够将attention部分(所需时间)压到1/5左右”;“而且变换之后,注意力的3次矩阵乘计算不会出SRAM,省去3次DDR读写,带宽需求也大幅降低。”
现在的绝大部分NPU都能通过tensor和vector单元来支持FlashAttention的部分特性,获得一定的存储、IO和cycle收益。但倪亚宇表示,NPU离实现“满血版FlashAttention还有很大鸿沟”,具体如下图所示。“NPU当年设计时陷进一个误区或者说思维定势:强调堆tensor计算单元。”
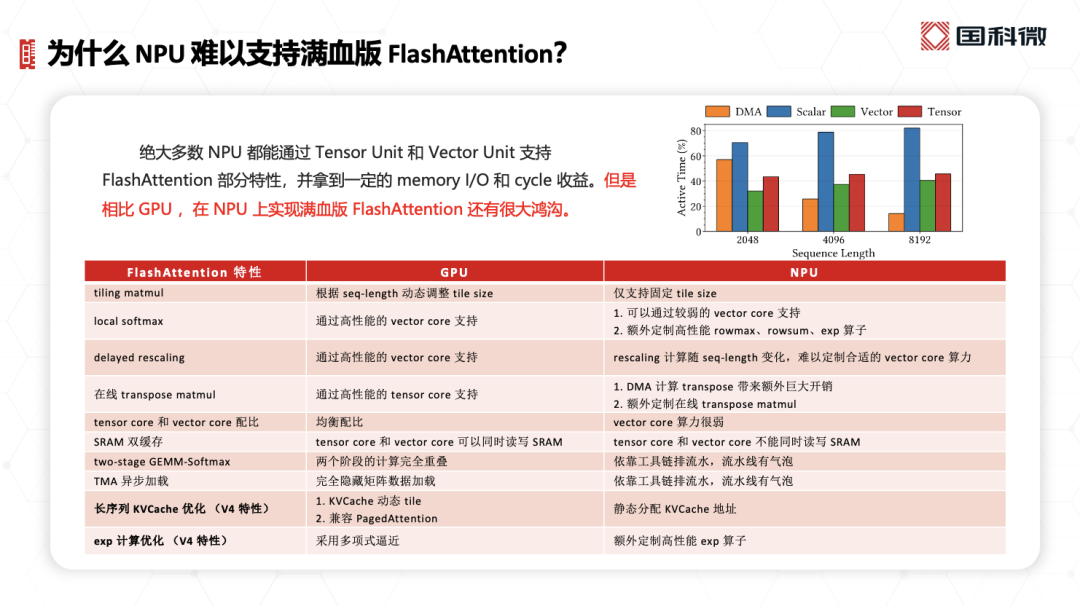
“在大模型推理、agentic AI、小龙虾时代,推理序列越来越长,矩阵在其中所占算力比重反而没那么大;向量计算、常数计算的耗时却越来越大。”“简单来说,vector, scalar算力不够,与NPU的矩阵乘能力不匹配;还有一些问题,比如tensor core与vector core不能同时读写SRAM,以及诸多流水线的限制...”
对于这些问题,倪亚宇介绍了学术界此前给出的一套相对激进的解决方案:FSA(增强型脉动阵列架构)架构NPU。“干脆就不要vector单元,将vector做到矩阵乘里面去”;“增加12%的面积,加了一些逻辑单元,在算矩阵乘的同时,支持做注意力相关计算”。
这套方案的具体改进包括“双向数据路径:新增向上数据通路,支持rowmax/rowsum等在线reduce操作”;“列级比较器阵列:在MAC阵列顶部部署专用比较器,实时完成rowmax计算”;“线性插值扩展:每个处理单元新增Split单元,复用MAC完成exp函数的分段线性插值(PWL)近似”——“基于上述扩展,FSA在阵列内原生实现FlashAttention全流程操作”。
只不过在倪亚宇来看,这是个有借鉴价值,但于产业界未必实用的方案。比如他提到,“增加12%的面积如果直接放在vector单元上,会不会更实用?”“毕竟NPU不仅要考虑大模型推理,还要兼容各种各样的模型推理;如此才能实现更强、更综合的NPU设计。”
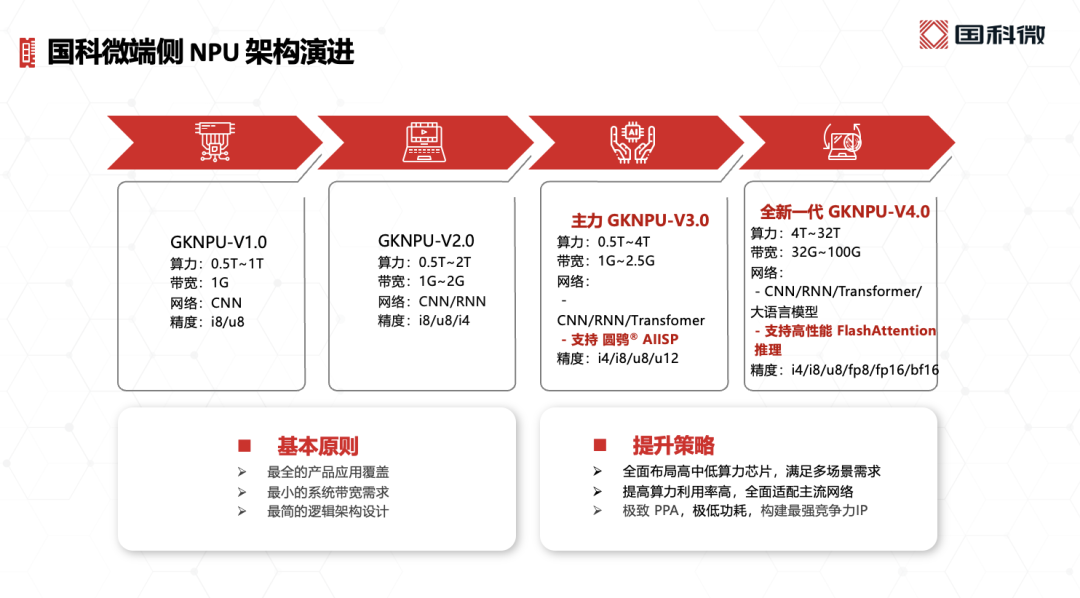
这些除了体现国产NPU在发展之路上的创新与思考,也在于国科微的端侧NPU架构已经过了几代演进——如上图所示。“我们做NPU将近8年时间:从第1代开始就做全栈自研;V2.0做端侧小算力,兼顾CNN模型实践;第3代主力算力提高,不仅支持卷积也支持Transformer,也是我们的圆鸮AIISP黑光全彩算法的主力推理芯片。”
“第4代正在研发,开始走向中高算力(4T-16T)。就像前面谈到的,我们还对整个流水线和架构做了重新设计,实现更低功耗、更低成本的大模型推理。”“不仅在矩阵乘、vector、scalar等方面做了算力平衡,双tensor core还支持异步矩阵乘,支持UB并行读写,在线transpose、快速scaled Softmax等等...”总体而言,“这代NPU是更为务实的设计。”
另外倪亚宇还提到配套“更激进进化”的软件方案(GK Toolchain V3.0):“整套工具链基于MLIR基座,构建了一套能够覆盖NPU研发全流程的软件栈,覆盖芯片仿真、模型编译,和端侧灵活推理。”
其中有不少特性是能够体现国科微的创新:除了这是“国内较早就做到离散化的最优配置搜索”,以及“硬件感知的模型预编译”实现性能优化的同时做到更大程度的自动化;针对“动态推理优化”部分,比如Flash-DRAM混合——基于“大模型里面接近20%的参数是embedding的(把离散的token映射到连续向量空间的权重矩阵),加载频率较低,放进flash之中对推理耗时影响微乎其微,却节省了DDR存储;对于很长的KV cache,也有小部分可以放进flash之中,通过流水线重排可以隐藏延时,实现推理成本的节约。”
GPU要实现边缘AI高效推理,不光是算力问题
除了NPU之外,参与边缘AI与算力芯片论坛的GPU相关企业也是少不了的。Imagination作为历届IIC大会的常客,也在论坛上分享了其E系列GPU IP对于边缘AI大规模落地的价值和重要性:不单是算力,而要同时考量计算、存储、功耗、软件的平衡。
如Imagination产品总监郑魁所说,“计算能力之外,如何提升计算效率,就要考虑做好memory架构设计、考虑power,还要加上软件”,“这4点是Imagination GPU架构向前演进的基本出发点”。郑魁重点谈到了memory的层级结构(hierarchy)设计,对发热的控制,以及模型发展速度之快要求硬件灵活性,都是边缘AI应用需要考量的。
“E系列的目标就是要提高计算效率、对模型的利用率,提高整个系统层面的效率,减少部署的开销。”去年,电子工程专辑对Imagination的E系列GPU IP做过比较详细的介绍。除了Burst Processor新架构带来相较上代25%的能效提升(具体负载平均FPS/mW提升),E系列的另一大看点是USC之中的Neural Core能够大幅提升AI算力。
郑魁在演讲中说,E系列GPU“能够提供出色的性能伸缩(scaling),不管是tensor级别的,还是多核,乃至多chiplet的scaling”——这也是Imagination GPU IP一直以来的优势。如下图所示,在AI性能表现上,除了对诸多数据格式的广泛支持,“8个USC处理单元/核的4核GPU,能够提供200 TOPS INT8算力。”

如前所述,不止于TOPS数字,郑魁在此还强调了Imagination在E系列架构设计中,为打破存储墙、提升AI推理效率所做的各种努力。比如说最短的数据路径,最小化数据迁移,尽可能让数据保持在本地。
“GPU具备高并发能力”,“对于GPU架构而言,我们建议比如将原本DSP、VPU的很多workload放到GPU之中,充分利用GPU的高吞吐、高并发SIMT能力,令内存使用天然更友好”。“因为GPU有着很大的register、local shared memory,具备高效的内存管理能力。”E系列GPU IP在这方面的优势就体现得淋漓尽致,如最大化数据复用、高度的硬件模块复用,以及面向开发更友好和标准的编程范式等。
另外,针对模型“Imagination也有自己的优化方式,比如量化:支持全面的数据格式,也有量化工具;结合压缩算法和硬件加速单元”,提升AI推理效率。“我们在这些领域(无损压缩)已经发布了对应的研究paper。”郑魁介绍说。
除此之外,他还提到了GPU在开发方面具备灵活性和标准化的优势,以及Imagination现如今的GPU IP具备诸如硬件级虚拟化支持、更高安全性等特点——电子工程专辑的历史文章对这些皆有详细介绍,感兴趣的读者可移步阅读。
值得一提的是,Imagination的GPU IP在边缘AI应用的另一个关键价值还在于超高的灵活性:包括它不仅限于AI应用,还支持图形渲染和其他任务类型的通用计算加速;与此同时,Imagination也强调,自家GPU不仅可藉由伸缩能力来搭建更大规模的算力基础设施,而且也可以搭配三方NPU做异构计算,”实现最大化的pipeline overlapping”。

走向2.5D/3D堆叠:芯片设计范式要变
AI技术不仅对AI芯片提出了更高的要求,就连AI芯片设计工具也要变。比如说,谈AI芯片就不得不谈先进封装——而当涉及先进封装、异构集成、chiplet,芯片与电子系统设计的方式就要变。
2.5D/3D先进封装的本质,就是将die/chiplet以横向或纵向的方式做同封装内的堆叠。珠海硅芯科技有限公司创始人兼CEO赵毅在演讲中说,“由于AI的推动,现在我们能看到最多的可能是逻辑+HBM die的堆叠;未来还会有各种形式的堆叠,比如模拟+数字+射频...”
他举例提到业界前不久“很火的一颗3.5D芯片,整个SoC拆成了compute die, IO die, memory die;且三颗die垂直堆叠。虽然看起来就3层,但从设计、仿真、测试流程来看,需要解决的问题非常之多。”“在堆叠场景发生变化的情况下,于设计工具链而言也提出了新需求。”
总的来说,“当先进封装碰上EDA,整套EDA工具链、design flow都会发生重大改变;且在全新工具链之外,“一定要加上先进封装各种类型工艺的深度协同,并考虑堆叠的具体场景”。即简单来说,工具链要变,设计范式也要变。这对EDA市场参与者而言就构成了挑战。
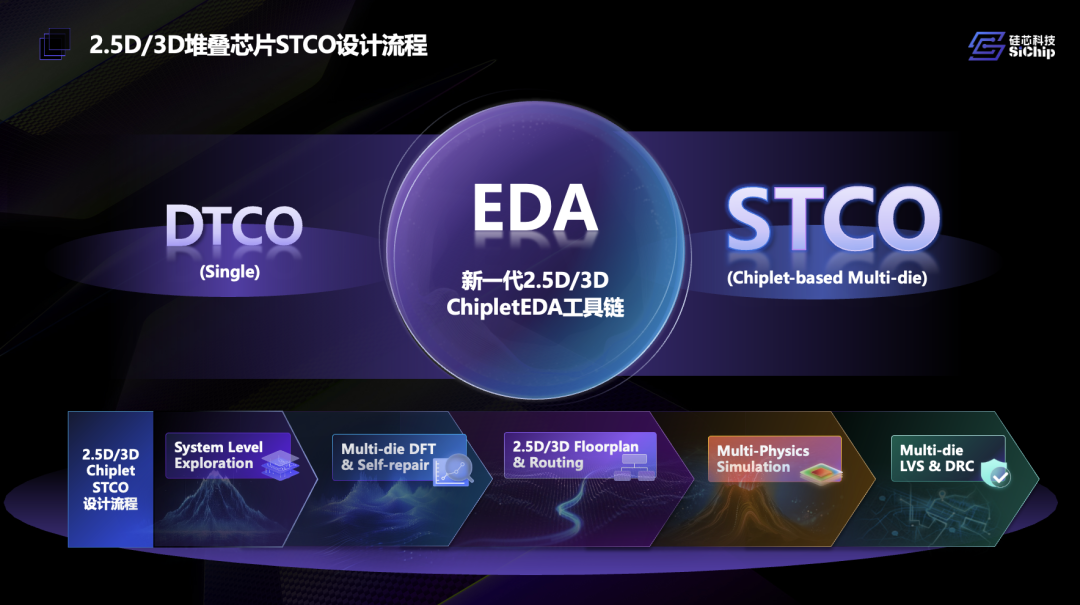
设计流程上发生的转变,是从单芯片的DTCO走向了多芯片的STCO(system-technology co-optimization)。首先是顶层架构探索规划:每片die的类型、架构、工艺选择(连的是什么);每片die的摆放规划、如何连接、IO分布等(可以怎么连);以及“die连接后的性能预分析问题”(怎么连得好)...“做单die设计时我们原本熟悉的4个环节需要全部重构”。
到具体实现的布局布线,呈现的几大难点被赵毅归结为“CIS”(Chiplet, Interposer, Substrate):首先是对于每颗chiplet,核心模块、IO分布,die-to-die物理设计工具、约束等;涉及基于interposer的互联时的电源网络与信号布线,“要全部重做”;以及substrate基板层的RDL与跨层协同设计。
他还特别举例提及,诸如hybrid bonding混合键合技术能够实现显著更高的键和密度,“但没有EDA工具的支持,根本无法达到这样的布线密度”,所以“工艺要与算法深度绑定”。“从2.5D/3D布局布线角度看,所有算法都需要重做;面对不同的场景可能还需要做针对性适配”。
最终,chiplet、silicon interposer(硅中介)、package substrate(封装基板)的“跨层级协同优化”是赵毅在演讲中反复强调的关键。而当涉及垂直堆叠的3D IC设计时,相比2.5D更需要面对“解空间爆发性增长”的挑战...
有关仿真,多物理场协同是不少EDA企业都意识到的挑战;另外相关跨工艺(不同类型的chiplet)、跨层级(CIS);以及设计仿真协同——“如果不做真正的设计仿真协同,一定会面临非常多的回调;甚至可能因为堆叠复杂度变高,面临设计无法收敛的问题”。
针对设计仿真协同的问题,他还举例提到了翘曲(warpage):设计复杂度变高以后,“解决thermal induced可靠性问题一定要做两件事:一是将可靠性前置,在做顶层架构设计规划时,就分析thermal profile、current density、power density...通过前期仿真,就从设计角度做规避——所谓的可靠性就是设计出来的;二是针对生命周期的可靠性问题,加上片上测试与修复、冗余。”
有关验证,“多die的LVS, DRC与单die又不一样。横向与纵向互联时,有其特殊的设计规则”;
有关测试,“测试是刚需”,面临的挑战包括需要新的缺陷机制和失效模型,对应的多die新型DFT电路设计,到新标准的诞生——“IEEE因此做了3D IC DFT的1838标准——这是我们当时和我的导师一起做的,我们从2010年就开始研究了”;以及“需要有自修复机制”等等...以上这些就是STCO的大致流程,“当然DFT需要前置”。
赵毅表示,硅芯对“所有的点工具都做了重构;我们的设计范式也走向了PPPAC,将package作为深度思考的一部分,加入到设计理念中来”,“做完架构,要把DFT,包括冗余、自修复的机制加进来,还要做die-to-die的布局布线、同时做仿真协同,最后做多die LVS......所有这些都要加个multi-die,因为它从工具到算法都与单die差别很大”。

硅芯的设计平台名为3Sheng Integration,“我们的整个工具链平台可以做CIS多层级的协同设计,并关注性能、成本、可测试性的协同优化。”据说客户落地案例已经涵盖了同构堆叠、逻辑+存储、模拟+数字+射频、硅光EIC+PIC,“甚至超大规模堆叠”。
总的来说,硅芯引入的“EDA+”新范式是指,“新一代基于chiplet的EDA工具链+先进封装制造工艺+不同的异构异质集成堆叠芯片场景”协同,“在EDA+新范式下,实现产业链上下游的共同合作。”
满足“小容量高带宽”的边缘AI存储需求
而谈到2.5D/3D堆叠,华邦电子在论坛现场介绍的恰是一款强调2.5D/3D堆叠的存储解决方案,只不过不是HBM。近半年AI数据中心的HBM存储需求飙升,令存储芯片的价格跟着水涨船高,包括边缘和端侧应用的LPDDR4/5。当AI从云端向边缘演进,尤其在推理近拐点之时,“边缘AI需要高效的存储架构、优化的功耗和带宽,这是我们擅长的。”华邦电子资深工程师雷家锋表示。
前年的媒体活动上,华邦就向我们介绍过AI时代的战略和打法——当时提到的CUBE(Customized Ultra Bandwidth Element)存储解决方案就引发了我们极大的兴趣——这是一种以大量并行IO口实现超高带宽、与SoC die藉由TSV(硅过孔)做3D堆叠的存储产品。
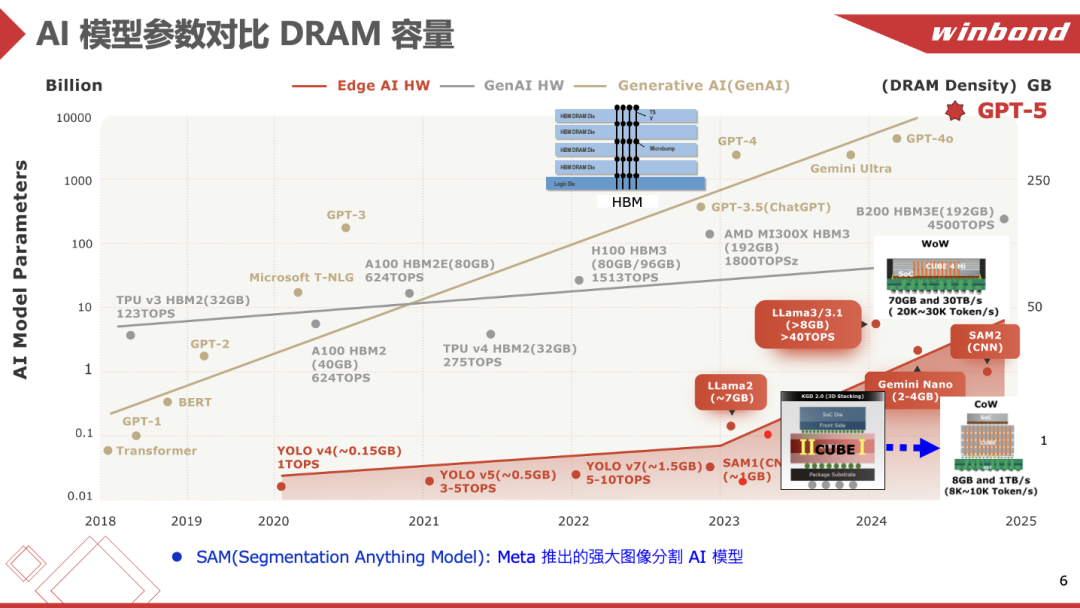
雷家锋在演讲中给出了上面这张图,展示当代主流端侧AI模型与存储产品的对应关系——其中就特别列出了CUBE所在位置:“现在很火的Llama2, Llama3,Qwen的0.8B/2B/4B/9B模型,我们的CUBE产品(8GB容量,1TB/s带宽)就能进行很好的支持。”“如果做到reticle尺寸,则能达成80GB容量、30TB/s带宽,可以用在边缘服务器上。”
对于边缘计算市场,CUBE可以解决内存墙的问题,“特别是在满足小容量高带宽需求这块”。而“小容量高带宽”是关键词,也与边缘AI应用的需求契合。
“我们的产品完全可以达到甚至超过HBM的带宽水平,但容量更小。容量方面,单层0.5GB,4Hi叠4层是4GB;带宽则在128GB/s-1TB/s之间”。由于CUBE主要是面向客户的定制产品,可根据容量和带宽需求做不同层数(“8层很快会出来,达到最高16GB容量、4TB/s带宽”)的定制。
他举了两个将CUBE与NPU搭配的案例,包括为一款NPU芯片搭配>4GB >512GB/s的CUBE存储——“传统端侧的存储方案,可能会用LPDDR4的多颗KGD,整个系统会很拥挤;而CUBE一颗就能解决。”对于上述消费类应用的案例,“达成的带宽>128GB/s,CoW方案的功耗做到了<1.0pJ/bit”,相比带宽更低的LPDDR4x,功耗低了4倍不止;
另一个案例是达到reticle尺寸、超过70GB容量、>30TB/s带宽的CUBE,与NPU堆叠的AI边缘服务器应用,此案例中,CUBE也做到了较低的功耗,“WoW的hybrid bonding可以实现<0.6pJ/bit”。
另外雷家锋还介绍了特别面向TinyML端侧AIoT设备的1Gb CUBE-Lite产品,目标应用如AI ISP、可穿戴设备等。“这款产品容量1Gb, 128 IO”;“相比很多产品采用的LPDDR4X,CUBE-Lite实现了显著更小的尺寸”。“比如对尺寸和功耗要求都很高的AI眼镜,我们的这款产品就很适用。”
总的来说,“小容量高带宽”完美契合了AI边缘侧的需求,“借助华邦的hybrid bonding、TSV等2.5D/3D相关堆叠技术,实现低延时、低功耗、宽IO,都十分适配边缘推理需求。”
边缘AI产品的低功耗测试:避免踩坑
在边缘AI的落地链条中,测试对产品可靠性、功耗表现乃至用户体验的影响也至关重要。是德科技在本届论坛的分享,既包括低功耗AI设备的动态电流分析方法,也展示了其最新一代高性能示波器平台 XR8。
是德科技电源和通用产品市场经理饶骞指出,低功耗边缘AI设备(如智能眼镜、实时血糖监测仪、可穿戴设备等)普遍采用电池供电,其功耗模式呈现典型的“高峰 + 深度休眠”结构:Active 状态与Sleep之间的电流往往相差10^5量级。
这样的变化意味着测试设备必须同时满足:极宽动态范围、ms级响应速度、长时间数据记录能力(数小时到数百小时),饶谦强调,这正是许多工程师在功耗分析中“踩坑”的根源。
他以工程师最常用的几类仪器为例,逐一分析其适用场景与限制:(1)万用表,优点在于测静态小电流准确;但缺点是采样速度慢、不同量程的shunt电阻会引入电压跌落,甚至导致被测设备重启——不适合动态功耗分析;
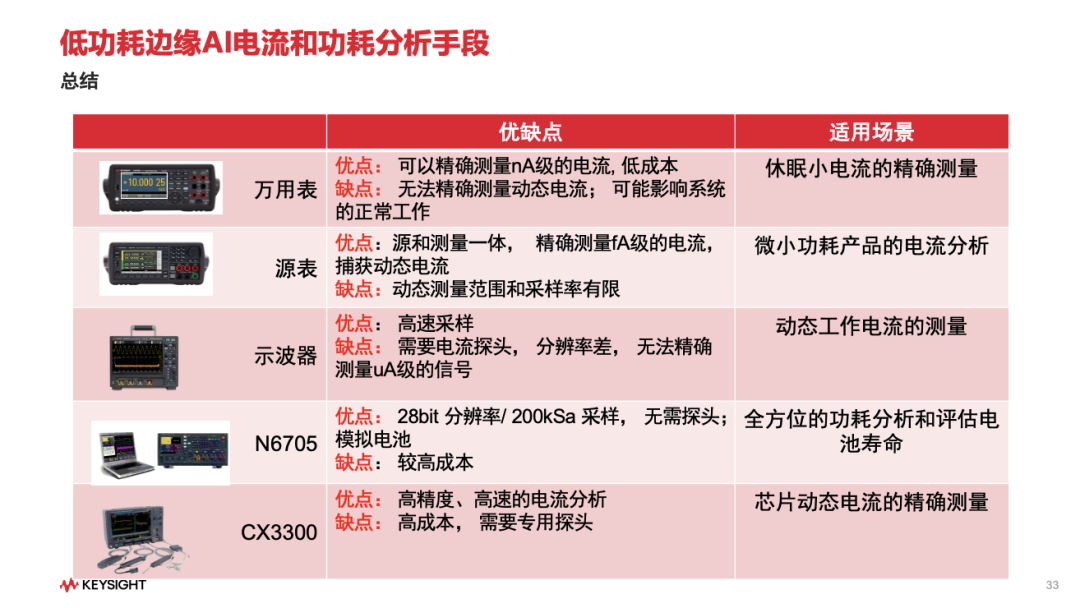
(2)示波器,虽然适合观察启动波形、瞬态电流,但对mA以下电流不够敏感,也无法长时间记录;(3)源表也是个重要方案,它能测nA级静态电流,无需串联分流电阻;只是也不适合长时间、宽动态范围的完整功耗分析。
“没有一种仪器能覆盖所有场景,关键是理解每种方法的边界,避免在功耗测试中踩坑。”饶谦总结道。
针对完整的功耗周期评估(包括电池续航),是德科技提出了更系统化的工具链:直流电源分析仪——如N6705系列:28bit分辨率、200KHz采样率,无缝量程技术可以三个量程并行工作覆盖nA到A级,而且可记录上千小时数据,自动计算最大/最小/平均值。在饶谦展示的案例中,一个设备从深度休眠(数μA)到峰值工作电流(200+ mA)的完整周期被一次性捕获,动态范围跨越10^5,且所有能量指标(mAh、mWh)均被自动计算。
他还介绍了CX3300系列高速电流波形分析仪,适用于高速、小电流场景,电压噪声低至400nV,电流噪声150pA,带宽可达百兆级,适合芯片级、瞬态级的高速电流分析。
值得一提的是,是德科技在论坛上也公开展示最新XR8示波器平台。虽然示波器并非本次演讲的重点,但XR8的出现本身反映了一个趋势:AI推动高速数字接口与测试仪器同步进化。随PCIe 5.0/6.0/7.0、PAM4调制光模块速率不断提升,传统示波器在带宽、底噪、处理速度上已难以满足需求。
所以XR8的核心改进包括:“无可匹敌的”信号完整性:12bit ADC、显著降低底噪、提升ENOB;新一代软件平台,支持多核CPU并行处理,分析能力与性能提升3-10倍;模拟前端与采集板高度集成,相较UXR面积缩小75%,设备深度和重量都降低了30%;更低功耗、更轻重量、更安静的风道设计。
在实际测试中,XR8在 USB4 v2、PAM4、MIPI等深存储场景下的响应速度显著提升,工程师在放大、移动波形时几乎无需等待。是德科技表示,XR8只是新平台的起点,未来将继续面向400G及下一代高速接口扩展。

边缘AI正在经历一次真正意义上的“全栈重构”。NPU厂商在思考如何让端侧芯片承接大模型推理的复杂性;GPU IP供应商在重新定义计算、存储与能效的平衡;EDA企业则在为2.5D/3D堆叠时代重写设计范式;存储厂商以“小容量高带宽”回应边缘推理的带宽瓶颈;而测试厂商则提醒我们,只有可靠的测量体系,才能让这些技术真正落地。
这些技术并非孤立存在,而是共同构成了边缘AI时代的基础设施。它们的演进速度,也远超过去十年移动计算时代的节奏。随着大模型继续向端侧渗透,未来的边缘AI系统将不再只是“轻量化AI”,而是具备实时感知、推理、交互能力的智能终端。而在这一过程中,算力、存储、封装、工具链、测试体系的协同演进,将决定边缘AI真正的落地速度。








评论区
登录后即可参与讨论
立即登录