老黄演讲后,网上很多博主都发了关于GTC的内容,但是绝大多数都是新闻性质的,他们只讲了黄仁勋都说了啥。这篇文章我们结合 NVIDIA 的技术规划,来聊一聊网上可能没有的分析和GTC的核心看点。对于万亿营收和CPO的信息,都是大家知道的了,这篇文章就不再赘述了。
1、CPX的黯然退场
在上个月下旬的时候,网上还依然传着很多关于 CPX 要使用 HBM 的传言。我当时就听到消息说 CPX 要取消,我当时还不太信,但事实证明确实是被 LPU 取代了。

那为什么会取代呢?就是因为英伟达的路线转换,他们要从 prefill 加速切换到 推理加速。
2、谁是这次 GTC 大会之后最大的受益方?
那显然是三星。因为 LPU 是找三星独家代工,采用的是三星的 N4 工艺。这意味着三星不仅是英伟达全层级存储的核心供应商,现在更独揽了 LPU 的代工大单。
在Rubin上,三星的综合价值量已经超过台积电了,因为台积电只负责代工加封装。

3、LPX 机架引入 FPGA 的作用
可能很多人都没想到,在 LPX 机架上面引入了 FPGA。那么它的作用是什么呢?
- 专门负责实现系统内可配置的串联通信旁路
- 后端搭配了一颗 CPU 进行协同控制
这种精密协同架构保障了 256 颗 LPU 能够作为单一的巨型处理器运行,从而实现低延时的确定性推理加速。
4、为什么要把CPU独立成机柜?
是因为我们已经正式迈入智能体时代。智能体在自主工作时,需要频繁地调用工具、执行逻辑代码、进行强化学习和自我纠错。
而独立的 CPU 机架,正是为了提供海量的“沙盒”环境而生。单个机架集成了 256 颗 CPU,可以同时维持超过 22,500 个并发的智能体测试和验证环境,填补了 GPU 在复杂单线程逻辑处理上的短板。
5、英伟达为什么要设独立的存储机柜?
这就要结合英伟达之前提出的 ICMS(推理上下文内存存储)方案来解释了。在智能体时代,模型需要处理数百万 token 的超长上下文,导致 KV Cache 的数量呈线性暴增。
如果将海量的 KV Cache 全部放在 HBM 层,不仅容量受限,而且成本非常高。但如果卸载到传统的共享化企业存储中,其功耗过大,而延时又会严重拖慢推理速度,导致 GPU 处于闲置等待状态。
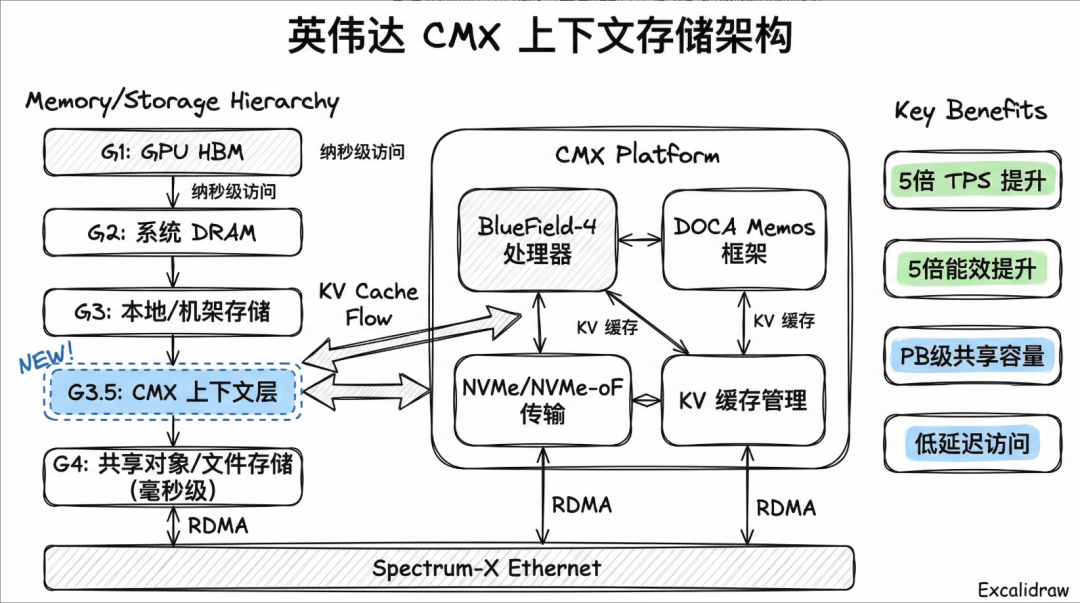
因此,英伟达采用了分级存储架构:
- ICMS 充当了整个 AI 集群的长期记忆库。
- 它专门针对海量临时 KV Cache 数据的存储、检索和共享进行了优化。
- 通过高速 RDMA 网络,它能够提前将上下文数据预加载回 GPU 内存,从而避免了历史数据的重复计算,显著提高效率。
6、抛开技术层面,老黄最关注的是什么?
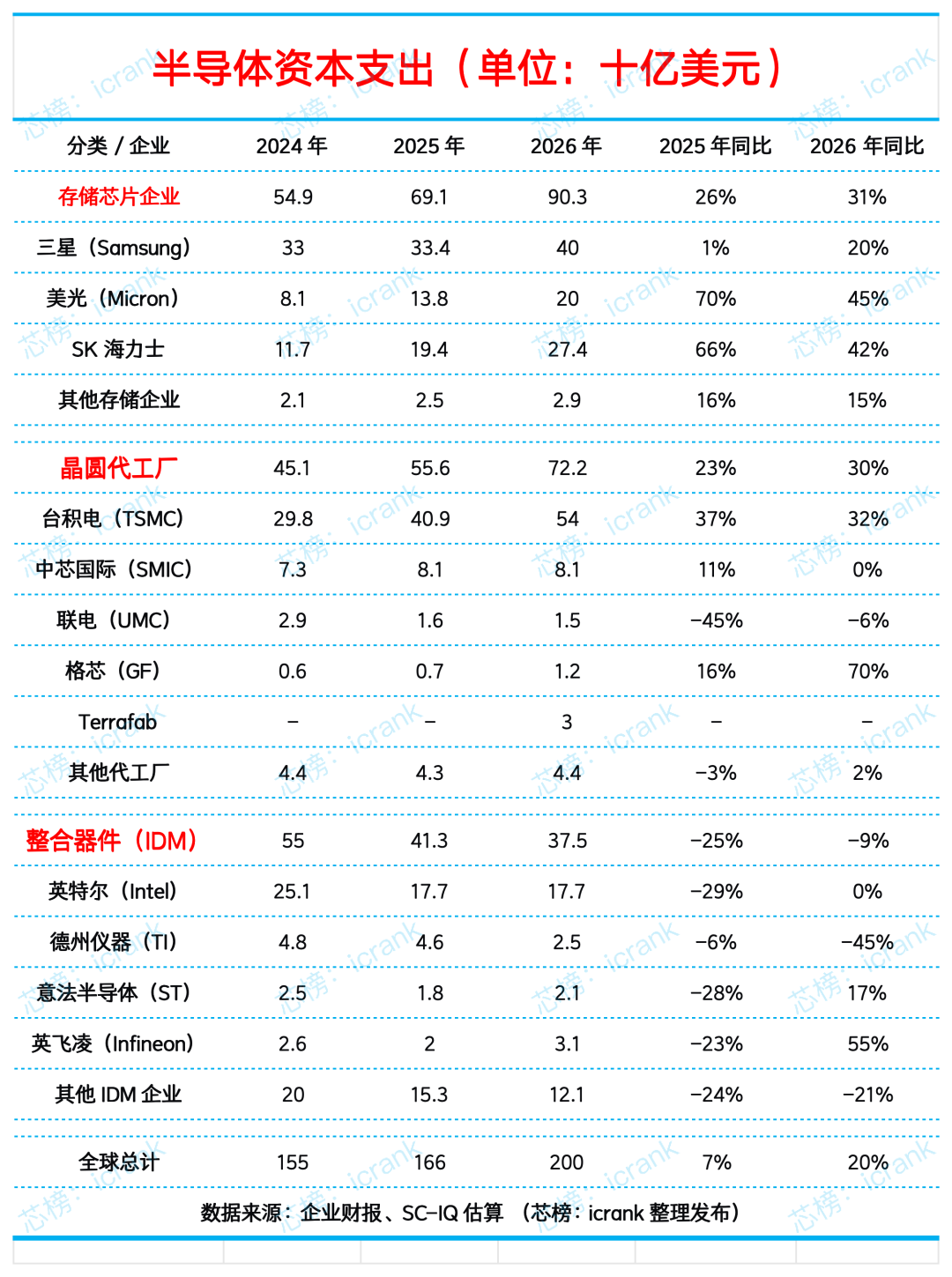
抛开第六个看点,抛开所有的技术参数,老黄最看重的底层护城河其实是产能和供应链。
最近他频繁来亚洲,是为了锁定存储、晶圆代工和先进封装产能。这也是他这两年频繁来亚洲的原因,因为要锁定存储晶圆和 CoWoS 产能。黄仁勋在供应链管理上的优势,是其他所有企业都望尘莫及的。







评论区
登录后即可参与讨论
立即登录