本文将详细介绍DTCO(设计-工艺协同优化)与STCO(系统-工艺协同优化)。
随着半导体工艺制程不断向3nm及以下演进,一个越来越清晰的趋势是:单纯依靠缩小晶体管尺寸来提升性能的传统路径,已不再像过去那样有效。在这一背景下,DTCO(设计-工艺协同优化)与STCO(系统-工艺协同优化)先后走上前台,成为延续芯片性能增长的关键方法论。
发展背景
过去几十年,半导体性能提升主要依赖“工艺驱动”:制程节点从微米级走向纳米级,每前进一步,都意味着更强的性能、更低的功耗和更高的集成度。然而,20nm之后,成本与性能已不再线性改善;3nm以后,行业进入所谓的“less happy scaling era”。芯片越来越大、设计越来越复杂,单纯靠缩节点拿性能的时代已经结束。
从更具体的指标看,线宽缩小正在逼近物理极限(约1nm停止),随之而来的是线宽电阻上升、漏电增加、寄生效应增强。晶体管密度提升速度也在放缓:平面工艺时代每代约提升1.95倍,进入FinFET后每代仅提升约1.46倍。性能提升在放缓,但设计复杂度却呈指数级上升。
因此,行业共识是:摩尔定律并未完全终结,但其驱动力已经从“物理缩放”转向了“设计-工艺-系统协同驱动”。
DTCO
DTCO的全称为Design-Technology Co-Optimization,其核心理念是:不再单纯依赖工艺节点进步,而是将设计(电路、版图、架构)与工艺(器件、材料、结构)放在同一框架内进行双向联合优化。优化的统一指标是PPAC,即功耗、性能、面积和成本。
具体而言,DTCO做的事情是从晶体管到系统逐层拆解优化:包括晶体管的导通电流与电容、布线层的电阻电容延迟、SRAM的面积与最小工作电压及良率等。关键问题不再是某个单一环节的性能瓶颈,而在于每一层之间的协同失衡。
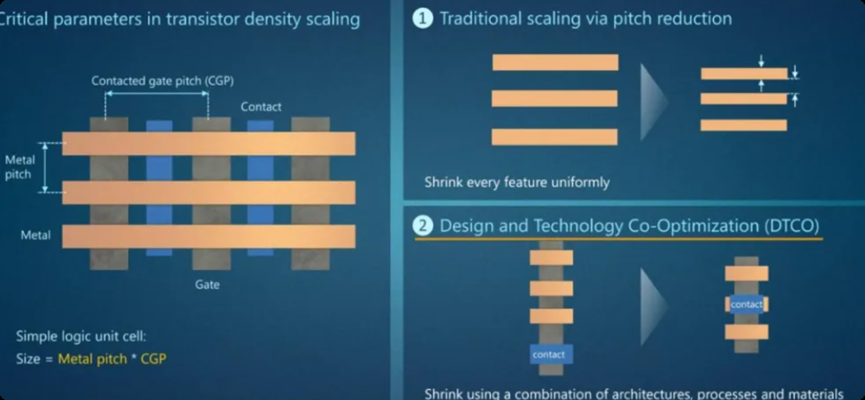
一个重要变化是:性能瓶颈正从前端工艺(晶体管)向后端工艺(互连与供电)迁移。互连延迟成为关键路径,电压降(IR Drop)显著恶化,电源轨电阻急剧上升。针对这一问题,DTCO的一个重要技术抓手是背面供电(BSPDN)。通过将供电网络移到芯片背面,可以带来约5%的性能提升或10%的功耗下降。其核心逻辑是通过结构改变来解决问题,而不是继续缩小尺寸。
STCO
当DTCO提供的优化空间仍不足以满足需求时,行业进一步提出了STCO,即System-Technology Co-Optimization。STCO将优化边界从芯片内部扩展到系统层级,包括架构设计、封装技术、3D集成等。
STCO带来的核心变化有三点。第一,单一大芯片正在被Chiplet(芯粒)或多die方案取代。单片大芯片良率可能低至15%,而采用多个小芯粒组装可将良率提升到37%,单片SoC的经济性开始失效。第二,不同功能模块可以采用各自最优的工艺节点:高性能计算模块使用最先进节点,输入输出、模拟电路则使用成熟节点,从而替代过去“统一工艺”的做法。第三,互连方式从2D走向2.5D或3D集成,通过硅通孔(TSV)、3D堆叠、Chiplet互连等技术,将内存与计算垂直整合。空间维度成为新的性能提升维度。
本质上,STCO要求在新结构(如晶体管上下堆叠的CFET、3D芯片堆叠、背面供电等)引入时,必须通过系统级协同设计才能发挥其全部价值。新结构本身并不意味着自动提升性能。

关键支撑
无论是DTCO还是STCO,其底层都离不开对材料层面的精确掌控。随着工艺复杂度急剧上升,从FinFET到GAA,再到未来的CFET和二维材料,每一步都增加了开发成本与风险。因此,材料建模成为一项核心能力,用于研究新沟道材料、金属栅工程、缺陷与漏电、掺杂扩散等问题。性能提升开始依赖材料层面的微观调控。
与此同时,半导体研发方法正在从“实验驱动”转向“仿真驱动”。通过原子级建模工具(如QuantumATK)、TCAD到SPICE的链路仿真、以及材料数据库,工程师可以在制造前预测器件性能,快速筛选材料与工艺路径。更进一步,跨尺度建模能力(从原子级缺陷、界面,到器件电学性能,再到电路PPA,最后到系统级3DIC封装)将全链路打通。未来行业的竞争,很大程度上将是跨尺度建模能力的竞争。
综合来看,半导体行业的创新重心已经完成了三次迁移:过去是工艺驱动(缩节点即性能提升),现在是DTCO驱动(设计与工艺协同优化),未来将是STCO驱动(架构、封装与系统整体优化)。
换言之,先进制程不再是唯一的答案。真正的竞争正在转向谁能重构系统架构与集成方式,谁能更高效地实现设计、工艺、材料与系统的全局协同。半导体的进步,已经从“做晶体管”转向“做系统”,从“拼节点”转向“拼协同能力”。











评论区
登录后即可参与讨论
立即登录