简介
高通今年(2025)发布了自己的第三代Oryon核,之前没找到什么资料,最近在Chip&Cheese看到相关的PPT,但我在官方还是没找到这个PPT,所以就先拿CC网站的PPT介绍一下。
Oryon CPU一共集成了3个CPU的cluster,1和2 cluster每个集成6个Prime核,3 cluster集成6个优化功耗面积的Performance核,一共18个核。实际高通命名的Prime核一般我们习惯称为性能核Performance Core,而高通所说的性能核实际是我们习惯说的能效核Efficient Core。而用户又习惯称为“大小核”,但是“大小核”名声不好,估计是这个原因,改个名字。
整体看,频率最高可达5GHz,基础频率是4.4GHz,16M,16路共享L2 Cache,每个集群6个核。就自研器件核而言,Apple和Qualcomm是共享L2,Intel/AMD/ARM是私有L2 Cache。


L2 Cache
由6个核共享的16M,16路Shared L2 Cache,平均每个核大概2.7M的样子,和其它厂商私有L2相比差不多,一般2~3M,共享的好处是,当活跃的核少的时候,能有更多的空间被利用,即使多核都在活跃,也避免了多副本导致的利用率低。坏处就是无冲突访问延迟更大,并且有些情况可能会产生比较多的多核访问冲突,那么延迟可能更恶劣。所以一般情况下,这种共享的L2 Cache单核跑分高点,当然我只是从L2 Cache的视角谈跑分,影响跑分的因素很多。
采用MOESI一致性协议,和L1 ICache以及L1 Dcahce是inclusive关系。回填带宽是64B,由于是共享的L2 Cache,L1-Miss-L2-Hit延迟比较大,平均为21 cycle。

Fetch & Decode
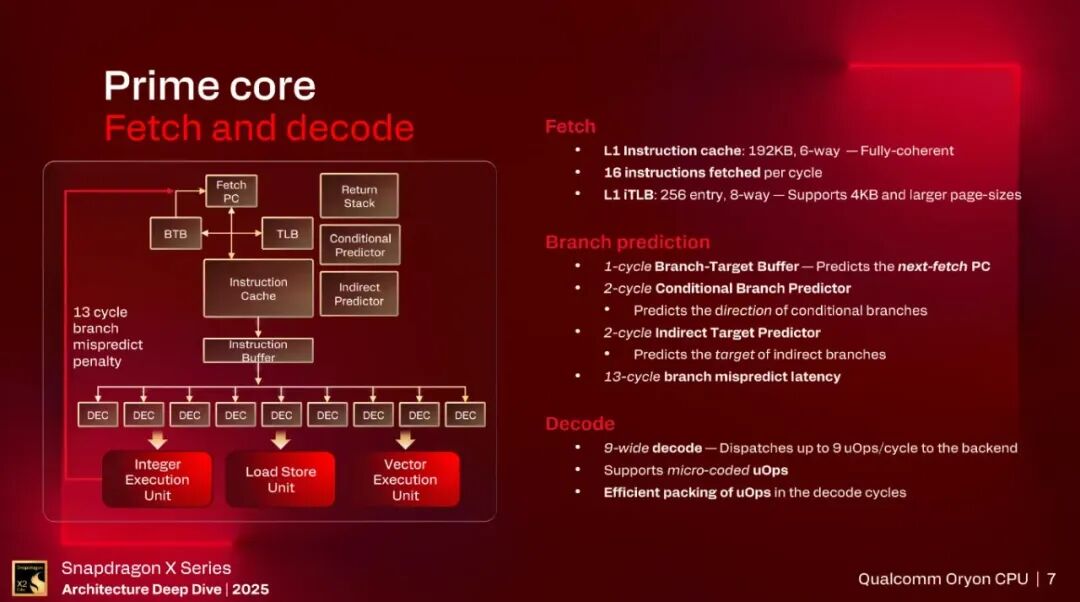
Apple用了很多年的192KB Cache,高通由于历史原因也一直在沿用,我之前写过一篇分析关于使用192KB缓存的原因,主要观点是分支预测器结构以及共享L2的因素,但我认为分支预测器是主要原因。
1-cycle的next-fetch PC预测器,就是最小的BTB(L1-BTB),一般不大且用DFF搭建,当然也有不是用DFF搭的,高通这个不清楚。2-cycle的条件分支预测器,算是比较低的延迟了,一般比较复杂的算法,做到3-cycle延迟就很不错了,当然整个前端结构也很有利于降低延迟。L2-BTB应该还是ICache。间接分支延迟2-cycle,13个cycle的分支预测错误惩罚,单纯就数值而言,不算优秀,考虑到处理器频率还挺高,也挺可以的。
9宽的decode。
Rename & Dispatch
和Decode宽度匹配的Rename宽度,同样是9。整数,向量有独立的物理寄存器files,都是400+。checkpoint属于常规的技术支持了。同样支持指令融合技术,多数的核也都会支持,只是看最终能支持多少类型。每个周期能退休9个uOps,ROB有650+的条目。

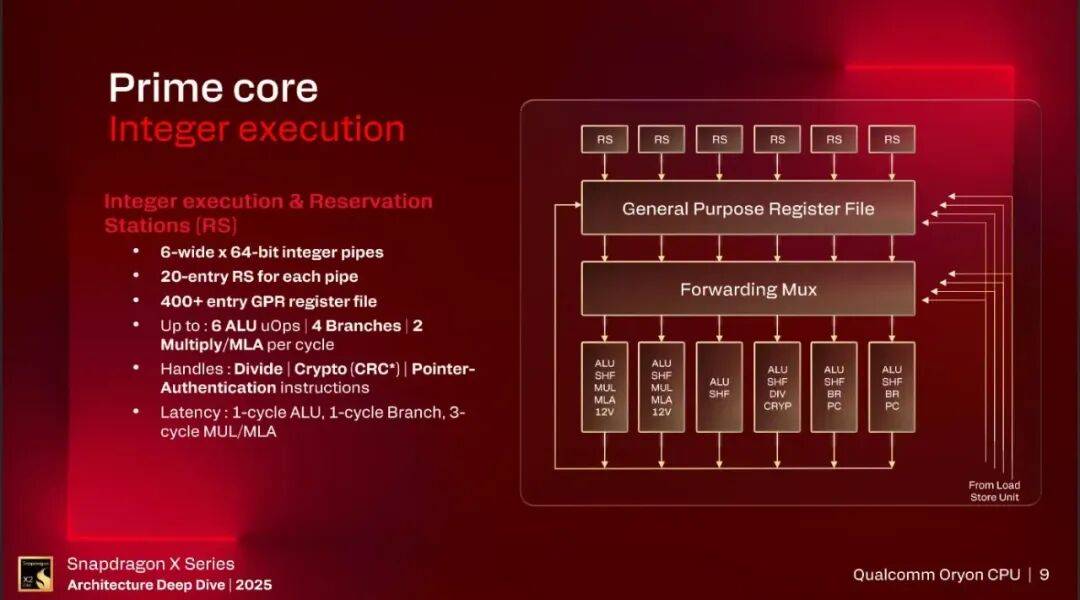
Integer Execution
6宽的64bit的整数执行流水线,400+的GPR,每个cycle最多有6个uOps,4个分支,2个MUL/MLA。4个分支执行单元是比较多的,看图上只画了2个,可能是有2个分支执行单元,然后2个复用的流水线。延迟方面就是1-cycle ALU,1-cycle Branch,3-cycle MUL/MLA。
Vector & FPU & SIMD

LSU
完全一致性的DCache,大小为96KB,每个CacheLine 64B,每个周期支持最多4个任意组合的load或者store。支持store-load forwarding,简单说这个技术就是,如果一个load依赖前面的store,但这个store还没有到缓存里面,那么load要等store写到缓存里面再load,而store-load forwarding在这种情况下,直接从store queue里面将数据读走,这样能很大程度降低延迟,提高性能,现在各家的旗舰处理器多多少少都支持一些。
192个load queue条目,56个store queue条目。预取方面支持不少类型的算法,stride,adjacent line等。

MMU
内存管理单元,高通做的确实不太一样,支持4KB核64KB的翻译粒度,我在它发布前一代核的时候就很困惑为什么不支持16KB的翻译粒度,因为ARM架构上是支持4KB,16KB,64KB一共3种翻译粒度的,支持了一种,另外2种实现的开销并不大。
支持虚拟化包括Nested虚拟化。
L1 ITLB以及L1 DTLB都是8-way,256entry,而L2 TLB是8K条目,目前为止我知道的厂商的器件核最大的(截至2025),我曾经怀疑过它将聚合的展开也算成单独的条目,具体我自己没有测试过,不过前一代的核Chip&Cheese测试过,远远没有达到它宣称的8k(大概1.5K~2K,而且他们同时测试Zen4是符合预期的)。当然了,典型的PWC这些技术也都是存在的。还有个比较特殊的点,支持16个in-flight翻译,我知道的CPU基本都是4~8,GPU会非常多,高通做了16个,不过这个模块面积开销不大,只要时序能做的下,多点总是有性能收益的。
预取方面,没有公开很多信息,但也是个性能点,一般是页表数据的预取和页面的预取。

Performance Core
姑且就按照官方的命名,这个集群也是6个核,优化了面积,功耗,当然频率也低一些,有3.6Ghz,共享的L2 Cache也砍到12MB,简单说就是各项的参数都做了降低,从公开的结构看,面积似乎只有Prime Cluster一半多一点。


总结
这一代的处理器,基本还是前代的优化,宏观看没有太多激进的改变,有意思的是,LSU那里的TLB数据和MMU那里的TLB数据不一致,很可能是PPT也是拿前一代的PPT改的,但没改干净。比较正面的是,高通的自研核真的有模有样了。









评论区
登录后即可参与讨论
立即登录