在传统摩尔定律逐渐失效的背景下,半导体行业正在寻找新的性能增长路径。在2026年IEEE ISCAS大会上,华为提出“τ(时间)微缩”方法,将性能优化从“几何尺寸”转向“时间压缩”,并以工程实践加以验证(通过近6年设计并量产的381款芯片)。
在ISCAS 2026的keynote演讲中,华为半导体总裁何庭波女士开口的开场白是:“过去6年我经常会被问到:在手机、AI这些高度竞争的行业里,你们是如何存活下来的并重返舞台的?”
“6年前,几何缩微进入了平台期。我们开始重新思考摩尔定律和电子系统的本质。我们很快注意到,半导体的演进不单单是几何缩微。实际上,几何缩微在时间维度同样带来了收益。比如更快的晶体管、更快的电路响应速度、更高的芯片频率等等。”她指出。
华为自此把关注焦点从几何尺度的缩微转移到时间尺度的缩微——τ定律,把时间缩微作为电子系统演进的新纲领。
【一个有意思的小细节是,τ 定律也常被称作 Her’s Law。该定律最早由何庭波提出,华为内部将其俗称为何式定律,读音上恰好和 Her’s Law 高度契合,叫法也就由此衍生而来。】
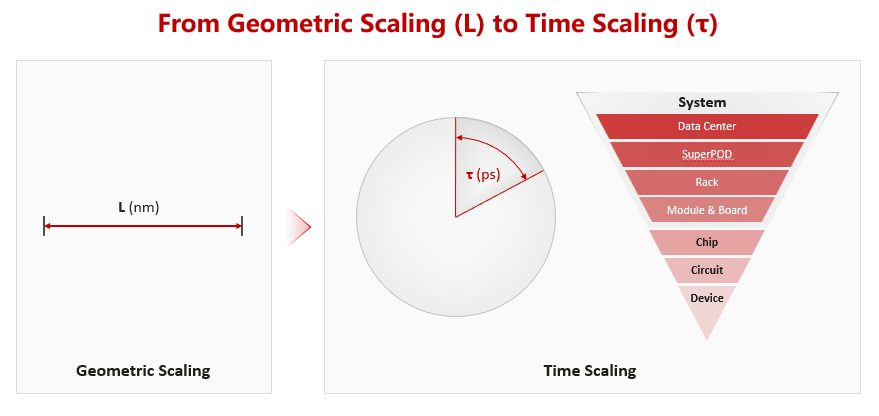
图:从几何尺度的缩微转移到时间尺度的缩微。
τ定律的提出,源于对摩尔定律本质的重新理解。何庭波指出,“几何缩微不仅带来尺寸上的变化,也在时间维度产生收益,例如更快的晶体管切换速度、更短的电路响应时间以及更高的芯片频率。在这一视角下,空间与时间是“一体两面”,即使几何缩微放缓,时间层面的优化仍然可以继续推进。”
因此,问题被重新表述为:并非“能否继续缩小晶体管”,而是“能否继续缩短系统时间”。在工程上,这一抽象概念被进一步具体化:τ本质上可以映射为RC延迟(τ ≈ RC,R为电阻,C为电容)
在具体实现上,华为提出多层级“Folding(折叠)”设计方法。
Folding(折叠):以结构重构缩短路径
τ scaling在实现层面依赖的Folding(折叠)的基本思想是:通过三维结构重排,直接缩短信号传播距离,从而降低RC延迟。
LogicFolding通过将关键路径逻辑分布于垂直有源层,利用混合键合降低路径长度与RC延迟。传统电路延迟可表达为 τ ∝ 路径长度 × RC,folding通过空间重构直接降低路径长度。系统性能最终受制于关键路径上触发器之间的传播延迟,而这一延迟主要由逻辑深度和互连RC决定。
“因此,优化的核心并非单纯增加晶体管数量,而是压缩关键路径。在这一背景下,LogicFolding通过将关键路径上的组合逻辑在不同物理平面之间重新分布,显著缩短信号传输路径,并降低寄生电阻与电容,从而压缩传播时间。与此同时,跨层布局也使时钟分布更加集中,时钟偏差显著降低,时序裕量被进一步压缩,最终带来更高的运行频率。”何表示。
“这一方法的成立依赖明确的工艺边界条件。经过多轮探索,华为指出,混合键合间距必须控制在顶层金属间距的三倍以内。在当前约720nm的顶层金属间距下,这意味着键合间距需小于2μm。当这一条件满足时,跨层连接可以被等效为额外金属层,LogicFolding从理论转化为工程可行,也正是在这一临界点上,其所谓的“性能跃迁”得以实现。”何指出。
基于这一设计方法,华为在最新一代Kirin芯片中实现了首次量产验证。
Kirin 2026采用“自由逻辑设计”理念,将处理核心从传统单层结构扩展为双层有源架构,使LogicFolding真正进入芯片级应用。
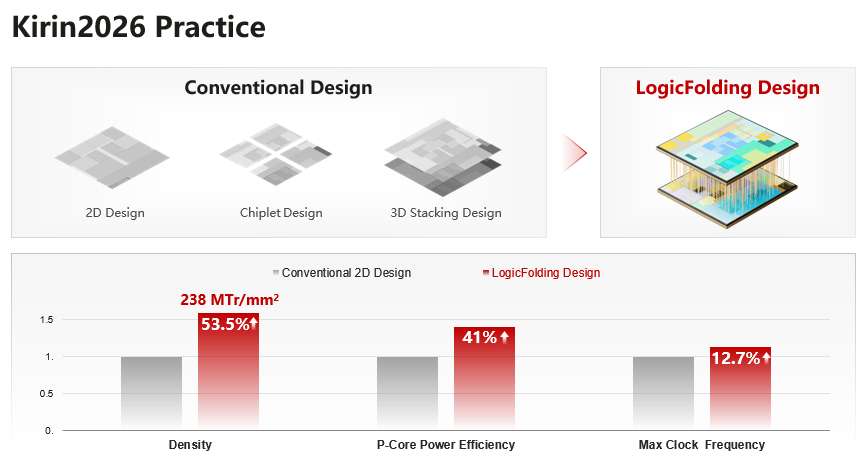
从结果来看,Kirin 2026 SoC带来“阶跃式”提升:在此前三年中,晶体管密度仅从126 MTr/mm²提升至155 MTr/mm²,而在引入LogicFolding后,该指标在单一代内跃升至238 MTr/mm²。同时,性能核心的能效提升约41%,最高工作频率提高约13%。
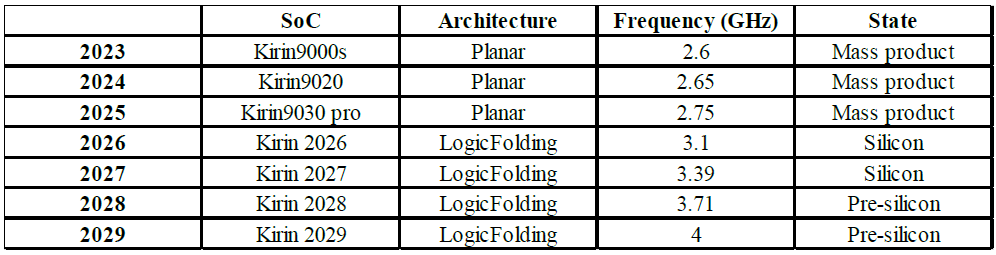
“这一组数据表明,在不依赖工艺节点演进的情况下,通过结构重构和路径压缩,仍然可以获得接近甚至超过传统缩微带来的性能收益,也构成了τ scaling在实际产品中的首次系统级验证。”何分享道。
在更高层级,CircuitFolding与ChipFolding进一步将优化扩展至时钟网络与系统结构,通过跨层路径收敛降低延迟。
“当我们把视角从单个芯片提升到整个AI系统,通信时间就变得非常关键。”何指出,超过80%的系统能耗来自数据搬运,超过70%的成本来自数据存储。
围绕降低系统τ的目标,华为设计了Unified Bus(UB),通过memory语义通信,将延迟从微秒级降低至约100纳秒(约500倍降低)。在传统架构中,数据跨节点需要经过多层协议转换,路径复杂、延迟高、成本也高。而UB通过全对等(peer-to-peer)架构,直接避免了这些跨协议转换,让数据可以在内存语义层面完成传输,从而显著降低延迟、提升可靠性,也让整个系统更简单。最终的效果是,让大规模AI系统尽可能接近“System as one chip”——像一颗芯片一样运行。
在互连实现上,问题又变成:当单芯片带宽从数百Gbps提升到Tbps之后,传统电互连开始遇到极限。传输距离变短、线缆变得过大,甚至带来供电和散热压力。针对这一挑战,华为引入了Hi-ONE光互连引擎。单个模块可提供8 Tb/s带宽,并与UB带宽保持一致。与此同时,电互连距离被压缩到5厘米左右,而整体系统的连接距离则可以扩展到100米级别。这使得算力不再需要集中在单一机柜中,而是可以跨机柜分布,从而更好地控制功耗密度和散热压力,也让超大规模数据中心的高密度互联第一次具备现实可行性。
SystemFolding的思路是通过将原本集中在芯片边缘的内存、I/O和电源,从二维边界重新分布到三维空间的“表面”上,使这些关键资源能够与计算能力一样按面积尺度同步扩展,从而缓解扩展失衡。
按照华为的规划,未来System Folding结构将成为主导方向,其预测到2035年系统集成度有望提升超过100倍,而在技术路径上,2030年前仍将以chiplet和2.5D封装为主,之后则逐步转向全面引入Folding的三维系统架构。
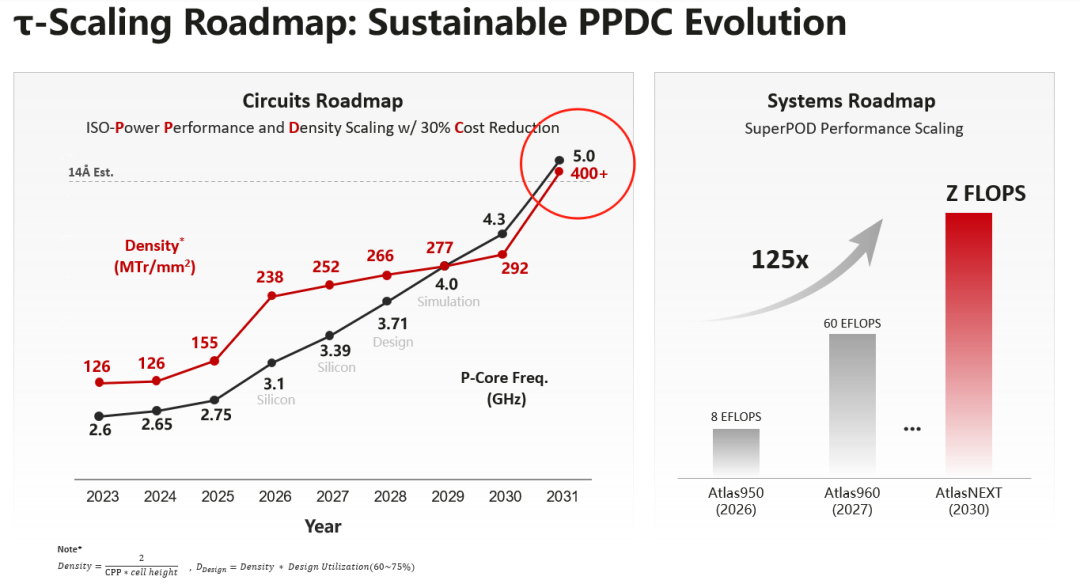
图:τ scaling线路图。
在谈及未来路线图时,何庭波进一步总结了τ scaling在过去六年的阶段性成果,并给出了明确的演进方向。她表示:“在电路层面,晶体管密度已经从155 MTr/mm²提升至240–300,并正快速逼近乃至超过400;在系统设计考虑下,有效晶体管密度也从不足100提升至250以上,说明基于τ优化的“非节点扩展路径”已经具备可持续性。同时,这一路径为SoC性能释放打开了新的空间,CPU大核频率预计在2031年前突破5GHz(如上图所示)。”
与其它路径的分歧:“τ scaling” vs “工艺-芯片范式”
从行业视角来看,华为提出的τ scaling路径,并不是对现有路线的延续,而是对当前其它半导体发展逻辑的一种偏离。与Intel、TSMC以及NVIDIA等公司所代表的技术方向相比,其差异主要体现在“性能来源”的定义上。
当前其它路径仍然围绕“先进工艺+架构”的组合展开:
-
TSMC / Samsung代表的是“工艺驱动”模式,即通过EUV推进3nm、2nm等节点,持续提供更高晶体管密度与能效基础
-
Intel在推进“先进工艺 + 封装(Intel 4 / 3 + Foveros / EMIB)”的同时,仍然以节点领先作为核心竞争力
-
NVIDIA则是典型的“架构驱动+软件生态”路径,在先进节点之上,通过GPU并行架构与CUDA软件体系放大性能
这些路径的共同前提是:性能提升最终仍然依赖先进制程提供的基础条件。相比之下,华为在τ scaling中采取了不同假设:在先进制程不可持续或不可获得的情况下,通过系统级工程手段,获得近似收益。
挑战与展望
在谈及这一技术路径的后续演进时,何庭波也明确指出,当前仍面临多方面挑战。
首先,是设计方法与工具链的不足,“传统工具链和方法学还无法全面支持自由逻辑设计”,需要围绕Folding构建全新的设计体系,并在实践中持续迭代优化。其次,是能效与热管理压力,随着芯片功耗持续上升,从器件、电路到系统,热问题已经跨越毫瓦到吉瓦的12个数量级,对工程实现提出更高要求。
对此,不仅需要在芯片内部引入高密电容应对瞬态电流冲击,还需要在封装与系统层面对热阻与散热路径进行系统优化。这些挑战意味着,τ scaling并非单一技术问题,而是贯穿全栈的系统工程问题。
尽管挑战明显,何庭波对这一技术路径的前景仍然给出了相当明确的判断。她表示,经过过去六年的实践,“τ scaling路径已经被证明是可行的、通用的、也是可持续的”。从具体演进来看,在电路层面,晶体管密度已从155 MTr/mm²提升至240–300,并正向400以上逼近;在性能方面,CPU核心频率预计将在2031年前突破5GHz。与此同时,在逻辑折叠与软硬件协同优化的叠加下,Kirin SoC能效在未来3到5年内仍有望实现大幅提升。在系统侧,其AI计算平台也将沿着同一思路持续扩展,提供更低时延、更高规模的计算能力。
总结来看,何庭波强调,这一路径的意义并不限于技术突破本身,而在于提供了一种新的演进逻辑——以时间为统一目标,在不完全依赖先进制程的前提下,持续推动半导体系统性能的演进。

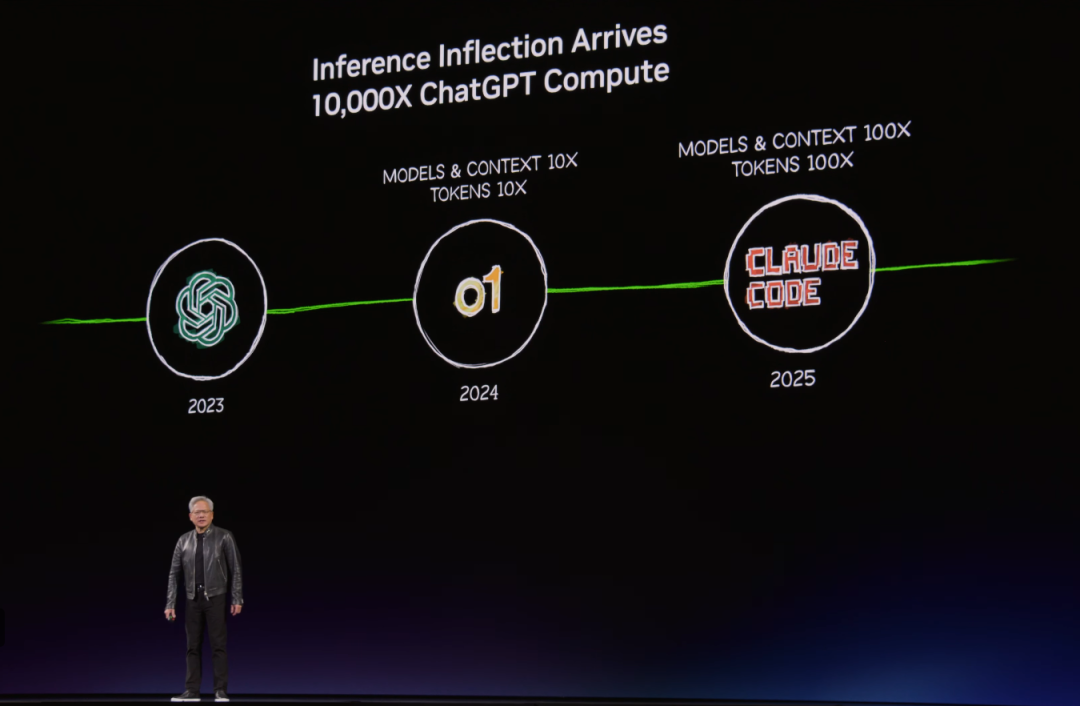












评论区
登录后即可参与讨论
立即登录