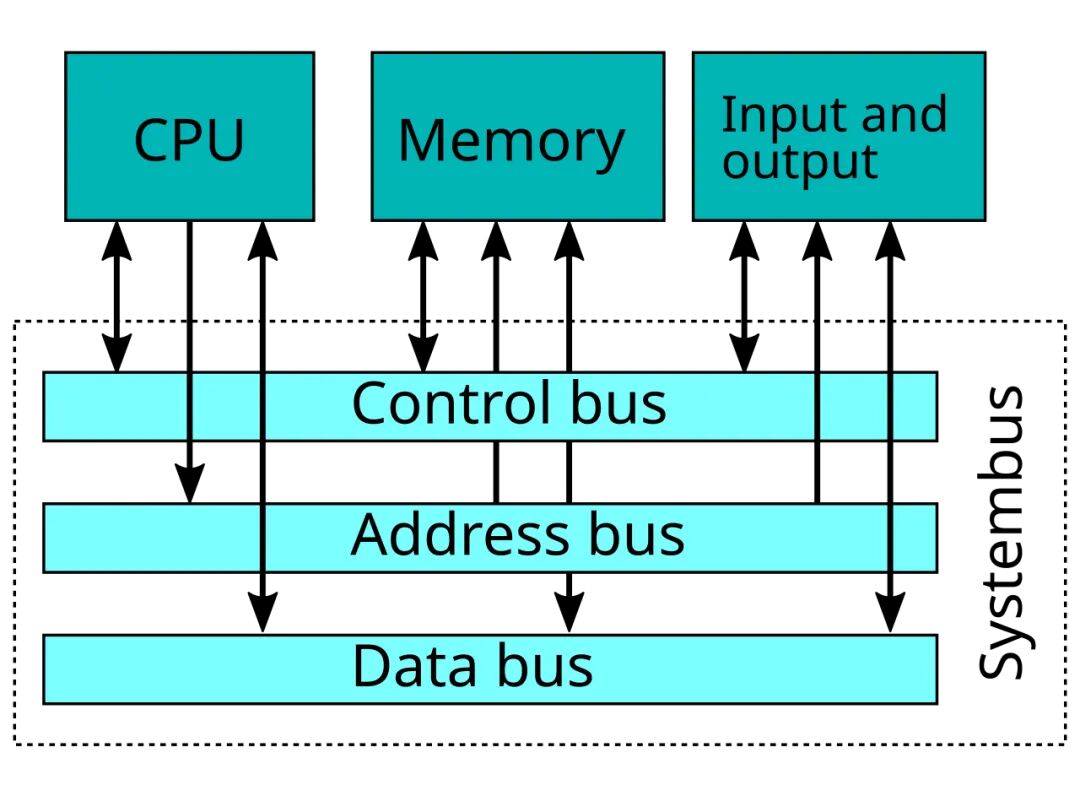
为降低芯片组件间延迟,同时在单封装内为计算引擎及网络专用集成电路集成更多电路,芯片设计厂商跳出二维平面架构、开启元器件垂直堆叠已是大势所趋。
高带宽内存(HBM)堆叠已率先实现 DRAM 内存的垂直化。相较于负责数据传输与运算的专用芯片,内存芯片功耗更低,因此 HBM 堆叠的实现难度相对更低。业界现已采用 2.5D 堆叠技术,通过中介层将 GPU、XPU 等计算芯片与 HBM 堆叠内存互连;AMD半导体(AMD)则率先在霄龙(Epyc)CPU 上实现三级缓存芯片的 3D 堆叠。如今英特尔与AMD也普遍在各类 CPU、GPU 产品中对缓存采用 3D 堆叠方案。我一直心存疑惑:既然这种方式能在不缩减缓存容量的前提下,向单封装塞入更多计算核心,为何至今仍未成为行业主流?
业界推动芯片垂直堆叠的理由显而易见,正如行业纷纷采用 2.5D 互连技术打造超大尺寸封装,通过多芯粒拼接构建虚拟大型二维芯片的逻辑一样。
十多年来,高性能计算与当下的人工智能系统中,在主板上布设 4 颗或 8 颗 GPU、XPU 早已成为常规设计。博通负责 3.5D 极致维度系统级封装(XDSiP)芯粒堆叠业务的产品营销副总裁哈里什・巴拉德瓦吉透露:依靠片外互连链路连接这些计算核心,每比特功耗约在 3 至 5 皮焦耳之间。
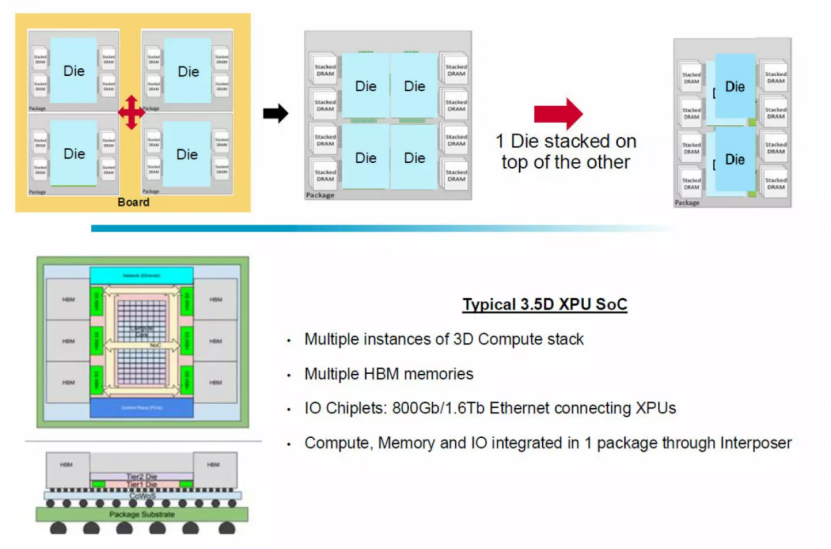
若将主板上的 4 颗计算芯片整合至单一封装内,通过裸片间直连链路互连同等计算单元,每比特功耗可降至 0.2 皮焦耳以下。封装内部互连路径远短于主板布线,既能降低功耗,也能减少传输延迟。系统架构设计师仍可依托主板与高速互连,对这类高集成封装进一步扩展,技术迭代并未止步于此。但毋庸置疑,打造性能极致的单封装芯片是算力架构设计的核心目标。
这也注定了 3D 堆叠技术纵使架构复杂、成本高昂,也终将普及。博通正与客户联合研发的主流 3.5D 架构 XPU,均搭载多颗堆叠计算芯粒与多层 HBM 内存堆叠。初代 3.5D XDSiP 架构最多支持 12 层 HBM 内存堆叠,目前博通正进一步提升堆叠层数上限。
据我推测,XPU 厂商有意暂缓跟进最新一代 HBM 规格,转而采用性价比更高的存量 HBM 产品,以兼顾内存容量与带宽需求。例如谷歌最新的 TPU 8 XPU 选用 HBM3E 内存,而非更新的 HBM4;桑巴诺瓦科技的 SN50 可重构数据处理器(RDU)采用 HBM2E 内存,以控制成本、扩充内存容量。(谷歌确实携手博通,协助台积电代工研发 “太阳鱼” TPU 8t 芯片,但据目前所知,尚未采用 3.5D XDSiP 架构。)
不过,富士通已确定在下一代 “蒙纳卡(Monaka)”Arm 服务器 CPU 中落地该技术。我们曾在 2023 年 3 月深度解析过这款芯片,目前已知其将搭载 144 颗 Armv9-A 架构核心,采用 2 纳米与 5 纳米芯粒混搭工艺。这款蒙纳卡芯片已进入样品量产阶段,富士通两年前在产品设计中加入 3D 计算芯片堆叠方案,并于 2026 年 2 月底从博通实验室取回测试样品。
目前富士通尚未公开落地博通 3.5D 极致维度系统级封装(XDSiP)芯粒堆叠的具体方案,相关细节或将留待 2027 年芯片正式发布时公布。巴拉德瓦吉透露,富士通的设计方案是将 2 纳米工艺计算芯粒,垂直堆叠在 5 纳米工艺的计算裸片之上。
巴拉德瓦吉表示,另有六家企业正将 3.5D XDSiP 技术应用于定制 AI XPU 设计。业内普遍猜测,其中两家为亚马逊云科技与元宇宙平台:亚马逊云科技的 Trainium4 芯片计划 2026 年底推出,2027 年大规模部署;元宇宙平台的 MTIA 500 同样定于 2027 年面世。以上仅为行业推测。
“客户采用 3.5D XDSiP 的核心思路,是将顶层裸片采用最先进制程工艺,承载高性能算力运算。” 巴拉德瓦吉解释道,“已有客户采用 3 纳米叠 3 纳米、2 纳米叠 3 纳米,甚至 1.4 纳米叠 3 纳米的堆叠组合,架构方案仍在持续演进。将高性能计算单元置于顶层,更利于散热;底层布设静态随机存储器、低负载计算模块与互连电路,既能控制整体发热,又可保证散热通畅。”
巴拉德瓦吉称,博通深耕 3.5D XDSiP 技术已有五年多,该方案与AMD联合台积电研发的背靠背 3D 系统集成芯片(SoIC) 架构截然不同。AMD的 SoIC 技术多用于将三级缓存裸片堆叠在计算裸片上方,并通过芯片引脚实现互连。
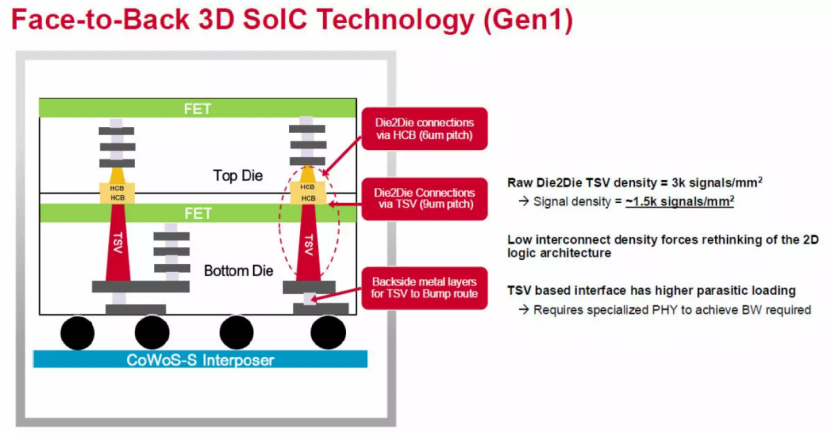
从硅通孔(TSV)密度来看,巴拉德瓦吉表示,现有背靠背堆叠架构的信号密度约为每平方毫米 1500 路信号,这要求芯片设计厂商必须精准规划上下层裸片架构与互连方式。
而采用面对面堆叠方案时,两颗裸片的金属布线天然对齐,无需在二维芯粒设计中做特殊适配,仅需专用键合材料固定即可。博通已与台积电联合研发适配 3.5D XDSiP 的键合工艺。
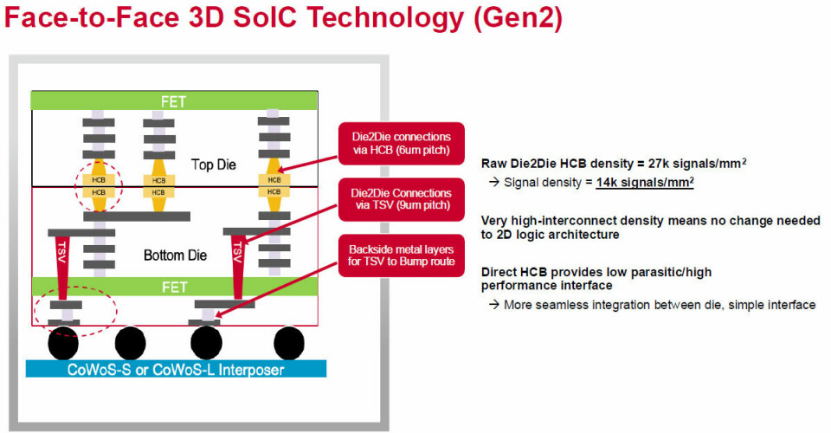
依托 3.5D XDSiP 架构,两颗裸片间的信号密度可达每平方毫米 14000 路,较传统方案提升近一个数量级。
这也是目前已有 1 款 CPU、6 款 XPU 敲定采用该技术的核心原因。博通透露,富士通并非首款量产落地的产品,六款 XPU 中至少有一款将于 2026 年下半年正式出货。









评论区
登录后即可参与讨论
立即登录