当英伟达 Blackwell 架构以 NVLink 5 将 GPU-GPU 互联带宽推至1.8Tb/s(14.4Tbps),AI 超算正式迈入 “万亿参数级训练” 的新纪元——单颗GPU的芯片间带宽达到PCIe 5.0的35倍、Hopper NVLink 4的2倍,支撑72颗 GPU 集群每秒处理数 PB 级数据流动。但这一带宽革命并非性能的线性跃升,而是将电子系统设计推向物理极限的临界点:信号完整性、功耗热密度、供电封装、多域协同等传统瓶颈全面爆发,形成“仿真完美、实测拉胯、量产崩盘” 的现实鸿沟。
在此背景下,SEGA™(Systematic Engineering Governance Architecture,系统工程治理架构) 应运而生 —— 它不是一款EDA工具,也不是流程清单,而是专为 1.8Tb/s 等先进异构系统打造的“工程收敛操作系统”,通过标准化流程、三重闭环引擎与数据驱动治理,破解碎片化开发困局。今天带大家一起深度拆解 1.8Tb/s 时代的系统性挑战,剖析 SEGA 的核心架构逻辑,并展望其在光子互联、AI 驱动设计、Chiplet 生态中的未来演进路径。
一、1.8Tb/s 时代:带宽革命背后的系统性炼狱
1.8Tb/s 并非单一技术指标,背后的逻辑是整个硬件系统的全链路重构—— 从芯片内核、先进封装、PCB 板材、连接器到数据中心供电散热,每一层都面临 “从可行到可靠” 的代际级工程难题。其核心矛盾在于:超高速率与物理极限的不可调和性,以及多域割裂与异构集成的碎片化陷阱。
信号完整性:电互连走到物理尽头
1.8Tb/s带宽的基础是18 通道并行、224Gbps/Lane、PAM4 调制的极致信号传输,铜质互连在 100GHz +频段彻底暴露短板。
-
衰减与距离死锁:铜缆趋肤效应与介质损耗指数级上升,1.8Tb/s 信号有效传输距离不足 1 米,迫使 GPU、NVSwitch 必须密集堆叠于同一机架,直接限制集群扩展规模。NVL72 架构将交换机置于机架中央,正是为了缩短铜缆长度、规避信号衰减。
-
串扰与噪声雪崩:18 组高速差分线密集布线,相邻通道耦合串扰(NEXT/FEXT)激增,PAM4 调制的低噪声容限(仅 400mV)让微小干扰直接引发误码。PCB 过孔、连接器、焊盘成为 “噪声放大器”,传统 50Ω 阻抗控制、等长布线已无法满足需求。
-
调制与均衡困境:必须依赖5nm/3nm工艺的超低功耗 DSP、自适应均衡(FFE/DFE)与强纠错码(FEC),但这会带来额外 30%+ 功耗与亚纳秒级延迟,进一步加剧系统时序同步压力。
-
材料建模失效:100GHz 以上频段,传统 PCB 介质(如 Megtron 7)的因果性、被动性模型严重失真,仿真与实测误差超20%,导致设计前期无法预判信号劣化风险。
功耗与热密度:AI 集群的 “头号杀手”
1.8Tb/s 系统的单位带宽功耗是计算功耗的 100 倍以上,彻底颠覆 “算力为王” 的设计逻辑:
-
链路功耗爆炸:单条 1.8Tb/s NVLink 5 链路(含 SerDes、DSP、驱动)功耗达45-60W,72 颗 GPU 集群仅互联链路总功耗超2.5kW,叠加 GPU 本身 700W + 功耗,整机柜功率密度逼近100kW,传统风冷(最大 20kW / 柜)完全失效。
-
热分布极端不均:SerDes、光引擎、HBM 3E 构成局部热点(150W/cm²),冷板液冷的微流道设计需精准匹配热源,否则温差超 **15℃** 将引发信号漂移、封装应力开裂。
-
功耗 - 带宽负反馈:高温导致芯片漏电率上升、信号衰减加剧,迫使 DSP 提升均衡强度,进一步推高功耗,形成 “发热→降性能→更发热” 的恶性循环。
封装与供电:3D 异构集成的 “物理牢笼”
1.8Tb/s 系统依赖 CoWoS-L、SoIC 等先进封装,供电与信号布线在毫米级空间内争夺资源,陷入 “寸土寸金” 的设计绝境:
-
封装布线极限:18 组 NVLink 通道、HBM 3E 的 1024 位数据总线、数万组电源 / 接地引脚(PGTSV)在 2.5D/3D 封装内高密度交织,线宽 / 线距缩至 1μm/1μm,阻抗控制、串扰隔离、对称布线难度呈几何级增长。
-
电源完整性(PI)崩溃:AI 训练的突发流量引发极高 di/dt(1000A/μs),电源网络(PDN)阻抗需控制在50μΩ 以下,否则电压跌落超5%将直接导致链路失步。传统去耦电容无法响应瞬态需求,必须依赖嵌入式 TSV 电容、硅基平面电容等前沿技术。
-
封装应力与可靠性:3D 堆叠的硅片、中介层、基板热膨胀系数(CTE)差异,在 1.8Tb/s 系统的剧烈温变下引发微裂纹、翘曲、焊球疲劳,直接导致高速信号开路或阻抗突变。
系统与生态:从 “芯片孤岛” 到 “集群协同” 的鸿沟
1.8Tb/s 带宽的价值,只有在大规模分布式训练中才能释放,但系统层与生态层的适配困境严重制约效能:
-
延迟与同步死锁:万亿参数模型训练要求亚微秒级全局同步,但 1.8Tb/s 链路的传输延迟、FEC 处理延迟、交换机转发延迟叠加,导致集群同步窗口缩至200ns 以内,任何节点时序偏差都会引发全系统 stall。
-
通信 - 计算失衡:传统 NCCL、MPI 协议针对 100Gb/s 级带宽设计,在 1.8Tb/s 速率下出现拥塞、流量饿死、显存墙等问题 —— 带宽跑满,但算力利用率仅60%,形成 “高带宽、低效率” 的悖论。
-
多供应商碎片化:Chiplet、OSAT、EDA、光模块、材料供应商数据格式不兼容,仿真 - 测试 - 量产数据无法互通,导致改版 5-8 次仍无法收敛,研发周期延长 40%、成本飙升 60%。
终极困境:现实鸿沟(Reality Gap)
以上所有挑战最终汇聚为 “现实鸿沟”—— 仿真阶段信号完整性、功耗、时序全达标,但实验室测试误码率超标、带宽缩水 30%、功耗超预算 25%;量产阶段受工艺偏差、材料离散性影响,性能进一步劣化,良率不足 50%。传统 “先设计、后仿真、再测试、最后救火” 的串行模式,在 1.8Tb/s 时代彻底失效,因为物理极限下,任何微小误差都会被无限放大。

二、SEGA™框架:破解 1.8Tb/s 困局的工程收敛操作系统
面对 1.8Tb/s 时代的系统性炼狱,SEGA™框架提出 “有界可扩展、数据驱动、闭环收敛”的核心理念,将碎片化、经验化的开发,转变为标准化、可量化、全链路可控的工程执行体系。其本质是在物理极限与工程现实之间,搭建一座 “收敛桥梁”,确保设计从仿真到量产的全流程一致性。
SEGA 的核心定位:不是工具,而是 “执行架构”
SEGA™(Systematic Engineering Governance Architecture)是由 Dr. Moh Kolbehdari 提出的行业标准级治理框架(带™商标),专为 3D IC、HBM、1.8Tb/s 高速互联、AI 芯片等先进异构系统设计。它的核心定位是:
-
凌驾于工程栈之上的执行架构:整合 EDA 工具、测试设备、供应链数据、团队流程,而非替代现有工具;
-
解决碎片化陷阱的 “操作系统”:统一多域、多团队、多供应商的开发语言与验收标准,消除信息孤岛;
-
量化收敛的 “证据引擎”:用数据而非经验判断 “设计是否成熟”,强制关闭 “现实鸿沟”。
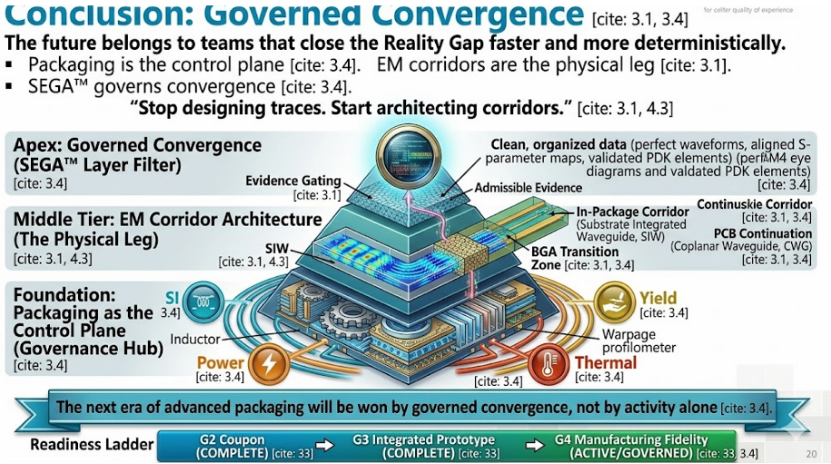
SEGA 核心架构:6 大固定阶段 + 三重收敛闭环
SEGA 框架通过“标准化流程 + 闭环引擎 + 数据治理” 三位一体的设计,彻底重构先进系统开发逻辑。
6大不可省略的执行阶段(固化流程,杜绝混乱)
SEGA 将复杂开发流程固化为 6 个线性但可迭代的阶段,无捷径、无遗漏,确保全链路可控:
1. Playbook(剧本规范):制定 1.8Tb/s 系统的统一设计规则、接口协议、指标阈值、验收标准—— 明确信号完整性损耗预算(≤15dB@112GHz)、PDN 阻抗(≤50μΩ)、热分布温差(≤10℃)等硬指标,所有参与方(设计、封测、供应链)必须遵循。
2. Backbone Data(骨干数据源):建立唯一、可信、全生命周期的数据源,整合仿真数据、实验室测试数据、量产良率数据、供应链参数,消除多版本数据冲突,所有决策基于 “单一事实源”。
3. Ecosystem Onboarding(生态接入):为 Chiplet 供应商、OSAT 厂、EDA 厂商、测试服务商提供标准化接入接口,统一数据格式、验证流程、交付物规范,实现多主体 “即插即用” 式协同。
4. Convergence & Evidence Engine(收敛与证据引擎):SEGA 的核心大脑—— 自动采集全流程数据,量化仿真 - 实测 - 量产的误差,生成 “收敛证据”,判断设计是否达到下一阶段门槛。
5. Decision Control(决策控制):基于收敛证据进行门控决策—— 达标则放行,不达标则强制回滚优化,杜绝 “人情放行”“经验决策”,所有决策可追溯、可量化。
6. Convergence Visibility(收敛可视):全局可视化 dashboard,实时展示各阶段收敛进度、风险点、误差趋势,让管理层、工程师、供应链方同步掌握系统状态。
灵魂:Triple-Loop 三重收敛闭环(关闭现实鸿沟)
SEGA 的核心创新是三重不可分割的收敛闭环,针对性破解 1.8Tb/s 系统的 “现实鸿沟”——仅通过单一闭环无法解决问题,必须三环同步收敛:
-
Multi-Physics Loop(多物理域循环):同步收敛电气(SI/PI)、热、应力、电磁兼容(EMC)四大物理域。1.8Tb/s 系统中,信号完整性受温度影响(热漂移),功耗影响热分布,热应力影响封装阻抗,SEGA 强制四大域并行仿真、联合优化,而非传统串行迭代。例如:当热仿真显示局部热点超 125℃,自动联动信号仿真调整均衡参数,同时联动结构仿真优化微流道设计。
-
Correlation Loop(相关性循环):量化仿真与实验室数据的误差,并强制收敛。传统开发中仿真与实测误差超 20% 却无人追责,SEGA 要求误差必须控制在5% 以内,并跟踪误差 “衰减率”—— 每轮改版误差必须缩小 30%+,否则判定设计不收敛。针对 1.8Tb/s 系统,重点校准 PCB 介质损耗、连接器 S 参数、SerDes 非线性等关键参数的仿真模型。
-
Manufacturing/OSAT Loop(制造 / 封测循环):验证实验室原型与量产产品的一致性,解决 “原型完美、量产拉胯” 问题。SEGA 要求将 OSAT 的工艺偏差(如蚀刻误差、焊球共面度)、材料离散性纳入前期设计,量产良率需≥95% 才算收敛。例如:1.8Tb/s 封装的微凸块工艺偏差需控制在 ±0.5μm 以内,SEGA 会提前将该参数纳入仿真,确保量产性能与原型一致。
有界步数(XX-Step):防止流程膨胀,保障高效收敛
为避免大型项目流程无限扩张、进度失控,SEGA 将所有工程动作分为5 大类(定义、绑定、验证、引擎、治理),并为核心流程设定步数上限(XX-Step)。无论项目规模(从单芯片到 3D 多 Die 集群),核心收敛步骤不超过固定阈值,确保简单项目不繁琐、复杂项目不混乱。例如:1.8Tb/s 系统的信号完整性验证,被固化为 12 步标准流程,每步都有明确的交付物与验收阈值。
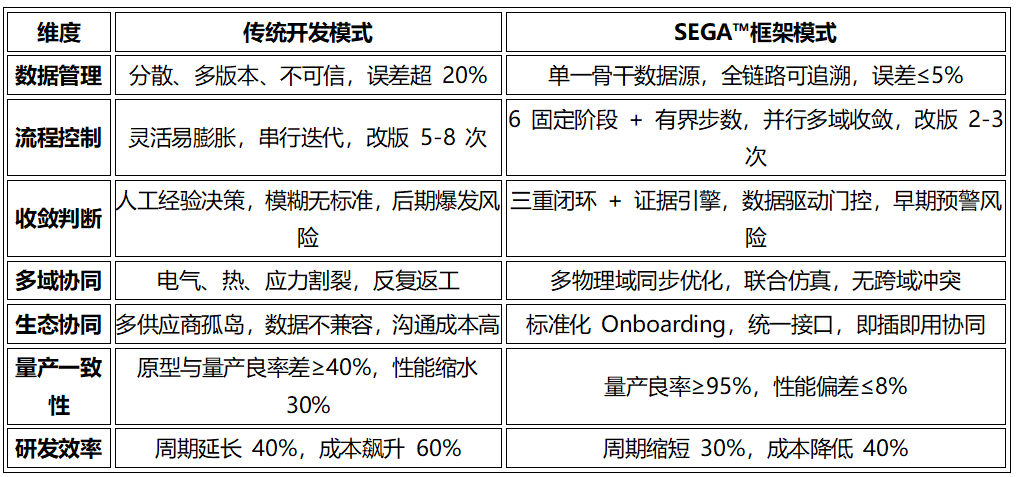
SEGA vs 传统模式:1.8Tb/s 时代的效率革命
对比传统碎片化开发模式,SEGA 框架在 1.8Tb/s 系统开发中展现出颠覆性优势:
三、SEGA 框架的未来发展:适配光子时代与 AI 驱动的演进路径
1.8Tb/s 只是高速互联的起点 ——2027-2030 年,NVLink 6 将推至3.6Tb/s,CPO(共封装光学)、硅光引擎、Chiplet UCie 标准全面普及,系统复杂度将再上台阶。SEGA 框架并非静态标准,而是持续演进的生态体系,未来将沿四大方向升级,深度适配下一代先进系统需求。
深度融合光子互联:从电到光的全链路治理
1.8Tb/s 时代的铜缆极限,注定让CPO、硅光引擎、3.2T 光模块成为 3.6Tb/s + 系统的核心载体。但光互连带来全新挑战:硅光耦合损耗、波长漂移、温控精度、光电协同设计等,SEGA 将扩展多物理域闭环,新增光学域治理:
-
Opto-Physics Loop(光电协同闭环):在原有三大物理域基础上,加入光学域(光功率、耦合损耗、波长稳定性、偏振模色散),实现 “电 - 光 - 热 - 应力” 四域联合收敛。例如:CPO 光引擎的温控精度需≤±0.5℃(避免波长漂移),SEGA 将热仿真与光损耗仿真强绑定,自动优化微流道与温控策略。
-
光模块 / 硅光生态接入:针对 Lumentum、博通等光器件厂商,制定标准化光性能参数、测试流程、可靠性阈值,将光模块的功耗(≤8W/3.2T)、带宽密度(≥1.2Tb/mm²)纳入 Playbook 规范,实现光电系统无缝协同。
-
光电混合链路收敛:量化 “电芯片 - 光引擎 - 光纤 - 光模块” 全链路的信号 - 光功率 - 功耗一致性,解决光电转换带来的额外延迟与损耗,确保 3.6Tb/s 光互连系统的收敛精度与 1.8Tb/s 电系统一致。
Agentic AI 驱动:智能收敛与自主决策
随着 AI 设计工具(如英伟达投资的新思科技 AI EDA)普及,SEGA 将引入 Agentic AI(智能代理),从 “人工驱动的闭环” 升级为 “AI 自主收敛”:
-
AI 收敛预测引擎:基于历史骨干数据,训练 AI 模型预判设计风险与收敛趋势—— 在仿真阶段即可预测实验室测试误差、量产良率,提前优化参数,减少改版次数。例如:AI 发现某款 PCB 介质在 112GHz 下损耗超预算,自动推荐替代材料,避免后期测试失败。
-
自主闭环优化:AI 代理直接对接 EDA 工具、测试设备,自动执行仿真 - 测试 - 迭代流程—— 当误差超标时,AI 自动调整设计参数(如布线宽度、去耦电容位置),重新仿真验证,直至达标,无需人工干预。针对 1.8Tb/s 系统的 SI/PI 优化,AI 可在 24 小时内完成传统工程师 1 个月的迭代工作量。
-
智能决策门控:AI 基于收敛证据自主进行阶段门控决策,并生成可解释的决策报告 —— 明确达标 / 不达标原因、风险点、优化方向,替代传统人工评审,提升决策效率与客观性。
Chiplet 生态标准化:跨厂商的收敛治理
UCie、Chiplet Standard 等标准落地后,多厂商 Chiplet 混搭(如 GPU+NPU+HBM+IO Chiplet)将成主流,但跨供应商的收敛一致性是最大难题。SEGA 将升级为Chiplet 生态治理底座:
-
Chiplet 级 Playbook:制定跨厂商的统一接口规范、性能阈值、可靠性标准—— 如 Chiplet 间 1.8Tb/s 互联的插入损耗(≤12dB)、电源噪声(≤20mV)、热分布约束等,所有 Chiplet 供应商必须通过 SEGA 认证。
-
分布式收敛协同:支持多厂商分布式开发、集中式收敛验证——A 厂设计 GPU Chiplet、B 厂设计 HBM Chiplet,各自数据接入 SEGA 骨干数据源,框架自动进行跨 Chiplet 的多域协同仿真与收敛验证,确保整体系统性能达标。
-
供应链韧性治理:纳入多供应商备选方案、材料替代参数、工艺偏差冗余,当某一供应商出现产能问题时,SEGA 自动切换备选方案,并快速验证收敛性,保障 1.8Tb/s/3.6Tb/s 系统的量产稳定性。
全生命周期扩展:从研发到运维的端到端治理
当前 SEGA 聚焦研发 - 封测 - 量产阶段,未来将延伸至数据中心运维、系统退役全生命周期,形成 “从设计到报废” 的闭环治理:
-
数据中心运维收敛:实时采集 1.8Tb/s 集群的运行带宽、功耗、温度、误码率数据,与设计阶段的骨干数据对比,动态优化散热策略、链路均衡参数,解决系统老化、温变导致的性能劣化问题,延长使用寿命。
-
可靠性与寿命预测:基于全生命周期数据,训练 AI 模型预测链路失效、封装疲劳、光器件老化风险,提前预警维护,避免集群突然宕机 —— 针对 1.8Tb/s 系统的高可靠性需求(99.999% 可用性),实现 “预测性维护”。
-
绿色工程治理:纳入功耗效率、碳排放、材料回收指标,在设计阶段即优化 1.8Tb/s 系统的每瓦性能(TOPS/W),减少液冷能耗、使用环保材料,实现高性能与可持续性的双重收敛。
生态普及与标准演进:从前沿框架到行业基石
SEGA 框架当前主要应用于英伟达、AMD 等 AI 芯片大厂的 1.8Tb/s 系统开发,未来将向全行业普及,成为先进系统设计的行业标准:
-
开源轻量化版本:推出面向中小企业、初创公司的SEGA Lite版本,简化流程、降低门槛,支持中小规模 Chiplet、高速互联项目的收敛治理。
-
EDA 工具深度集成:与新思科技、楷登电子、西门子等 EDA 厂商深度合作,将 SEGA 的三重闭环、骨干数据管理原生集成到 EDA 工具链,实现 “设计即收敛” 的无缝体验。
-
行业标准认证:推动 SEGA 成为IEEE、SEMI等国际组织的先进系统设计标准,建立 SEGA 认证体系 —— 通过认证的设计团队、供应商、产品,代表具备 1.8Tb/s + 系统的可靠开发能力。
结语:收敛,是 1.8Tb/s 时代的终极答案
1.8Tb/s 时代的本质,是人类电子技术触及物理极限的一次集体试炼—— 带宽每翻一番,挑战便呈指数级增长,传统碎片化、经验化的开发模式已走到尽头。而 SEGA™框架的价值,正在于为这场试炼提供了系统性的解决方案:它用标准化流程终结混乱,用三重闭环关闭现实鸿沟,用数据驱动替代经验决策,让先进系统从 “不可控的冒险” 变为 “可控的工程”。
展望未来,当 3.6Tb/s、CPO 全光互联、万颗 Chiplet 集群成为现实,SEGA 框架将持续进化,始终作为先进异构系统的 “收敛底座”—— 它不仅是一套技术框架,更是一种工程哲学的革新:在物理极限面前,真正的突破不是追求更高的带宽、更复杂的架构,而是实现更快、更稳、更一致的收敛。
对整个半导体与 AI 行业而言,穿越 1.8Tb/s 炼狱的钥匙,从来不是某一项单点技术的突破,而是全链路的工程收敛能力—— 而 SEGA,正是握住这把钥匙的关键。












评论区
登录后即可参与讨论
立即登录