为AI研发提速 联发科技重金打造的研发数据中心启用
联发科技7日宣布,位于中国台湾苗栗铜锣科学园区的研发数据中心正式启用,锁定AI时代边缘AI与云端AI研发需求,打造高算力、节能与稳定供电兼具的新一代研发基础设施。该中心是中国台湾首座以NVIDIA DGX B200平台驱动NVIDIA DGX SuperPOD运算丛集打造的AI高算力平台,同时也是第一座大规模导入新式节能浸没式冷却技术的研发数据中心。该数据中心并非仅服务AI模型训练,也肩负EDA
关于「AMD」的技术文章、设计资料与工程师讨论,持续更新。

联发科技7日宣布,位于中国台湾苗栗铜锣科学园区的研发数据中心正式启用,锁定AI时代边缘AI与云端AI研发需求,打造高算力、节能与稳定供电兼具的新一代研发基础设施。该中心是中国台湾首座以NVIDIA DGX B200平台驱动NVIDIA DGX SuperPOD运算丛集打造的AI高算力平台,同时也是第一座大规模导入新式节能浸没式冷却技术的研发数据中心。该数据中心并非仅服务AI模型训练,也肩负EDA
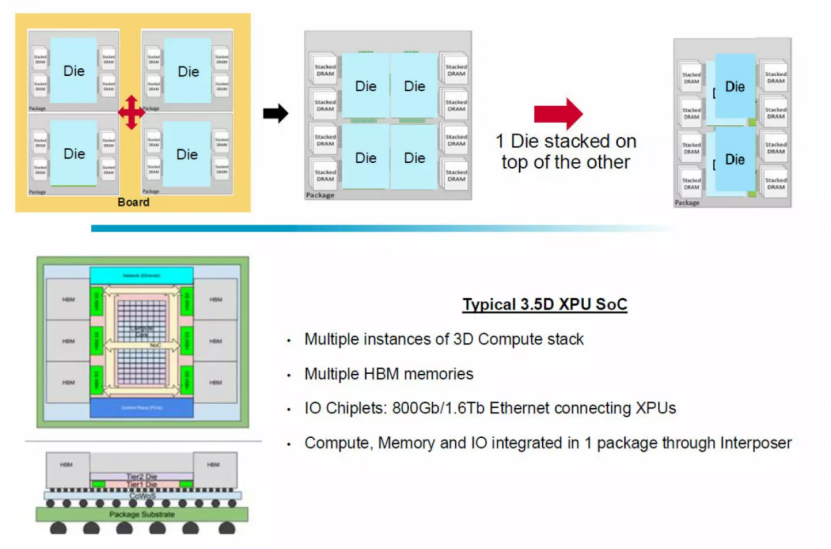
为降低芯片组件间延迟,同时在单封装内为计算引擎及网络专用集成电路集成更多电路,芯片设计厂商跳出二维平面架构、开启元器件垂直堆叠已是大势所趋。 高带宽内存(HBM)堆叠已率先实现 DRAM 内存的垂直化。相较于负责数据传输与运算的专用芯片,内存芯片功耗更低,因此 HBM 堆叠的实现难度相对更低。业界现已采用 2.5D 堆叠技术,通过中介层将 GPU、XPU 等计算芯片与 HBM 堆叠内存互连;AMD

在AMD第四季度财报电话会议上,首席执行官苏姿丰(Lisa Su)博士讨论了人工智能CPU市场的竞争情况。 由于智能体人工智能工作负载的增长,人们普遍认同CPU在人工智能行业中扮演着至关重要的角色,从AMD的主要竞争对手英特尔上个月发布的财报显示其利润大幅超出预期也不难看出 —— 智能体人工智能正在增加服务器计算对CPU的需求。 最开始紧缺的是GPU,随后是内存,而如今紧缺的矛头转向了CPU。据半

在人工智能与边缘计算深度融合的当下,如何用新一代自适应计算技术实现系统高效加速,已经成为产品落地与技术升级的核心。为了帮大家快速掌握硬核开发能力,安富利携手AMD推出“AMD Versal Gen 2 开发实战进阶工坊”系列活动,会在上海、苏州、深圳、广州、北京、南京、杭州、成都等多地举办。 活动将聚焦第二代 AMD Versal™ AI Edge 系列 VEK385 评估套件,通过理论培训与真机

全球半导体行业正经历重大变革,分析师称之为“存储器大转型”。2026年伊始,市场呈现两极分化:AI驱动的基础设施领域蓬勃发展,而消费电子市场则面临供应短缺和价格上涨的困境。 这种分化源于硅晶圆产能分配的巨大转变。高利润的AI组件,尤其是高带宽内存(HBM),挤占了原本用于笔记本电脑、智能手机和游戏机芯片的产能空间。 超级周期的经济效益 对于全球领先的存储器制造商——SK海力士、三星电子和美光科技而

4月29日,存储芯片巨头三星电子(Samsung Electronics)交出了一份令华尔街惊叹的“炸裂”成绩单。受人工智能(AI)基础设施建设带来的存储芯片需求井喷影响,三星2026年第一季度营业利润同比飙升超过750%,创下公司历史新高,且远超分析师预期。 根据三星发布的初步业绩指引,该公司在截至3月31日的第一季度实现了133.9万亿韩元(约合899.6亿美元)的营收,同比增长约70%;营业

本文介绍了Chiplet技术对芯片体积减少的作用,及其关键互连技术。 传统芯片设计依靠不断缩小晶体管尺寸来提升性能,但这一路径正面临越来越高的成本和良率压力。Chiplet技术提供了一种新的思路:将原本集成在一颗芯片上的不同功能模块拆分为多个独立的小芯片,再通过先进封装技术将它们重新集成为一个完整的系统。从外部看,它仍然是一颗芯片;但从内部看,它已经是一个由多个芯粒组成的系统。 为什么需要Chip
数字时代里,算力就是推动技术进步的核心引擎。ASIC芯片和GPU作为两种最核心的算力载体,各自在特定领域都有着不可替代的优势。 今天就把两者的技术差异、性能特点和适用场景说透,不管你是挖矿、做AI还是搞高性能计算,都能得到专业的参考。 1. 先给核心结论 ASIC是为单一任务优化的专用芯片,GPU是面向通用并行计算的灵活方案,两者没有绝对好坏,只看你用在什么地方。核心差异我整理了一张对比表,一目了

[ ](https://mp.weixin.qq.com/s?__biz=MzIxMDE0NTM0Nw==&mid=2649358184&idx=3&sn=83907863a30de303c57f3c565305c6bb&scene=21#wechat_redirect) 今年是施乐Star 8010电脑发布45周年,这款1981年诞生的设备不仅是世界上第一台搭载图

在人工智能与边缘计算深度融合的当下,如何用新一代自适应计算技术实现系统高效加速,已经成为产品落地与技术升级的核心。为了帮大家快速掌握硬核开发能力,安富利携手AMD推出“AMD Versal Gen 2 开发实战进阶工坊”系列活动会在上海、苏州、深圳、广州、北京、南京、杭州、成都等多地举办。 活动将聚焦第二代 AMD Versal™ AI Edge 系列 VEK385 评估套件,通过理论培训与真机
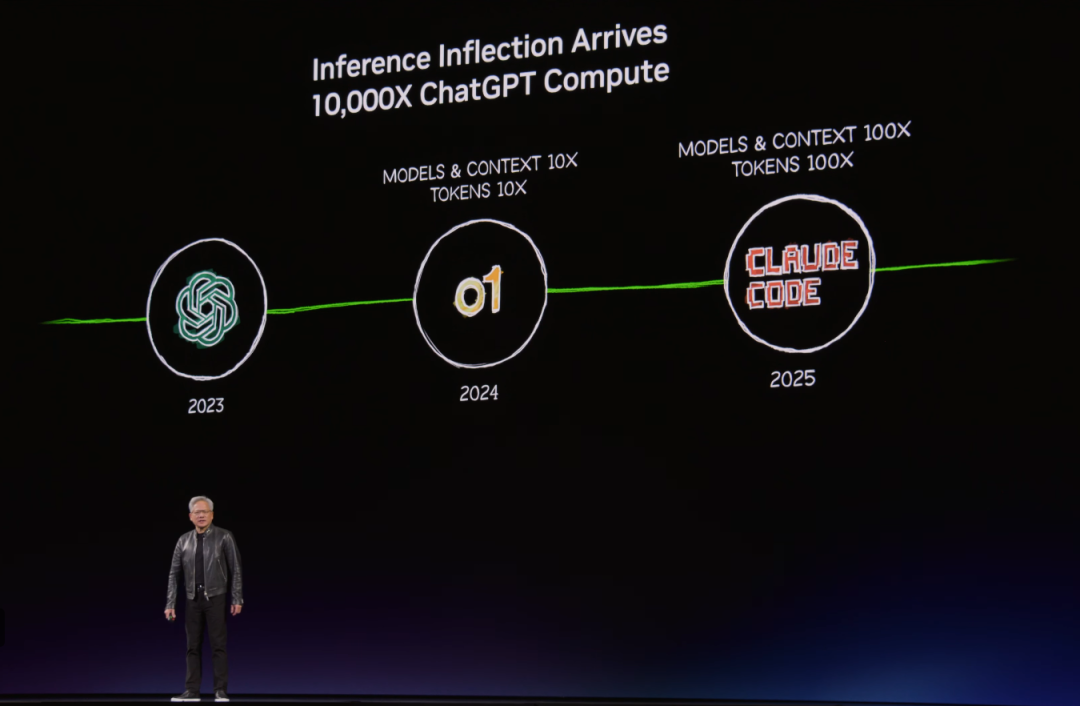
[ ](https://mp.weixin.qq.com/s?__biz=MzA5MDk2NTEwNQ==&mid=2656510277&idx=1&sn=8b196489488c2621d143b38b6eaa1b09&scene=21#wechat_redirect) 当英伟达CEO黄仁勋在2026年GTC大会上抛出"The Inference Inflecti
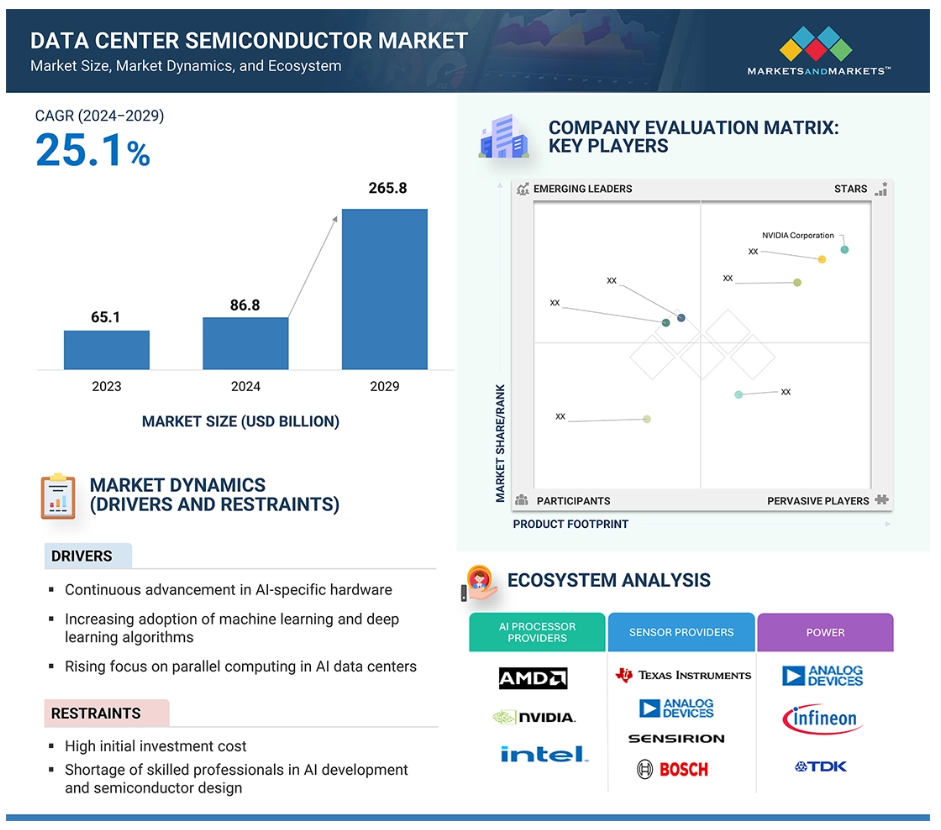
NEWS MarketsandMarkets最新分析报告预计,全球数据中心半导体市场规模将从2024年的868亿美元增长至2029年的2658亿美元,2024-2029年复合年增长率(CAGR)达25.1%。 市场增长的核心驱动因素包括:AI及生成式AI工作负载的快速扩张、超大规模云服务商的投入加码、高性能计算与加速处理器需求攀升、高带宽内存(HBM)等先进存储技术的普及,以及现代云数据中心基础

内存接口芯片作为内存模组(RDIMM)的核心组件,在过去几年里也借势实现了高速增长。 DDR5如今已全面进入主流市场。回顾其商用进程,2022年下半年,DDR5率先在服务器领域启动部署;2023年,随着英特尔、AMD支持DDR5的服务器CPU大批量出货,主流数据中心厂商开始加速产品迭代;2024年至今,DDR5正式跃升为服务器内存市场的主流配置。 2025年下半年起,存储市场进入结构性缺货阶段。市
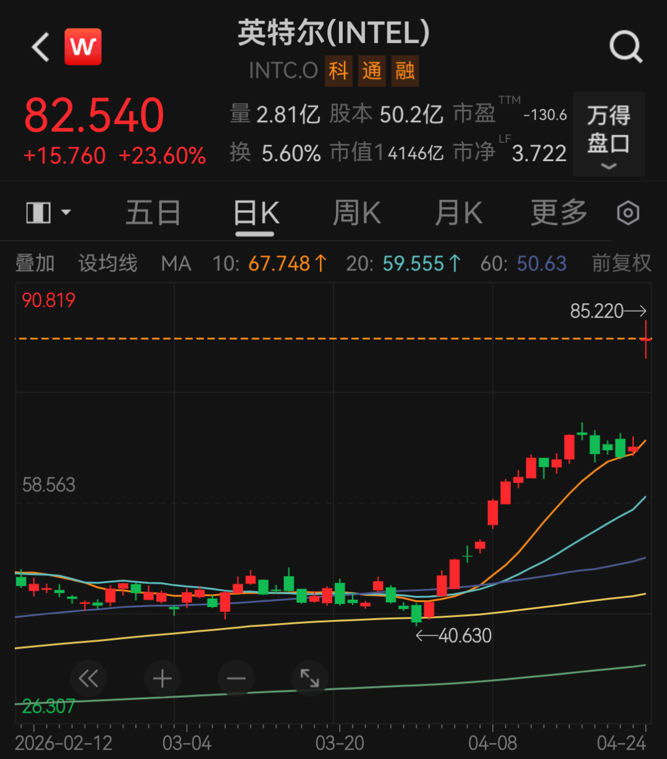
CPU市场正迎来一轮罕见的全面涨价周期。 据ODM厂商透露,自2026年3月起,消费级CPU价格已上涨5%—10%,服务器CPU涨幅更达10%—20%。供应链消息指出,英特尔(Intel)与AMD两大巨头正在筹备第三季度的进一步涨价,而CPU平均交货周期已从此前的1—2周大幅延长至8—12周。 这一轮涨价不仅牵动着下游整机厂商的神经,更在资本市场掀起巨浪。4月24日,英特尔股价收盘暴涨23.6%,

4月28日消息,欧盟统一充电接口法规正式扩展至笔记本电脑领域。这意味着从即日起,所有在欧盟市场销售的新款笔记本电脑,必须配备USB-C接口用于充电。 早在2024年12月28日,欧盟便已强制要求手机、平板电脑、数码相机、耳机、游戏机及便携扬声器等中小型电子设备统一使用USB-C接口。经过一年多的市场磨合与技术铺垫,新规终于覆盖技术门槛更高的笔记本电脑领域。 新规的核心逻辑简单而有力:提升消费者便
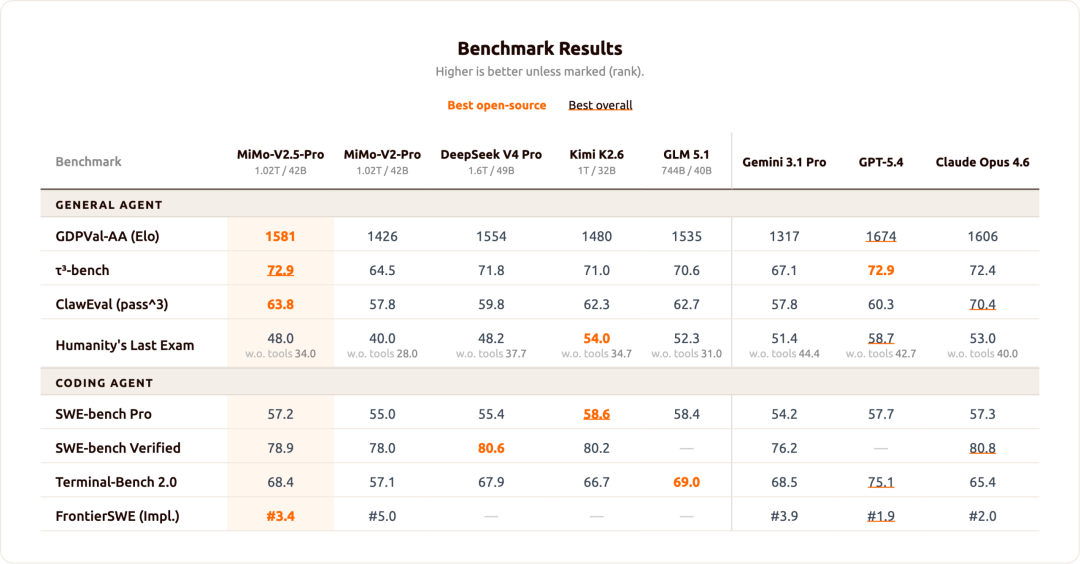
今天,我们正式开源 Xiaomi MiMo-V2.5 系列,采用 MIT 协议,支持商用推理部署与二次训练,无需额外授权。 开放协议,全量开源 MiMo-V2.5 系列模型已于 4 月 23 日开启公测,感谢所有用户在此期间的热情反馈与鼓励。 这个系列包含两款模型,均支持 100 万上下文窗口: MiMo-V2.5-Pro:面向复杂的任务场景,深度适配 Agent 与 Coding 应用,在
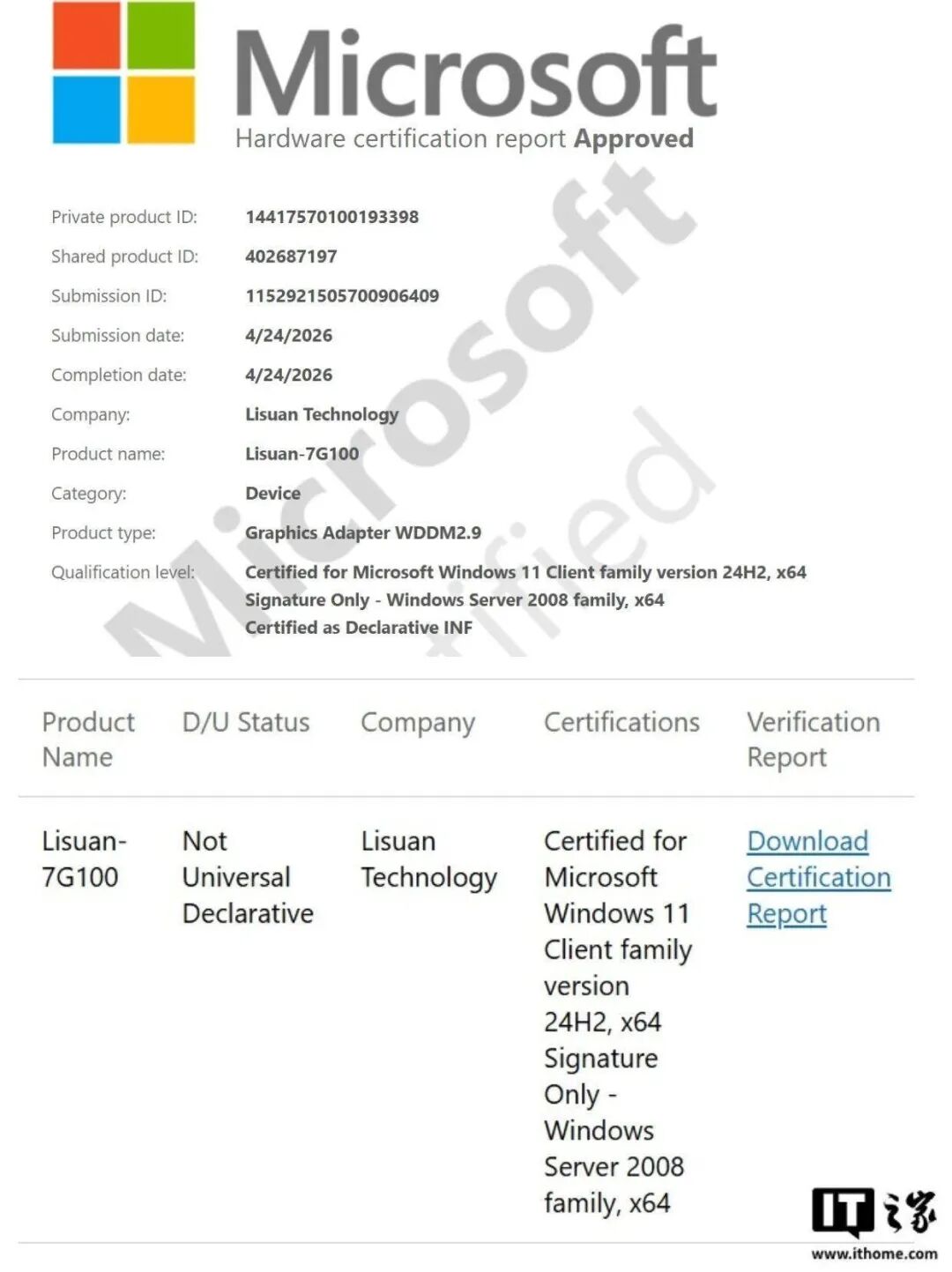
4月26日,据微软官方认证公示信息显示,砺算科技自研高性能图形GPU 7G100系列正式完成微软WHQL(Windows Hardware Quality Labs,Windows硬件质量实验室)全维度合规认证。至此,砺算科技成为国内首家、全球第四家通过该项严苛认证的GPU设计企业,与英伟达、AMD、英特尔三大全球图形算力巨头并列第一梯队。 此次认证落地,并非单一产品技术参数的常规达标,而是国产通
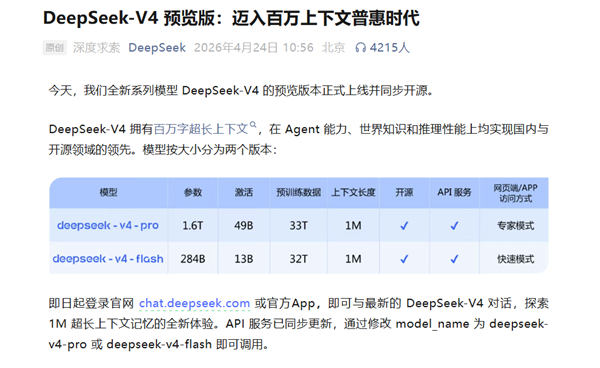
黄仁勋最担心的事,还是发生了!最新的DeepSeek V4版本,把“第一次”给了华为芯片。 “不诱于誉,不恐于诽,率道而行,端然正己。”带着这十六字理念,4月24日,DeepSeek V4预览版正式发布。距离上一版V3.2更新,已经过去了近五个月。 当下海外主流大模型,基本保持三个月一轮的快速迭代。相比之下,DeepSeek的节奏看似偏慢,甚至一度被外界质疑掉队。 就在前几天,GPT Imag

模拟芯片龙头的成绩单,成了半导体行业复苏的最强信号。 4月23日,德州仪器(TXN)公布2026年第一季度财报,业绩全面碾压市场预期。公司Q1营收达48.3亿美元,同比增长19%,环比增长9%;每股收益(EPS)为1.68美元(含0.05美元离散税项收益),同比增长31%,远超市场预期的1.36美元。财报发布后,公司股价周四飙升约19%,创下2000年以来最大单日涨幅,今年迄今累计上涨约60%

当AI加速器陷入“算力过剩、数据饥渴”的怪圈,决定性能上限的早已不是计算核心的数量,而是内存带宽与互联架构。本文带你跳出“堆算力”的误区,重新审视AI硬件的真正战场。 现在跑大模型,大家都在喊算力不够,要堆更多核心。 但现在AI加速器的性能瓶颈,早就不是计算单元本身,而是内存和互联架构。 AI加速器到底是怎么进化到今天的 AI硬件的发展路线其实非常清晰,就是从通用到专用一步步走过来的。 最早大家都