电子发烧友网报道(文/李弯弯)泰凌微近日表示,公司与谷歌在智能家居、音频等多个领域开展具体项目合作。其与谷歌已从单一的遥控器芯片供应,发展为涵盖音频、智能家居、端侧AI等多领域的深度合作关系。
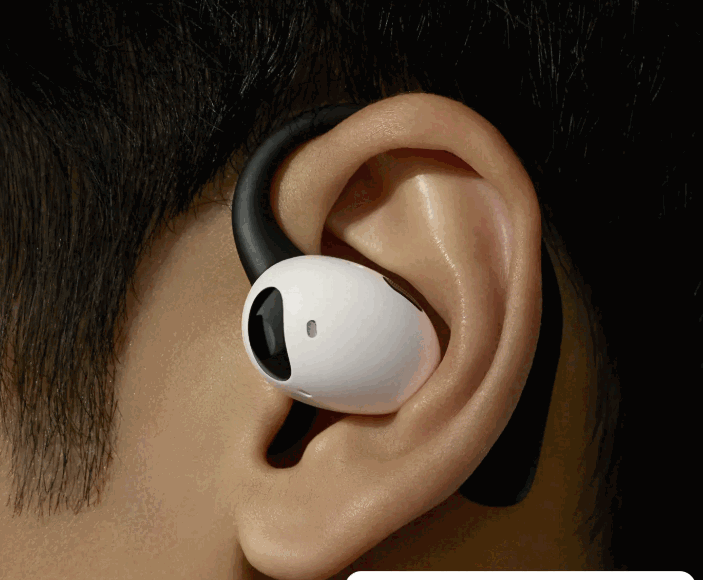
公司发布的基于TL721X系列芯片的TL-EdgeAI平台,支持谷歌LiteRT、TVM等开源模型,是目前世界上功耗最低的智能物联网连接协议平台。其芯片已在谷歌(Google)的Pixel Bud Pro 2智能耳机方案中被采用。公司将继续深化与谷歌的合作关系。
围绕三大核心,布局端侧AI领域
在端侧AI领域,泰凌微的布局围绕核心芯片研发、配套开发平台搭建、多场景市场落地三大核心展开,形成了一套完整且具有前瞻性的发展体系。
泰凌微推出的基于TL721X的TL-EdgeAI平台,是其在端侧AI领域的重要技术成果。TL721x SoC增加了边缘AI运算能力,使得芯片具备了本地智能处理的能力,无需依赖云端计算,大大提高了数据处理的效率和安全性。TL-EdgeAI平台则支持主流本地端AI模型,如谷歌LiteRT、TVM等开源模型,为开发者提供了丰富的开发资源和便捷的开发环境。这一平台不仅是目前世界上功耗最低的智能物联网连接协议平台,更是为海量AI端侧应用的发展铺就了崭新道路。
为了更好地推动端侧AI技术的发展,泰凌微还推出了机器学习与人工智能发展平台TLEdgeAI-DK。该平台将支持主流本地端AI模型,为开发者提供了一站式的开发解决方案,降低了端侧AI应用的开发门槛,加速了端侧AI技术的普及和应用。
在应用场景方面,泰凌微的端侧AI芯片目前主要应用于音频领域,如无线麦克风等。随着产品的迭代与场景的落地,未来将逐步拓展至录音设备、智能家居、电动工具、汽车电子、资产跟踪等更多场景。这种多场景的布局,不仅为泰凌微的端侧AI芯片提供了广阔的市场空间,也为其在不同领域的技术积累和产品创新提供了更多机会。
TL721X系列芯片是泰凌微的明星产品,专为蓝牙低功耗(LE)和802.15.4设计。其内置的2.4GHz收发器支持蓝牙低功耗、802.15.4以及2.4GHz专有操作,支持蓝牙LE、Zigbee、Thread、Matter、2.4GHz专有标准等多种标准和工业联盟规范。
该系列芯片将高品质无线物联网设备所需的特性和功能集成到单个系统级芯片中,具有高集成度、超低功耗的特点。它集成了强大的32位RISC-V MCU、512或256 KB SRAM(包括高达256 KB的保留SRAM)、2 MB(2048 KB)或1 MB(1024 KB)嵌入式闪存(具体取决于详细型号)、12位ADC、PWM、灵活的IO接口以及其他物联网应用所需的周边模块。这种高集成度使得外部组件需求极少,能够满足客户对超低成本的要求。
未来规划,IoT、无线音频、边缘AI多领域布局
在无线物联网系统级芯片市场竞争激烈的当下,泰凌微通过技术创新与结构优化保持产品的核心竞争力与毛利率水平。其核心优势主要体现在三方面:一是芯片尺寸优势,核心芯片尺寸小于竞争对手,能有效降低成本;二是核心IP自主化,公司拥有大量自主核心IP资源,降低了IP相关费用支出;三是高毛利产品占比提升,AI产品和音频芯片的快速发展为公司毛利率高位运行提供了有力支撑。
此外,公司正自研WiFi芯片,未来将重点应用于智能家居场景,进一步完善产品矩阵,增强系统级解决方案能力。
对于未来发展,泰凌微有着清晰的战略规划。公司将围绕物联网芯片领域,立足这个规模巨大的市场,把握物联网设备需求爆发的产业机遇,在IoT、无线音频、边缘AI等多个领域深度布局。
在AI领域,公司后续的重点将聚焦端侧AI芯片的算力提升与场景适配能力。随着产品迭代与场景落地,泰凌微在端侧AI领域已形成的先发优势将进一步凸显,未来2 - 3年有望维持高增速,持续贡献营收增量。
音频芯片方面,泰凌微将继续加大投入,做好新品的开发与迭代。同时,公司还将自研WiFi芯片,主要应用于智能家居场景,进一步丰富其产品线,提升在智能家居领域的市场竞争力。这三大方向将成为公司未来的核心增长点,为公司的发展注入强大动力。
泰凌微发布TL721X:支持谷歌LiteRT、TVM开源模型的端侧AI平台
相关标签:
暂无标签
相关推荐
人工智能 5亿视频炼出全球最大 GUI 开源数据集、推理 Token 省71%小模型反超大模型——小米 AI 团队多篇论文入选 ICML 2026
从5亿条互联网视频中炼出全球最大的开源 GUI 操作数据集,让7B 模型在 ScreenSpot-Pro 上准确率提升38%;3B 参数的小模型做时序推理,干掉专用大模型还省了71%的 Token。这不是 PPT 愿景,而是小米 AI 团队研究成果的真实体现。 近日,ICML 2026(International Conference on Machine Learning)公布了论文录用结果。

人工智能 地平线开源HoloMotion-1:4亿参数机器人小脑大模型,实现端侧300FPS
地平线正式发布并开源HoloMotion-1,这是地平线机器人实验室面向人形机器人全身控制打造的4亿参数级机器人小脑大模型。相比以往常见的百万级、千万级机器人控制模型,HoloMotion-1将机器人“小脑”的模型规模提升到新的量级,并在端侧实现约300FPS实时推理,让大模型能力真正进入机器人运动控制闭环。通过本次开源,地平线希望降低人形机器人全身控制的研发门槛,帮助开发者更高效地构建、复现和部

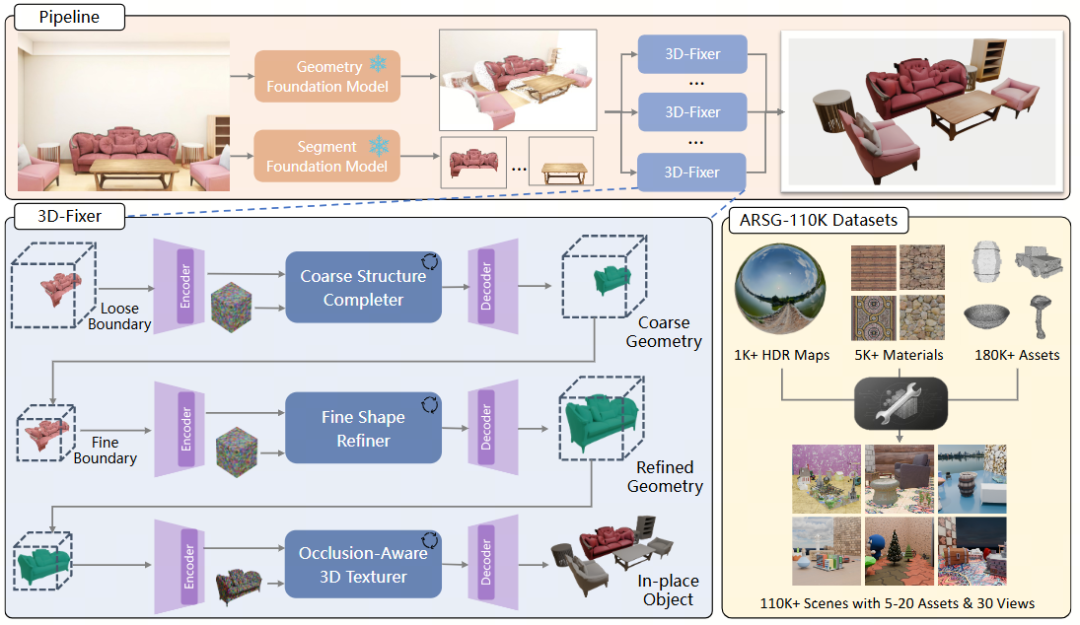
人工智能 开发者说|3D-Fixer:单图3D场景生成的原位补全新范式
• 项目主页: https://zx-yin.github.io/3dfixer • 文章链接: https://arxiv.org/pdf/2604.04406 • GitHub代码**:** https://github.com/HorizonRobotics/3D-Fixer 现有挑战 基于单张图像生成3D场景,是构建物理世界数字孪生环境的关键技术问题。现有方法在泛化能力与生成效率之间存在显
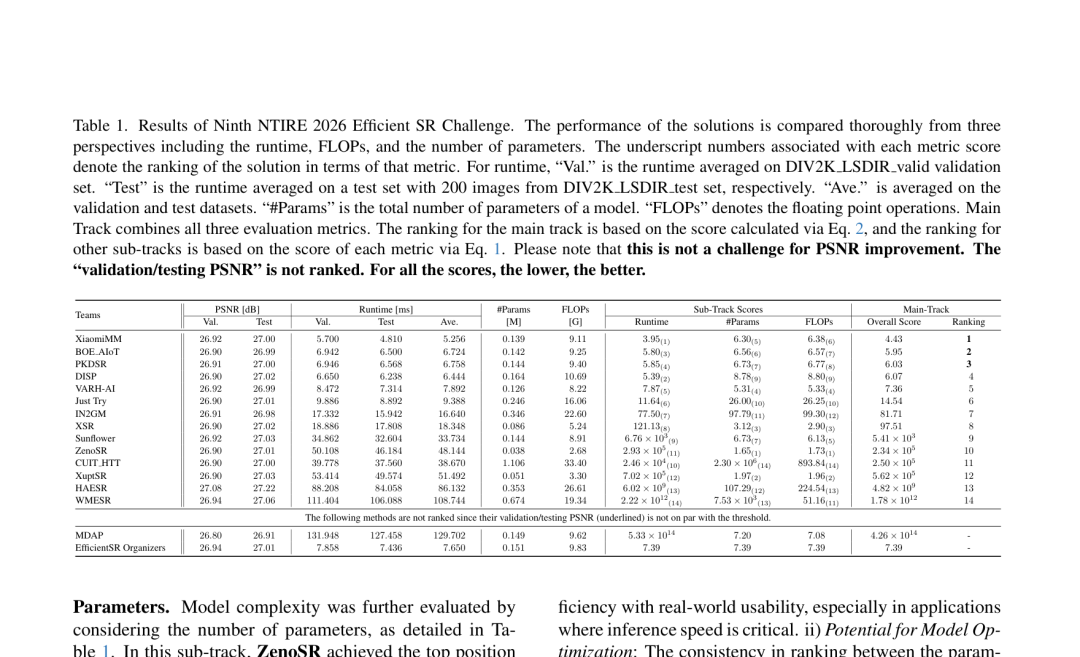
人工智能 CVPR 2026 NTIRE:小米影像算法的技术突破
近日,小米在 CVPR 2026 NTIRE 赛事中荣获三项奖项。其中,小米玄戒多媒体算法团队斩获高效超分辨率赛道冠军,小米大模型应用团队夺得人像修复赛道冠军与反光消除赛道亚军。 NTIRE(New Trends in Image Restoration and Enhancement)由 CVPR 组委会承办,是全球规模最大、水平最高的图像恢复与增强领域学术研讨会。小米在本次赛事中展现了从硬件优
人工智能 AI 公司最怕的不是训练贵,而是每次回答都在烧钱
AI产品越受欢迎,公司越焦虑——推理成本像屋顶漏水,持续消耗算力。vLLM、TensorRT-LLM、llama.cpp三个开源项目分别从云端调度、硬件优化和本地部署入手,试图把“每token成本”降下来,让AI从烧钱走向赚钱。 你有没有发现一个很奇怪的现象。 AI产品越受欢迎,公司反而越焦虑。 传统软件公司最喜欢的一种模式叫规模效应。 一个SaaS产品开发出来之后,新增用户的边际成本很低。用户越
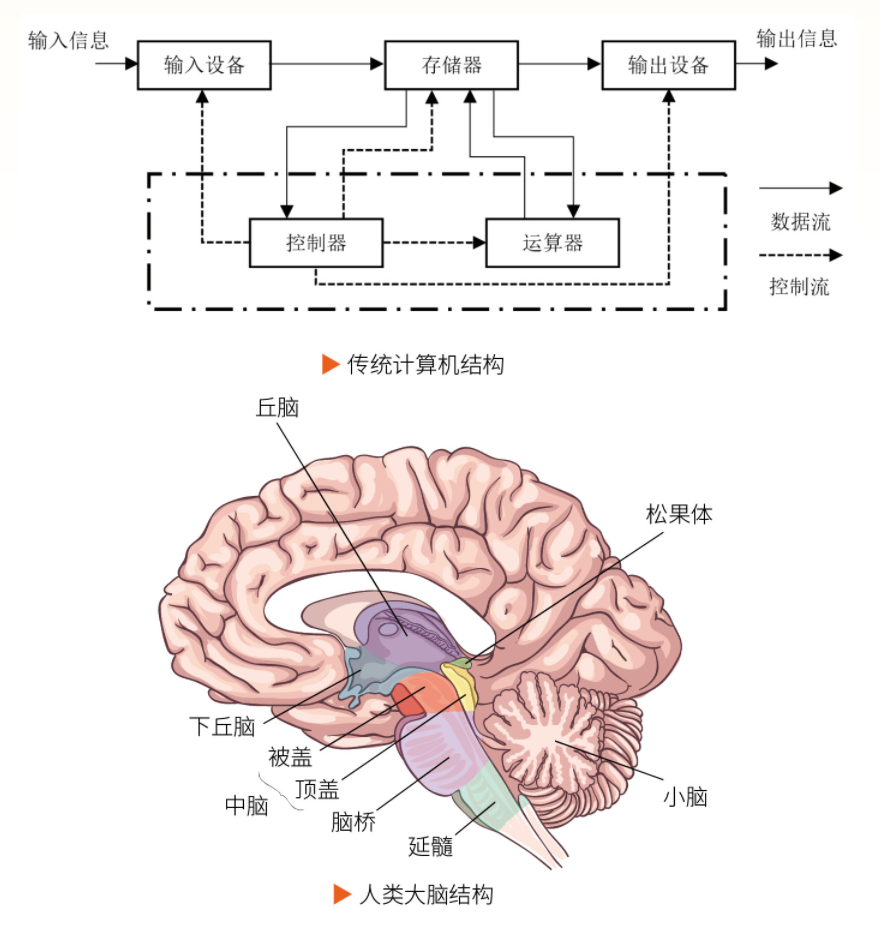
人工智能 “天机”类脑芯片,到底在“类”什么?
大脑天生擅长多任务并行,启发出类脑计算这一颠覆性方向。从“天机”芯片到生物计算机CL1,类脑技术正从科幻走向现实。想成为类脑智能科学家,需打好数学与生物学基础,培养跨学科思维与动手能力。 人人都惊叹大脑有多神奇! 你骑车赶路时,大脑同时调控身体平衡、识别路况,还能和同伴闲聊。人脑为何擅长多任务并行?想要成为类脑人工智能科学家,又该做好哪些准备? 人脑VS传统计算机 从图中可以看出,我们的大脑和传
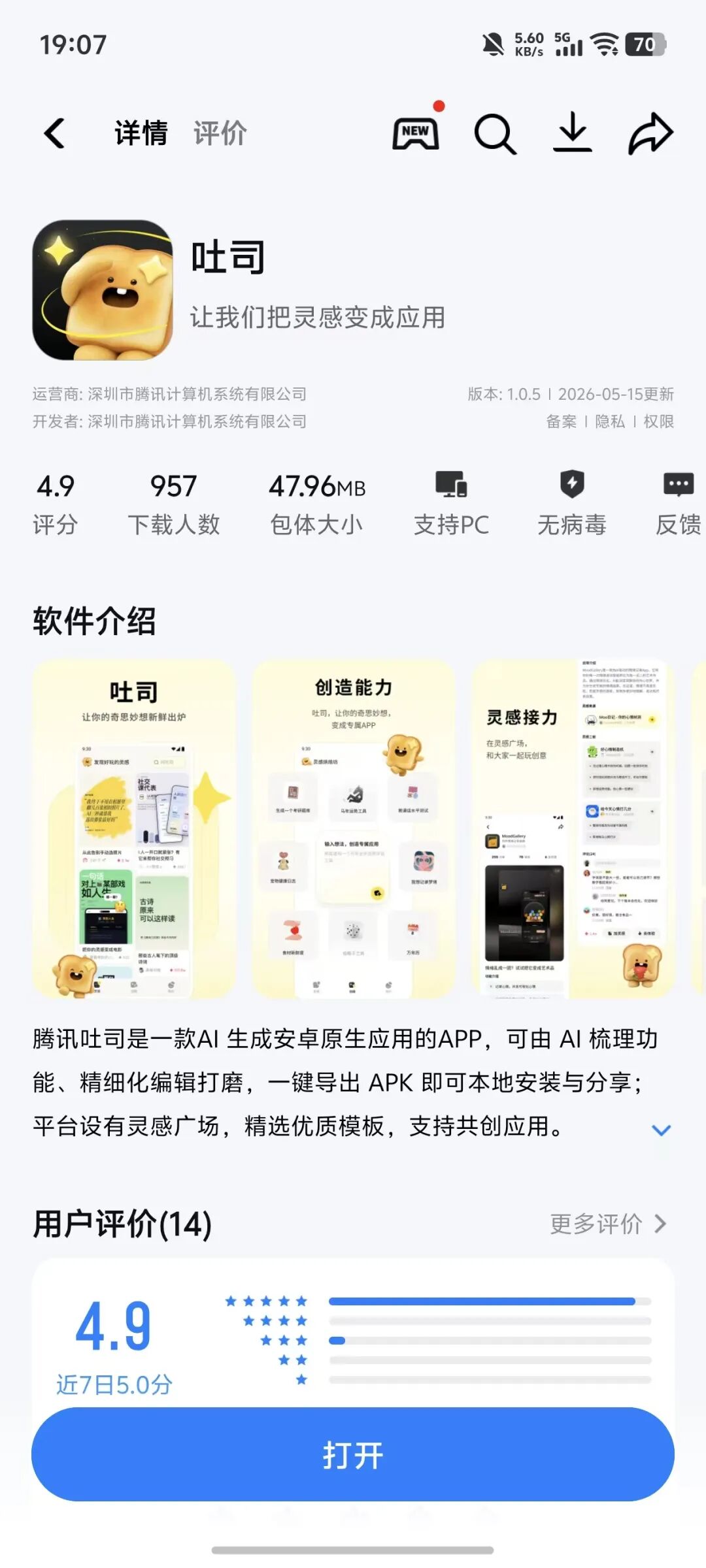
人工智能 腾讯这个App,太逆天了
「人人都能做 App」时代真来了? 继蚂蚁灵光推出“闪应用”后,腾讯 Vibe Coding 产品「吐司」在自家应用宝商城上线,定位「应用生成及灵感共创平台」,简单来说,就是用户说需求,AI 拆解功能需求,最终输出成品应用。 (图源:应用宝) 在腾讯之前,蚂蚁灵光、百度秒哒这类 Vibe Coding 应用早已经在市场上流行。不过,它们生成的应用通常仅支持在内部平台分享,或者以在线的方式分享给其
人工智能 开芯课堂|机器人挥出那一拳之后:智能机器人的安全,到底该怎么做?
机器人要走进真实世界,只有聪明还不够,它还必须可靠、可控、可验证、可托付。聪明,是机器人的上限;安全,是机器人的底线。 一、那一拳的警示:从隐忧到现实 2025年GeekCon安全极客大赛上,两名白帽黑客远程劫持人形机器人,仅用不到3分钟就让两台机器人“沦陷”。随后,被劫持的机器人径直走向舞台中央的假人,抬起机械臂,狠狠挥了一拳,将假人击倒在地。那看似普通的一拳,却击碎了整个行业对安全的幻想。当机
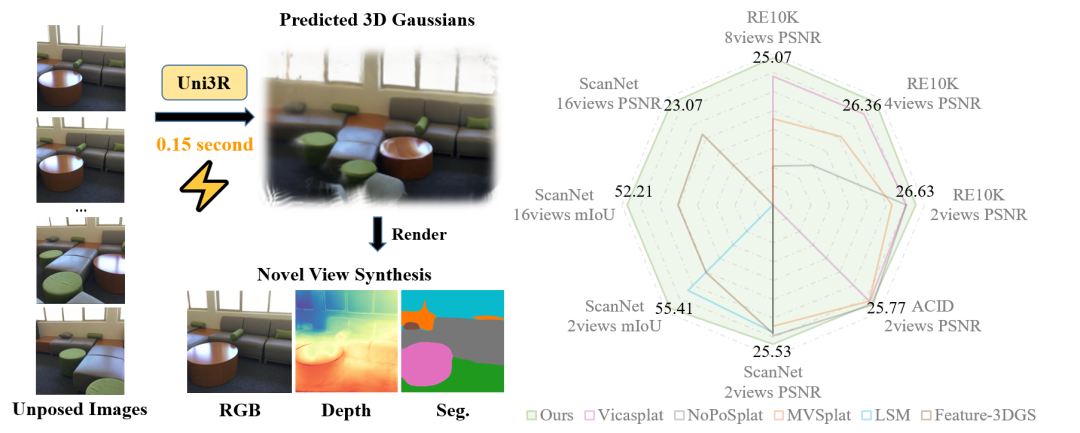
人工智能 开发者说|Uni3R:探索统一3D表征,0.16秒实现3D重建、渲染与理解
• 项目主页: https://horizonrobotics.github.io/robot\_lab/uni3R • 文章链接: https://arxiv.org/pdf/2508.03643 • GitHub代码**:** https://github.com/HorizonRobotics/Uni3R 概述 在现实场景中,通常只能获取来自多个视角的RGB图像,而缺乏相机位姿、深度或点云等
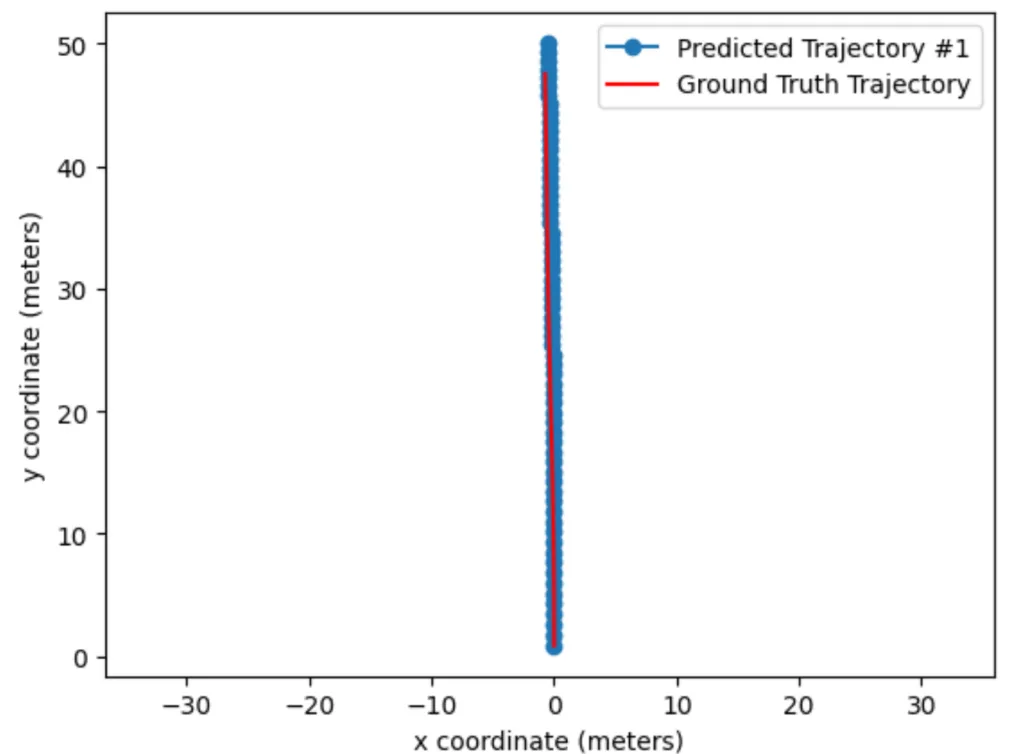
人工智能 NVIDIA Alpamayo:基于VLA推理模型的辅助驾驶解决方案
辅助驾驶研究领域正经历一场快速变革。视觉-语言-动作推理模型(Reasoning VLA) 的出现正重塑该领域,这些模型为辅助驾驶决策赋予了类人的思维能力。这类模型可视为在语义空间中运行的隐式世界
218
2026-01-14
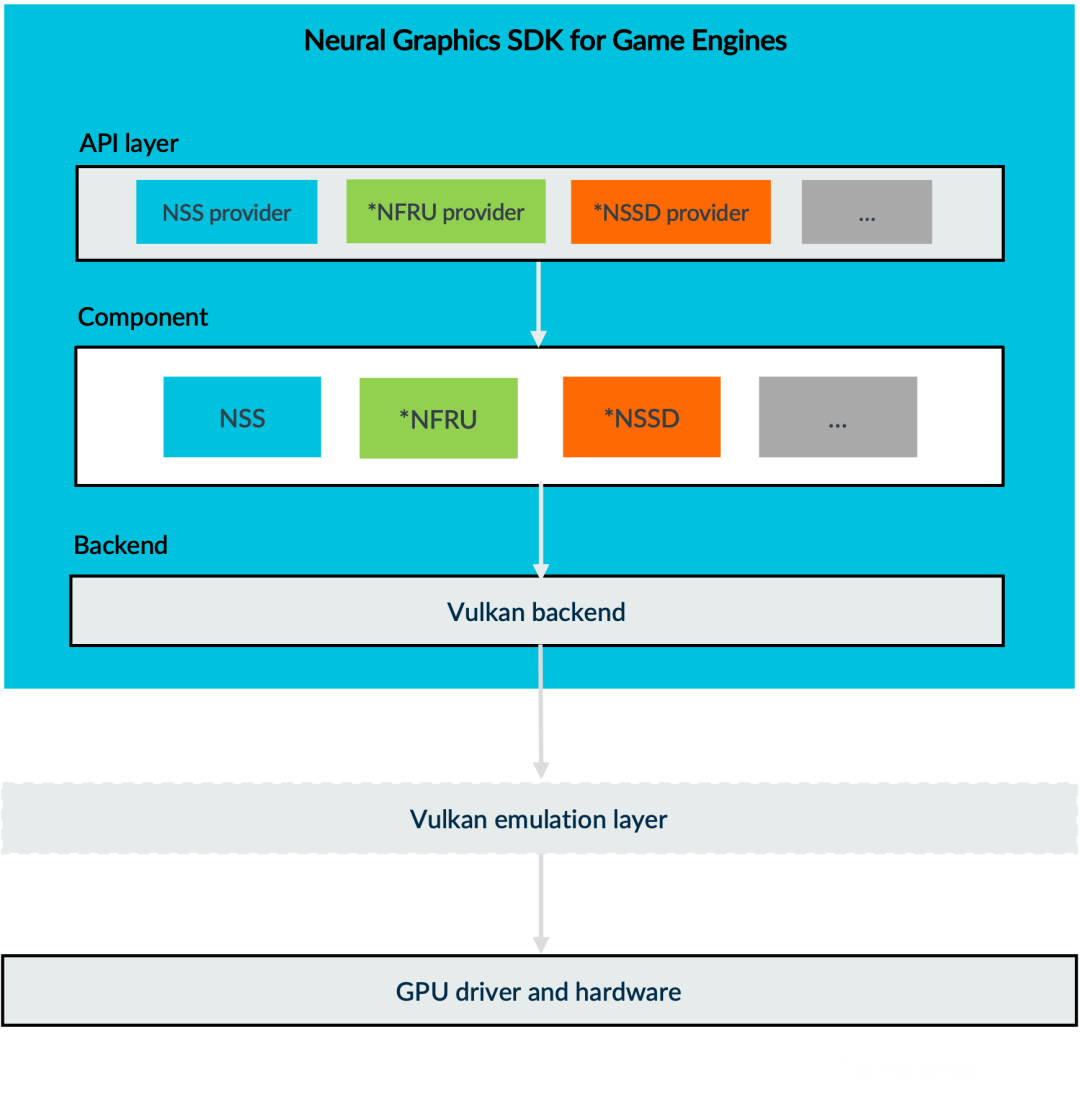
人工智能 Arm推出面向游戏引擎的神经图形SDK及UE5.4的NSS插件
作者:安谋科技高级软件技术经理 杨喜乐 2025 年 8 月,Arm 在 SIGGRAPH 大会上发布了突破性的 Arm 神经技术。这是业内首次将专用神经加速器集成到 Arm GPU 中,搭载
212
2025-11-26
人工智能 高通骁龙8Gen5 AI影像提升40%:超域融合视频技术详解
(电子发烧友网报道 文/章鹰)10月11日,在中国移动全球合作伙伴大会上,高通展示最先进的骁龙8Gen5至尊版芯片、AI眼镜方案、XR设备的芯片方案、5G-A基带芯片,还有在手机领域,高通与虹软公司在
179
2025-10-15

人工智能 海思物连HS-Ultra 7L2D:99TOPS高算力AI边缘计算工控机发布
海思物连推出HS-Ultra 7L2D系列边缘计算工控机,搭载Intel Arrow Lake处理器,提供高达99TOPS的AI算力,适用于工业、医疗等多种场景。
177
2026-03-03

人工智能 MIPS S8200 RISC-V NPU:赋能自主边缘物理AI的最新技术解析
· MIPS S8200 NPU 现已向开发自主边缘运输、机器人及嵌入式平台的主要客户出样· MIPS 赋能通用的端侧 AI 能力,支持现代模型以及具备业界领先的效率2026****年1 月 14 日
176
2026-01-14

人工智能 天数智算AI存储解决方案:UbiPower 18000性能提升50%
在AI大模型训练、超算中心算力升级、生物医药科研等领域,你是否正面临这样的困境:数据量呈指数级增长,存储系统却频频“掉链子”—— 带宽不足拖慢训练进度,IOPS瓶颈导致计算卡顿,扩容复杂让业务扩展举步
167
2025-12-12

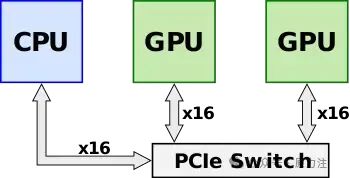
人工智能 AI Infra 基础知识 - NVLink 入门
NVLink是一种专有系统互连硬件,可促进多个 Nvidia GPU 和支持CPU之间的一致数据和控制传输。 概述 NVLink 于 2014 年初发布,旨在作为 PCI Express 的替代解决方案,具有更高的带宽和附加功能(例如共享内存),专门设计用于与 Nvidia 自己的多 GPU 系统的 GPU ISA 兼容。在推出 NVLink 和 Pascal(例如Kepler)之
人工智能 Tensilica Vision 230 DSP助力AX8850N:提升人形机器人与边缘应用性能
近日,楷登电子 Cadence 与边缘 SoC 领军企业爱芯元智共同宣布,爱芯元智在其最新的 AX8850N 平台上集成了 CadenceTensilicaVision 230 DSP,以共同推动
154
2025-12-11

人工智能 光帆科技发布AI摄像头耳机:集成摄像头与实时语音交互
光帆科技发布了首款AI摄像头耳机,集成了高分辨率微型摄像头、双麦克风阵列、本地AI芯片及低功耗蓝牙音频模块,支持第一视角记录、实时语音交互和场景理解等功能。
149
2026-03-07
人工智能 华为AI数据平台支持DeepSeek-V4,定义大模型推理效能新高度
今日,DeepSeek-V4正式开源发布,将模型上下文窗口提升至1M,使模型在长序列推理与复杂任务链处理中的表现更加高效与稳定。华为AI数据平台深度适配DeepSeek-V4,将进一步推动大模型从实验阶段走向生产级应用。 DeepSeek-V4发布 带来KV Cache存储的全新挑战 DeepSeek-V4新版本支持100万Tokens的上下文能力。为提升上下文理解能力同时控制显存占用,DeepS

人工智能 闪迪SN861 NVMe SSD及UFS4.1:2025年AIoT存储解决方案详解
(电子发烧友网报道 文/章鹰)12月19日,OFweek 2025(第十届)物联网产业大会在深圳成功举行。本届大会以“万物智联,赋能数字中国”为主题,邀请各领域专家和行业领先企业代表,共同探讨如何推动
140
2025-12-22

评论区
登录后即可参与讨论
立即登录