GPU 相关常见术语
本文介绍了GPU 相关常见术语。 CPU像总经理,GPU像几万个熟练工人;CUDA 像管理这些工人的操作手册,HBM 像高速仓库,NVLink 像工厂之间的专用高铁。AI 模型越大、Token 调用越多,对 GPU、显存、互联、电力和散热的要求就越高。 你可以把 GPU 理解成:一座有成千上万个“小工人”的计算工厂,特别擅长同时处理大量重复计算,所以非常适合 AI、图形渲染、科学计算和大模型训练。
纳米网人工智能频道 — 提供人工智能领域最新资讯、技术文章和行业动态。
本文介绍了GPU 相关常见术语。 CPU像总经理,GPU像几万个熟练工人;CUDA 像管理这些工人的操作手册,HBM 像高速仓库,NVLink 像工厂之间的专用高铁。AI 模型越大、Token 调用越多,对 GPU、显存、互联、电力和散热的要求就越高。 你可以把 GPU 理解成:一座有成千上万个“小工人”的计算工厂,特别擅长同时处理大量重复计算,所以非常适合 AI、图形渲染、科学计算和大模型训练。
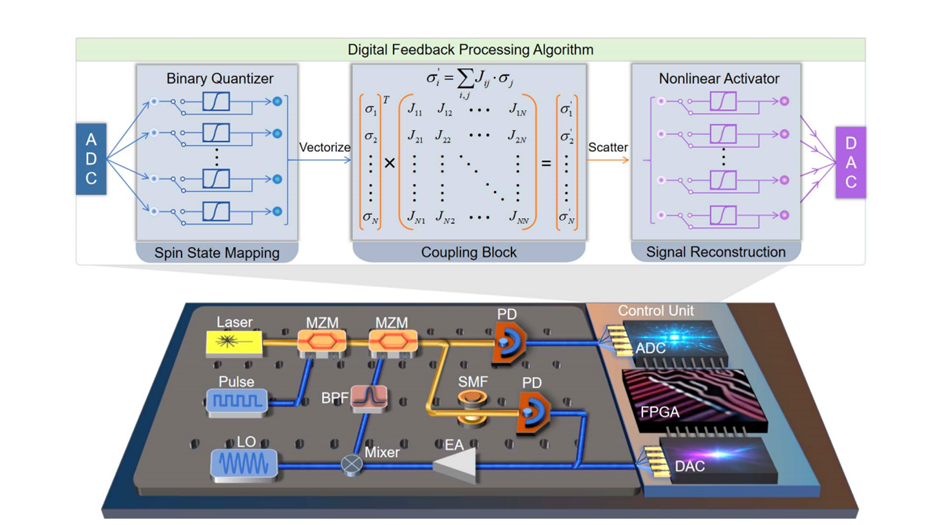
组合优化问题广泛存在于金融、物流、机器学习等领域。传统“冯·诺伊曼”架构在处理规模日益庞大的问题时面临显著瓶颈。光电伊辛机利用物理系统的动力学演化进行本征并行求解,是实现大规模组合优化硬件加速的重要技术路线。然而,其底层物理载体的连续模拟特性与伊辛模型离散二元约束之间存在本质差异,使系统演化过程易受硬件振幅不均匀、噪声累积和性能漂移等因素影响,导致求解准确度下降、可扩展性受限。 近日,中国科学院半
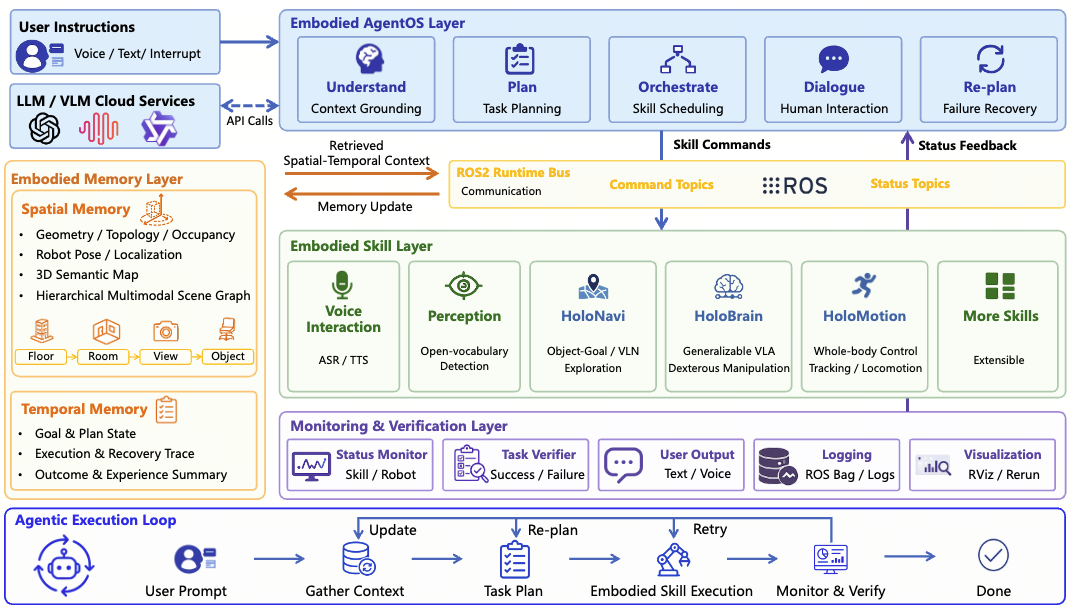
更多机器人演示、技术细节和代码更新可见项目主页与技术报告。 • GitHub**代码:** https://github.com/HorizonRobotics/HoloAgent • 项目主页: https://horizonrobotics.github.io/robot\_lab/holoagent • 论文链接: https://arxiv.org/abs/2606.23565 概述 让A

⬇️ 本文内容源自对Hod Lipson的采访 智能机器正在各种医疗场景中协助专业人员开展工作,越来越多的机器人出现在了微创手术、医院后勤、疾病诊断乃至康复治疗等领域中,持续改变着医疗保健行业。随着机器人设计与功能的不断发展,新型机器人正成为医疗护理的助手,让不堪重负的护理人员得以减轻工作压力。 为了了解护理机器人未来的发展方向,我们采访了毕生致力于探索“机器如何具备人性”的专家Hod Lips
嵌入式系统机器学习终极指南 概述 什么是嵌入式系统的机器学习? 机器学习是人工智能的一个分支,它使计算机能够通过不同技术,从数据中以迭代方式进行学习。我们的目标是让系统从数据中学习并进行预测。这与传统方法有明显区别:传统方式依赖程序员编写明确的指令,而不是从数据中学习模式。嵌入式系统中的机器学习则专门面向嵌入式设备,使其能够采集数据、学习并执行预测。这类系统通常与传统计算机相比,内存更小、RAM更

本文介绍了为什么AI加速不能只靠堆计算单元。 很多人一说起AI加速,第一反应就是堆算力、堆更多浮点计算单元。 错了, 现在的瓶颈根本不是计算本身,是数据搬运、通信和不规则算子,峰值算力再高也没用。 举个最直观的例子,大语言模型推理的时候,每个新生成的token都要读写一遍已经存起来的KV缓存,这玩意儿根本不怎么缺计算,缺的是内存带宽——你带宽不够,就算计算单元堆得再多,也得等着数据慢悠悠从内存运

自动驾驶、救灾无人机等高风险实时 AI 任务算力需求巨大,传统计算机受 “存储墙” 制约,算力与能耗难以平衡。文章剖析传统硬件瓶颈,借鉴人脑神经元特性,介绍存算一体、神经形态芯片等仿生硬件方案,为高效 AI 计算指明方向。 人工智能曾经在科幻电影中,负责给宇宙飞船导航,操纵火箭着陆。如今,它早就不是什么新鲜事,而是润物细无声地渗透到我们的日常生活中。你听歌、看视频,它给你推荐;你出国旅行,它帮你
机器人要走进真实世界,只有聪明还不够,它还必须可靠、可控、可验证、可托付。聪明,是机器人的上限;安全,是机器人的底线。 一、那一拳的警示:从隐忧到现实 2025年GeekCon安全极客大赛上,两名白帽黑客远程劫持人形机器人,仅用不到3分钟就让两台机器人“沦陷”。随后,被劫持的机器人径直走向舞台中央的假人,抬起机械臂,狠狠挥了一拳,将假人击倒在地。那看似普通的一拳,却击碎了整个行业对安全的幻想。当机
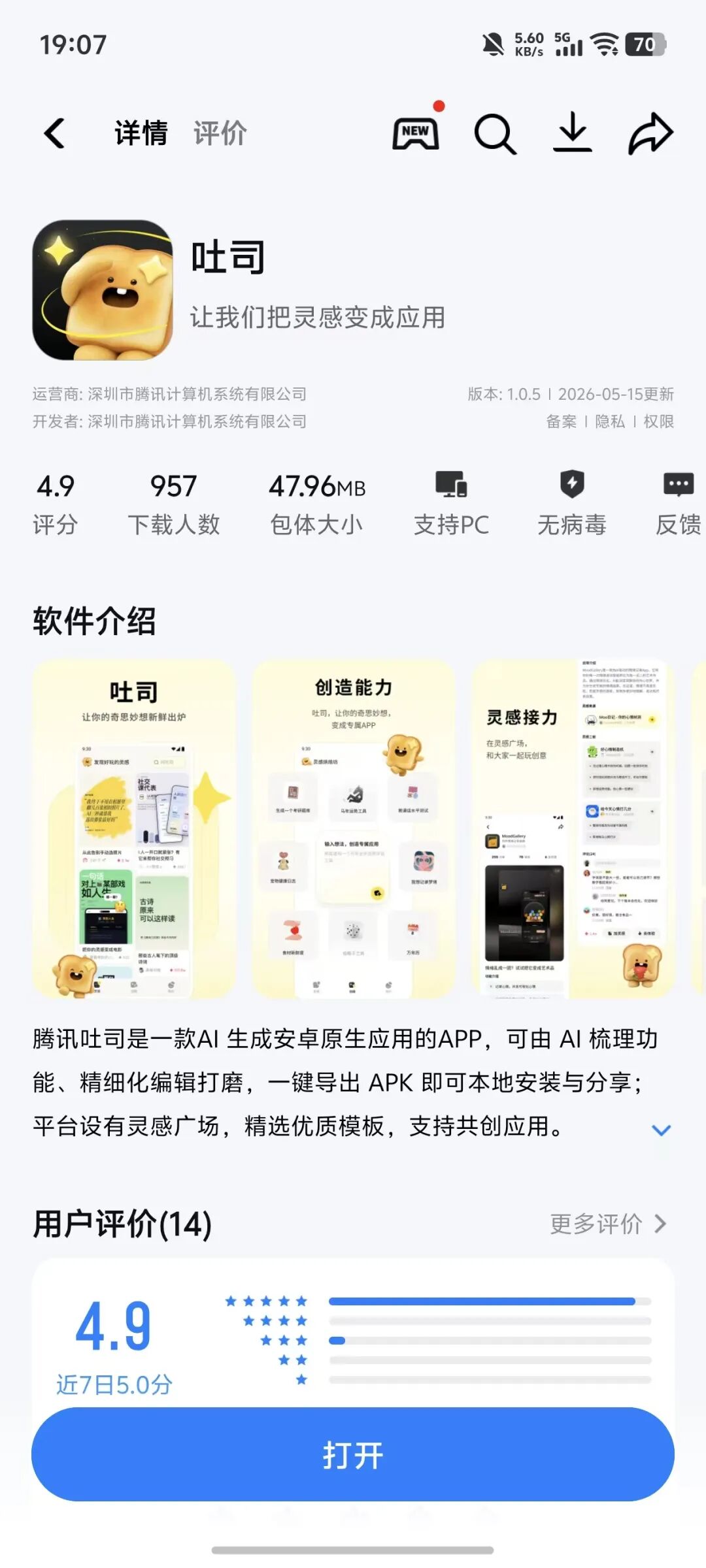
「人人都能做 App」时代真来了? 继蚂蚁灵光推出“闪应用”后,腾讯 Vibe Coding 产品「吐司」在自家应用宝商城上线,定位「应用生成及灵感共创平台」,简单来说,就是用户说需求,AI 拆解功能需求,最终输出成品应用。 (图源:应用宝) 在腾讯之前,蚂蚁灵光、百度秒哒这类 Vibe Coding 应用早已经在市场上流行。不过,它们生成的应用通常仅支持在内部平台分享,或者以在线的方式分享给其

地平线正式发布并开源HoloMotion-1,这是地平线机器人实验室面向人形机器人全身控制打造的4亿参数级机器人小脑大模型。相比以往常见的百万级、千万级机器人控制模型,HoloMotion-1将机器人“小脑”的模型规模提升到新的量级,并在端侧实现约300FPS实时推理,让大模型能力真正进入机器人运动控制闭环。通过本次开源,地平线希望降低人形机器人全身控制的研发门槛,帮助开发者更高效地构建、复现和部
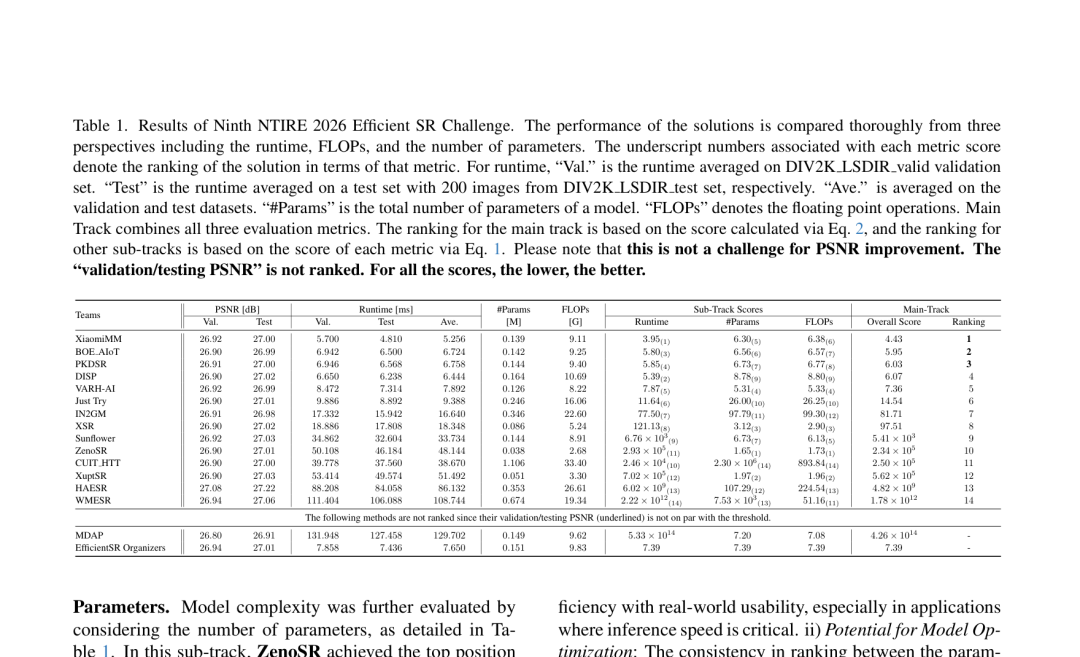
近日,小米在 CVPR 2026 NTIRE 赛事中荣获三项奖项。其中,小米玄戒多媒体算法团队斩获高效超分辨率赛道冠军,小米大模型应用团队夺得人像修复赛道冠军与反光消除赛道亚军。 NTIRE(New Trends in Image Restoration and Enhancement)由 CVPR 组委会承办,是全球规模最大、水平最高的图像恢复与增强领域学术研讨会。小米在本次赛事中展现了从硬件优
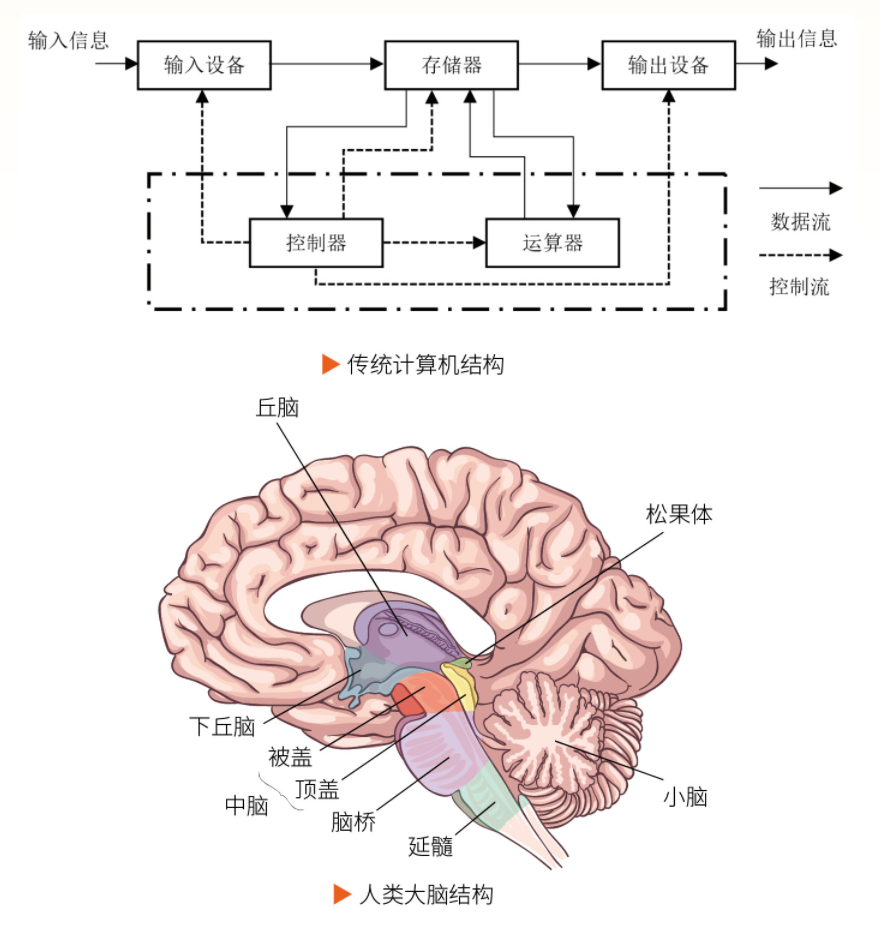
大脑天生擅长多任务并行,启发出类脑计算这一颠覆性方向。从“天机”芯片到生物计算机CL1,类脑技术正从科幻走向现实。想成为类脑智能科学家,需打好数学与生物学基础,培养跨学科思维与动手能力。 人人都惊叹大脑有多神奇! 你骑车赶路时,大脑同时调控身体平衡、识别路况,还能和同伴闲聊。人脑为何擅长多任务并行?想要成为类脑人工智能科学家,又该做好哪些准备? 人脑VS传统计算机 从图中可以看出,我们的大脑和传
AI产品越受欢迎,公司越焦虑——推理成本像屋顶漏水,持续消耗算力。vLLM、TensorRT-LLM、llama.cpp三个开源项目分别从云端调度、硬件优化和本地部署入手,试图把“每token成本”降下来,让AI从烧钱走向赚钱。 你有没有发现一个很奇怪的现象。 AI产品越受欢迎,公司反而越焦虑。 传统软件公司最喜欢的一种模式叫规模效应。 一个SaaS产品开发出来之后,新增用户的边际成本很低。用户越
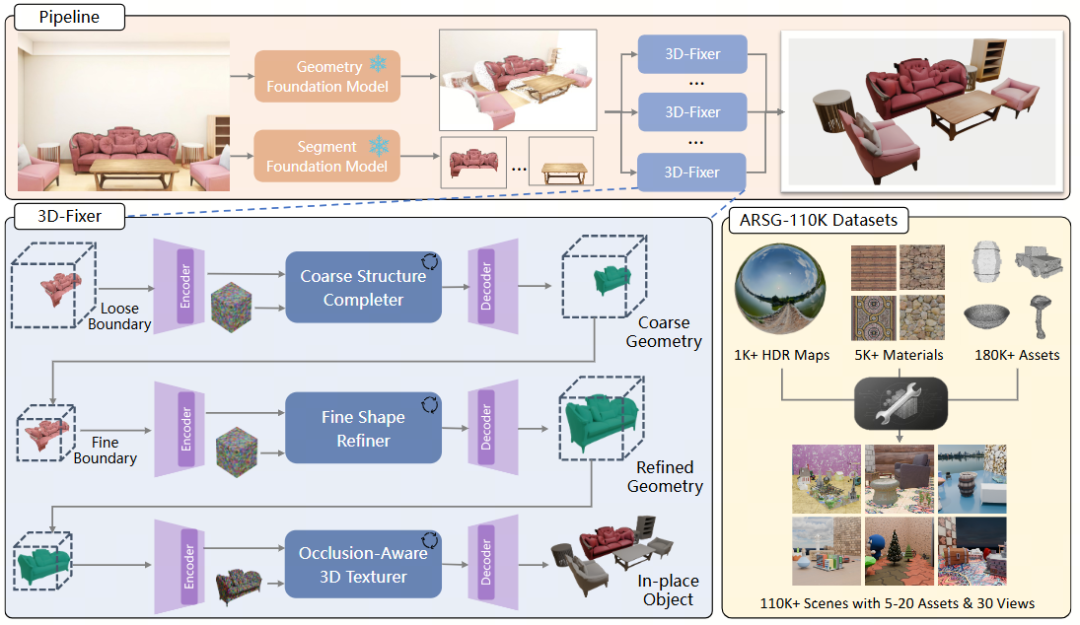
• 项目主页: https://zx-yin.github.io/3dfixer • 文章链接: https://arxiv.org/pdf/2604.04406 • GitHub代码**:** https://github.com/HorizonRobotics/3D-Fixer 现有挑战 基于单张图像生成3D场景,是构建物理世界数字孪生环境的关键技术问题。现有方法在泛化能力与生成效率之间存在显

从5亿条互联网视频中炼出全球最大的开源 GUI 操作数据集,让7B 模型在 ScreenSpot-Pro 上准确率提升38%;3B 参数的小模型做时序推理,干掉专用大模型还省了71%的 Token。这不是 PPT 愿景,而是小米 AI 团队研究成果的真实体现。 近日,ICML 2026(International Conference on Machine Learning)公布了论文录用结果。

基础模型与系统架构 精心设计 85%的受访企业指出,架构和部署是影响性能和成本的主要因素。 当今的AI体验离不开经过精心设计的平台,这些平台将大语言模型 (LLM) 与直观的用户界面相结合,帮助增强人类的能力。在考虑成本、硬件资源、延迟、安全性和可信度等限制因素的同时,工程师们正在塑造这些系统在现实环境中的运行方式和扩展能力。 ChatGPT(OpenAI)、Gemini(谷歌)、Copilot

本文主要讲述物理AI为什么离不开边缘计算。 过去两年,AI 给人的印象基本是一回事——一个对话框,一个输入框。你打字它打字,你上传它分析,AI 安静地待在屏幕里,处理着一切关于文字、图像、代码的事情。 行业的注意力也都跟着堆在那一头。云厂商抢算力,芯片厂卷训练卡,应用层抢入口,关于 AI 的大新闻几乎都和云端有关:模型又大了多少倍,集群又烧了多少钱,推理价格又降了几个点。但风向其实在悄悄变。 AI
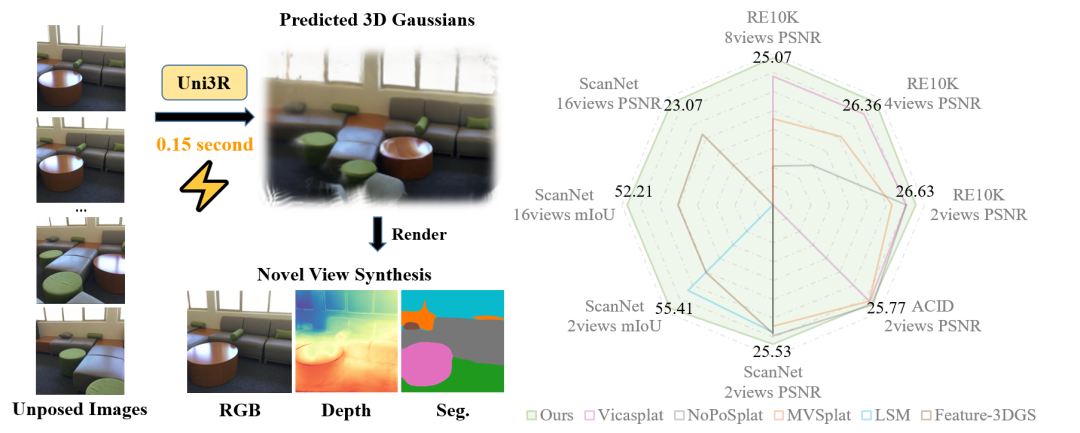
• 项目主页: https://horizonrobotics.github.io/robot\_lab/uni3R • 文章链接: https://arxiv.org/pdf/2508.03643 • GitHub代码**:** https://github.com/HorizonRobotics/Uni3R 概述 在现实场景中,通常只能获取来自多个视角的RGB图像,而缺乏相机位姿、深度或点云等
最近几天,一个叫 DeepSeek-TUI 的开源项目突然在 GitHub 彻底火了,仅仅在过去一天,Star 数量直接从 8.7k 又涨到了 16.3k。 DeepSeek-TUI 不是 DeepSeek 官方产品,而是个人开发者基于 DeepSeek V4 开发的终端原生编程智能体。但它涨星的速度很快,吸引了国内外很多 AI 开发者的关注,短短几天时间就冲上了 GitHub Trending
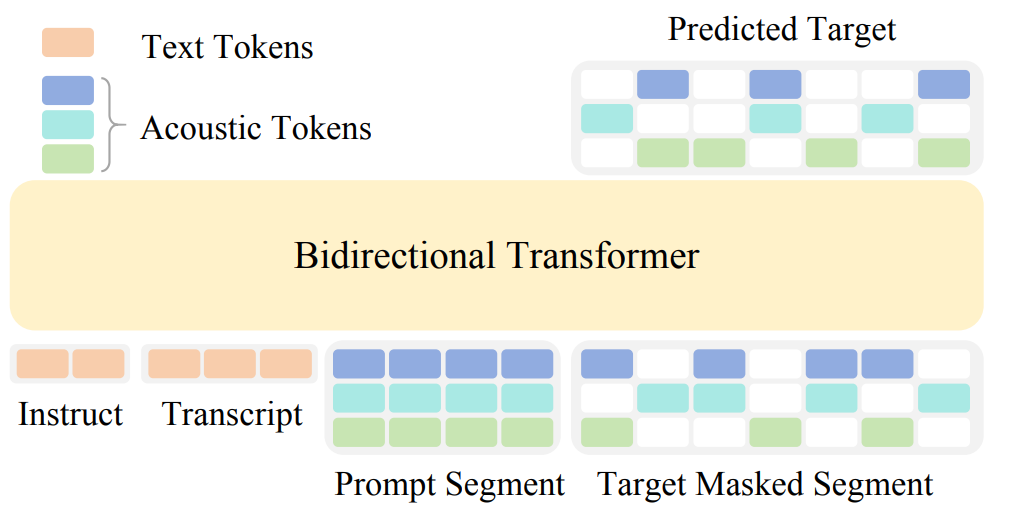
数秒克隆语音早已不是新鲜事,但能覆盖600+语种的语音克隆 TTS 模型,你见过吗!主流音色克隆 TTS 模型的多语言支持最多停留在几十种,大量低资源小语种始终难以覆盖,成为行业痛点。小米AI实验室新一代Kaldi团队全新推出 OmniVoice,以创新的极简架构打破这一局限,不仅在中英文场景达到顶尖性能,更在多语言任务中展现出超越商用系统的实力,是业内首个覆盖数百语种的语音克隆 TTS 模型,在






