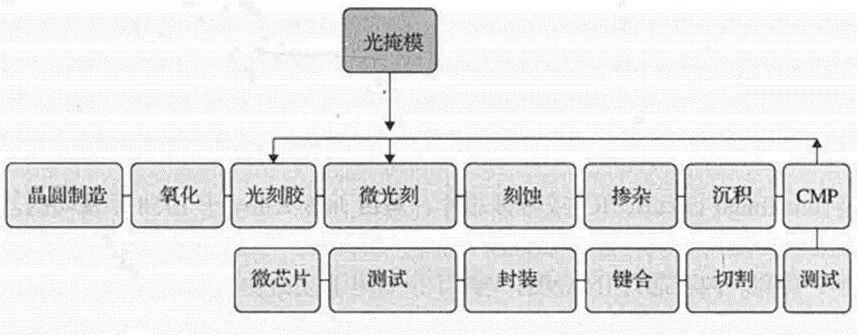
摩尔定律未死,但已从“晶体管缩小”的线性红利转为“系统集成”的复合竞争。AI时代,芯片性能瓶颈从算力转向数据搬运与互联效率,先进封装成为连接GPU、HBM与Chiplet的关键杠杆,推动产业从“堆晶体管”进入“搭系统”的新阶段。
过去几十年,半导体行业有一个近乎信仰级的规律:摩尔定律。
简单说,就是芯片上的晶体管数量会周期性增加,芯片性能不断提升,单位计算成本不断下降。这个规律支撑了 PC、智能手机、云计算和移动互联网的爆发。
但现在,一个问题越来越频繁地出现:
摩尔定律是不是失效了?
如果只看“晶体管还能不能继续变小”,答案是:还没有完全失效。
如果看“芯片还能不能像过去那样,靠制程微缩轻松获得性能、功耗和成本红利”,答案是:传统摩尔定律的黄金时代确实已经过去了。
这就是今天半导体行业最大的变化。
过去,芯片公司提升性能,主要靠一条路:把晶体管做小。
现在,芯片公司提升性能,必须走多条路:先进制程、Chiplet、HBM、先进封装、高速互联、液冷散热、系统级架构一起上。
所以,先进封装才会突然变得这么重要。
它不是因为“封装行业被重新炒作”,而是因为芯片性能提升的主战场变了。
一、摩尔定律不是死了,而是变贵了、变慢了、变复杂了
很多人讨论摩尔定律时,容易陷入两个极端。
一种说法是:摩尔定律已经死了,半导体没什么好突破了。
另一种说法是:先进制程还在往前走,所以摩尔定律没有问题。
这两种说法都太简单。
更准确的说法应该是:
摩尔定律没有突然死亡,但它的经济性和系统性红利已经大幅减弱。
过去从 90nm 到 45nm,再到 28nm,制程升级带来的收益非常直接。晶体管变小以后,芯片面积下降,性能提升,功耗下降,单位成本也更好看。那时候,芯片公司只要跟上制程节奏,就能吃到一大块红利。
但进入 7nm、5nm、3nm 以后,问题变了。
先进制程当然还在进步,可是每前进一步,代价都更高。EUV 光刻、先进材料、复杂工艺、良率控制、设计成本、EDA 成本、掩膜成本,都在上涨。
过去像是在高速路上开车,踩油门就能往前冲。现在像是在山路上开重卡,也能往前走,但速度慢了,油耗高了,风险也大了。
这不是说先进制程不重要。
先进制程仍然非常重要。高端 GPU、CPU、AI 加速器仍然离不开先进制程。
但先进制程已经不是唯一答案。
二、AI 时代把芯片性能问题重新定义了
过去我们谈芯片性能,常常看频率、核心数、晶体管数量。
AI 时代,这些指标还重要,但不够了。
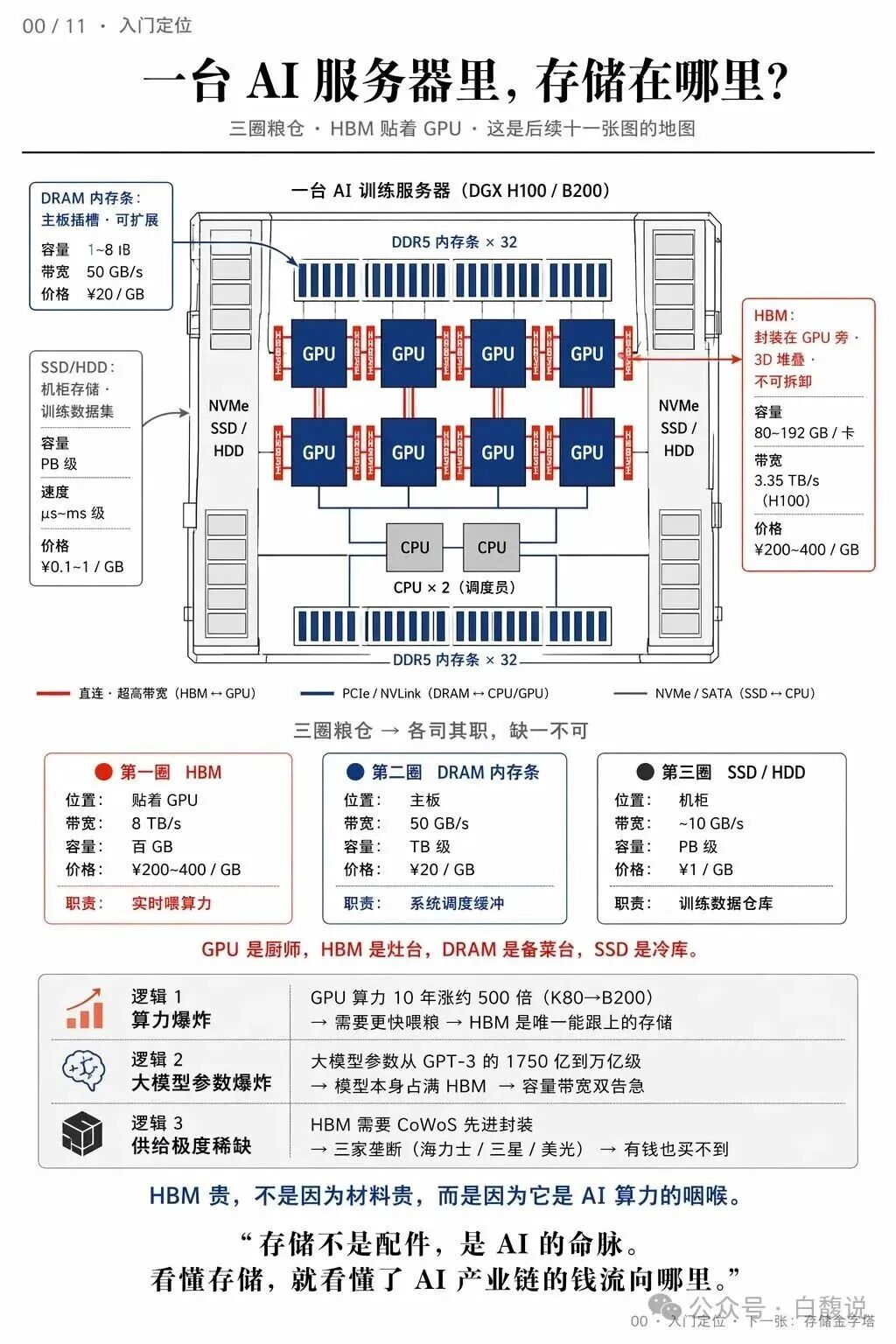
因为 AI 芯片不是单纯“算得快”就行。它还要“数据来得快”“存得下”“连得上”“散得出去”“量产得了”。
大模型训练和推理,本质上是一个巨大的数据搬运和矩阵计算系统。
GPU 负责计算,但模型参数、激活值、KV Cache、训练数据都要不断进入计算核心。如果数据搬不过来,GPU 就会空转。
这就像一个工厂。
GPU 是车间里的工人。
HBM 是离车间最近的仓库。
Chiplet 是不同功能的生产线。
先进封装是厂区里的高速道路、传送带、电网和冷却管道。
如果道路太窄,仓库离车间太远,电力不稳,散热不好,那么工人再多也没用。
AI 芯片真正的瓶颈,经常不是“有没有计算单元”,而是“计算单元能不能被持续喂饱”。
这就是为什么 AI 时代会把 HBM、CoWoS、Chiplet、NVLink、CXL、光互联这些词都推到台前。
它们解决的不是同一个细节问题,而是同一个系统矛盾:
算力需求增长太快,传统芯片集成和板级互联已经跟不上。
三、先进封装为什么成了新的性能杠杆?
先进封装的价值,可以用一句话概括:
它把“不能继续简单塞进一颗芯片里的东西”,重新组织成一个高性能系统。
过去,芯片行业最喜欢做 SoC,也就是把 CPU、GPU、缓存、I/O 等模块尽量放进一颗芯片里。这样集成度高,通信快,功耗低。
但问题是,AI 芯片越来越大,越来越复杂。
如果所有东西都塞进一颗超大芯片,良率会下降,成本会飙升,制造风险会变大。芯片面积越大,晶圆上的缺陷越容易击中它。一个小缺陷,可能就让一颗昂贵的大芯片报废。
Chiplet 的思路就是:不要硬塞。
把大芯片拆成多个小芯片。计算模块用先进制程,I/O 模块可以用成熟制程,缓存、控制、互联也可以分开设计。这样可以提高良率,降低部分成本,也能让不同模块独立迭代。
但 Chiplet 有一个前提:拆开以后,必须高速连回去。
如果拆开以后互联太慢,延迟太高,功耗太大,那就不是先进架构,而是“拆散了的系统”。
先进封装的作用,就是让这些小芯片重新像一个整体一样工作。
它不是简单把芯片装进外壳里,而是在封装内部建立高密度、低延迟、低功耗的互联网络。
这就是新的性能杠杆。
过去的性能杠杆是:晶体管缩小。
现在的新杠杆是:系统集成距离缩短、互联带宽变宽、数据搬运能耗降低、异构芯片协同效率提高。
四、从“堆晶体管”到“搭系统”
先进封装为什么重要?因为芯片性能提升已经从“堆晶体管”进入“搭系统”。
传统摩尔时代,核心问题是:如何在一颗芯片里放更多晶体管?
AI 时代,核心问题变成:如何让更多计算单元、更多存储、更大带宽和更复杂互联一起工作?
这两种问题完全不同。
第一种问题主要靠制程。
第二种问题必须靠系统级集成。
举个通俗的例子。
以前造房子,主要靠把每一层楼修得更薄、更紧凑,这样同样面积能放更多房间。
现在楼已经很高,继续往上加很难,成本也很高。于是城市发展开始靠地铁、高架、商业区、物流园、数据中心和能源系统协同。
城市效率不只取决于最高那栋楼,还取决于整个城市的连接效率。
芯片也是一样。
一颗 GPU 再强,如果 HBM 不够,带宽不够,互联不够,散热不够,系统性能就上不去。
先进封装就是在芯片尺度上做“城市规划”。
它把 GPU、HBM、I/O Die、Cache Die、Chiplet 放到更近的距离,用更密的线路连接起来,让数据用更短路径流动。
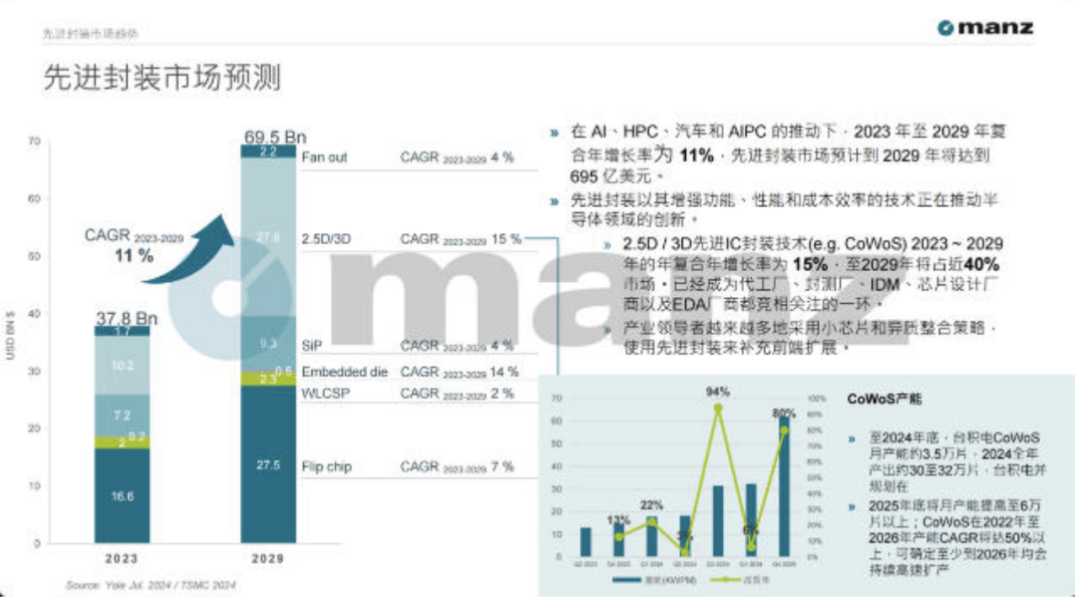
这就是为什么 2.5D 封装、3D 封装、CoWoS、SoIC、InFO、Foveros 这些技术越来越重要。
它们不是封装名词的堆砌,而是后摩尔时代的系统设计工具。
五、HBM 是先进封装价值爆发的典型案例
如果要找一个最能说明先进封装价值的例子,那就是 HBM。
HBM 的中文可以理解为高带宽存储器。它不是普通内存,也不是普通显存。
它通过垂直堆叠,把多层 DRAM 叠起来,再用非常宽的数据接口和 GPU 连接。它的优势是带宽高、距离近、能效好。
问题是,HBM 不能离 GPU 太远。
如果 GPU 在一边,存储在很远的地方,中间靠普通主板连线,那么带宽、功耗和延迟都很难满足高端 AI 需求。
所以 HBM 必须贴近 GPU。
怎么贴近?
靠先进封装。
2.5D 封装和硅中介层的价值,就是让 GPU 和 HBM 像住在同一个产业园里,而不是隔着几座城市。
这也是为什么高端 AI GPU 经常要和 CoWoS 绑定讨论。
CoWoS 的真正价值,不是“包装高级”,而是为 GPU 和 HBM 提供超高密度互联平台。
AI 芯片不是只靠 GPU 强。
AI 芯片要强,必须 GPU 强、HBM 强、封装强、互联强、散热强。
任何一个环节短板,都会让最终算力打折。
六、为什么台积电的重要性不只在先进制程?
过去分析台积电,很多人只看先进制程。
谁能量产 7nm、5nm、3nm,谁就有竞争力。
这个判断仍然成立,但已经不完整。
在 AI 芯片时代,台积电的重要性还来自先进封装。
因为 NVIDIA、AMD 等高端 AI 芯片,不只需要先进制程制造 GPU Die,还需要先进封装把 GPU、HBM 和其他芯片整合起来。
如果只有先进制程,没有足够的先进封装产能,芯片还是交付不出来。
这就像汽车工厂。
发动机能造出来,不代表整车能交付。你还需要变速箱、电池、底盘、车身、电子系统和总装线。
先进封装就是高端 AI 芯片的“总装线”,而且是非常高难度的总装线。
它涉及基板、硅中介层、RDL、TSV、微凸点、混合键合、贴装、测试、热管理和可靠性控制。
这也是为什么先进封装不容易快速复制。
买设备不等于有能力。
建产线不等于有良率。
做出样品不等于能稳定量产。
真正难的是长期工艺经验、客户协同、良率爬坡、供应链组织和系统级验证。
七、先进封装不是替代先进制程,而是放大先进制程
有一种误解需要澄清:
先进封装火了,不代表先进制程不重要了。
事实正好相反。
先进封装不是替代先进制程,而是放大先进制程的价值。
先进制程让单个计算芯片更强。
先进封装让多个强芯片协同工作。
如果没有先进制程,GPU 的计算密度不够。
如果没有先进封装,GPU、HBM、Chiplet 之间的数据通道不够。
两者不是谁取代谁,而是共同构成高性能计算芯片的底座。
未来的 AI 芯片竞争,很可能不是单一路线竞争,而是组合能力竞争。
谁能同时掌握先进制程、先进封装、HBM 供应、高速互联、软件生态和整机柜系统,谁才能真正交付 AI 算力。
这就是产业竞争的变化。
过去是“谁能做出最强芯片”。
现在是“谁能交付最强系统”。
八、为什么先进封装会成为产业链新壁垒?
先进封装的壁垒有三层。
第一层是技术壁垒。
线宽线距要更小,互联密度要更高,芯片间距要更近,热应力要可控,翘曲要控制,封装良率要稳定。随着 GPU 和 HBM 越来越大,封装面积也越来越大,难度会继续上升。
第二层是制造壁垒。
先进封装不是实验室工艺。它必须大规模量产。高端 AI 芯片单价很高,客户要求极高。良率小幅波动,就会影响巨大成本。
第三层是生态壁垒。
先进封装不是封测厂自己就能决定的。它需要和芯片设计公司、晶圆厂、HBM 厂商、基板厂、设备厂、材料厂、服务器厂一起协同。
这就是为什么先进封装越来越像一个产业组织能力,而不只是工艺能力。
九、对国产产业链意味着什么?
对国产半导体来说,先进封装是一个绕不开的方向。
原因很简单。
如果高端制程受限,就更需要通过系统级集成来提高整体性能。
如果 AI 芯片要走 Chiplet 路线,就必须解决高密度互联和先进封装。
如果国产 AI 芯片要进入数据中心,就必须和 HBM、先进基板、液冷散热、服务器系统一起协同。
所以,国产先进封装不是“补一个后段环节”,而是补高性能计算芯片的系统能力。
这里面会有很多机会。
例如高端基板、RDL、TSV、临时键合、减薄、贴装、检测、热界面材料、液冷、封装仿真、可靠性测试,都可能受益。
但也要克制一点。
先进封装不是一个短期讲故事的行业。它需要长期工艺积累。它的核心不是能不能做出样品,而是能不能稳定量产,能不能进入头部客户供应链,能不能持续提高良率。
十、最后的判断
摩尔定律真的失效了吗?
我的判断是:没有简单失效,但它已经从“单颗芯片尺度的线性红利”,转向“系统级集成的复合红利”。
过去,性能提升主要靠晶体管缩小。
现在,性能提升要靠五个杠杆一起发力:
先进制程提高计算密度。
Chiplet 改善良率和架构灵活性。
HBM 提高存储带宽。
先进封装缩短连接距离,提高互联密度。
系统级设计解决供电、散热、网络和软件协同。
先进封装之所以成为新的性能杠杆,是因为它正好站在这些矛盾的交汇点。
它连接先进制程和系统架构。
它连接 GPU 和 HBM。
它连接 Chiplet 和高密度互联。
它连接芯片性能和服务器交付。
它连接技术路线和产业竞争。
所以,先进封装不是摩尔定律结束后的临时补丁。
它更像是后摩尔时代的新道路。
未来十年,看高性能计算芯片,不能只问“用了几纳米制程”。
还要问:
HBM 怎么接?
Chiplet 怎么连?
封装怎么做?
良率怎么控?
功耗怎么压?
散热怎么解决?
产能谁来保证?
最后能不能变成可交付、可扩展、可赚钱的 AI 算力?
这就是先进封装成为新性能杠杆的真正原因。
摩尔定律没有彻底退场。
只是半导体行业已经从“缩小晶体管的时代”,进入了“重构系统的时代”。
不代表中国科学院半导体所立场







评论区
登录后即可参与讨论
立即登录