新品 | 栅极驱动器搭配1200 V碳化硅SiC功率开关的半桥配置评估板
新品 栅极驱动器搭配1200 V碳化硅SiC 功率开关的半桥配置评估板 英飞凌EVAL-1ED3321MC12N-SIC评估板是模块化评估平台的一部分,可简化EiceDRIVER™ 1ED3321MC12N栅极驱动器与功率开关在半桥配置下的测试验证。该评估板可独立工作,也可插入EVAL-DCLINK-DPT主板,帮助设计工程师测量参数或进行双脉冲测试(DPT),并且兼容EiceDRIVER™ 1
纳米网半导体频道 — 提供半导体领域最新资讯、技术文章和行业动态。

新品 栅极驱动器搭配1200 V碳化硅SiC 功率开关的半桥配置评估板 英飞凌EVAL-1ED3321MC12N-SIC评估板是模块化评估平台的一部分,可简化EiceDRIVER™ 1ED3321MC12N栅极驱动器与功率开关在半桥配置下的测试验证。该评估板可独立工作,也可插入EVAL-DCLINK-DPT主板,帮助设计工程师测量参数或进行双脉冲测试(DPT),并且兼容EiceDRIVER™ 1
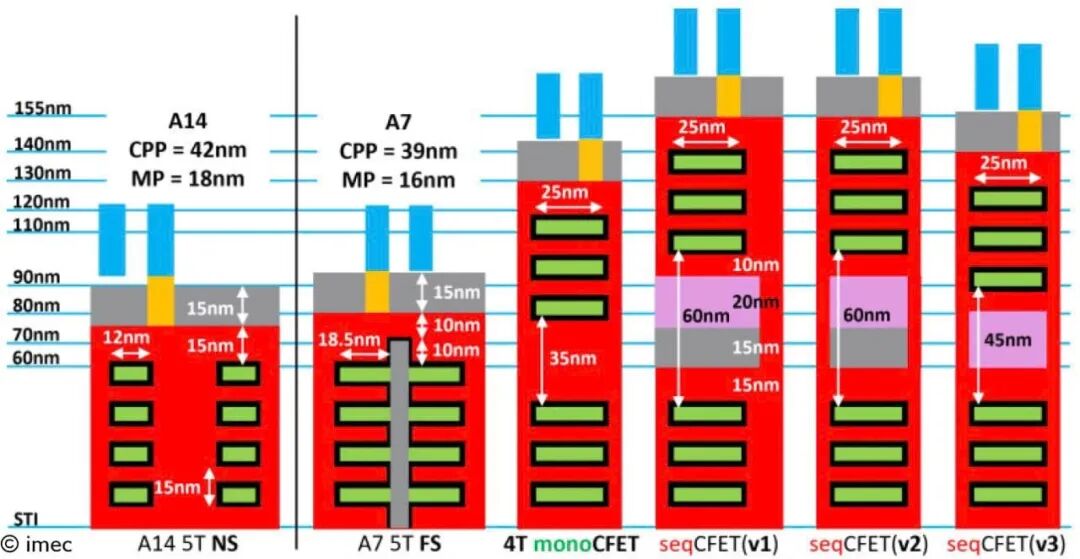
本文主要讲述CFET cells。 在现代半导体技术中,随着工艺节点的不断缩小和对性能、功耗的严格要求,CFET(Complementary FET) 技术逐渐成为一个研究热点。CFET 是基于互补型场效应晶体管(CMOS)技术的创新,采用了垂直集成的结构,有效提高了集成度和性能。为了实现CFET技术的全面应用,前端工艺(FEOL)、后端工艺(BEOL)以及背面互连(Backside Interc
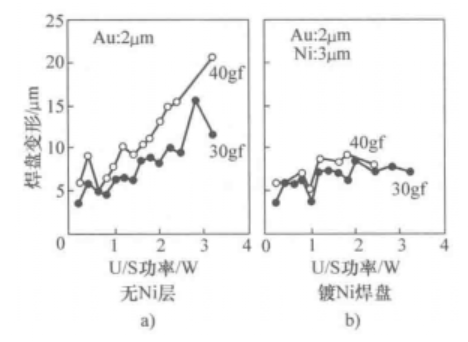
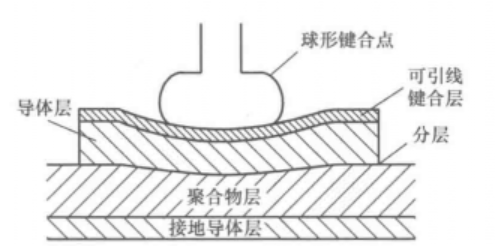
本文主要讲述软基材上的引线键合技术。 传统的厚膜混合电路使用陶瓷基板,键合焊盘直接在陶瓷基材上涂覆一层Au或者Ag(合金)厚膜层。与陶瓷封装上的键合相比,这不会引入更多特定问题。因此,采用最佳的冶金系统和键合程序,可以获得高良率(≤50ppm缺陷)。然而,其他塑料基材(PCB、BGA和SIP等)可能会引入重大的键合问题,这些基材是由常见的玻璃纤维或其他填料层压形成的环氧类聚合物,在其玻璃化转变温度
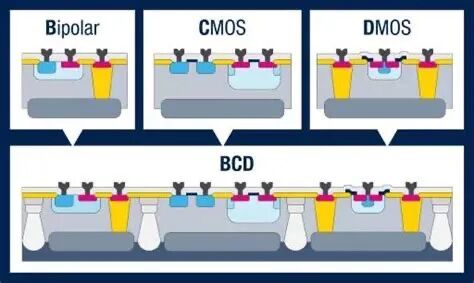
本文主要讲述BCD技术如何融合CMOS、DMOS和BJT。 在电源管理芯片的世界里,有一项技术被誉为“瑞士军刀”——它就是BCD工艺。BCD这个名字,其实是三种半导体器件的缩写:Bipolar(双极型晶体管)、CMOS(互补金属氧化物半导体)和DMOS(双扩散金属氧化物半导体)。为什么要把这三种器件塞进同一颗芯片?它们各自扮演什么角色?工艺上又有什么不同?今天我们就来拆解这颗“三合一”的神奇芯片。
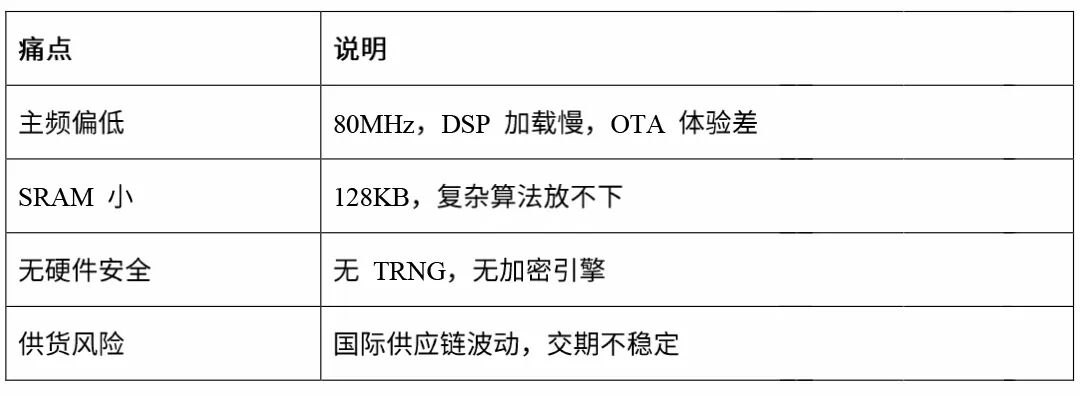
800G/1.6T高速光模块MCU 当前800G/1.6T高速光模块MCU市场呈现“海外主导、国产突破”的竞争格局。据行业数据,2026年全球高端光模块主控芯片市场规模达10-15亿美元,国产化率不足5%。 光模块行业正在经历一场 “双向升级”: 🔸 产品端:从 400G 向 800G / 1.6T 快速演进 🔸 安全端:从“可选认证”走向“强制身份认证” MCU 作为光模块的“大脑”,既要解决当

本文主要讲述芯片生产中的Pirun是什么,有什么用。 Pirun的基本概念与作用 在半导体晶圆厂(Fab)中,Pirun是Pilot Run的简称,指试生产或小批量生产。具体而言,它是在正式大规模量产之前,使用少量晶圆进行的一批小规模测试生产。这一环节的核心目的,是在可控的小范围内验证工艺的稳定性,确认新的工艺流程是否能满足要求,从而在正式大批量投产前及时发现并调整问题,降低经济损失。与常规的Mo
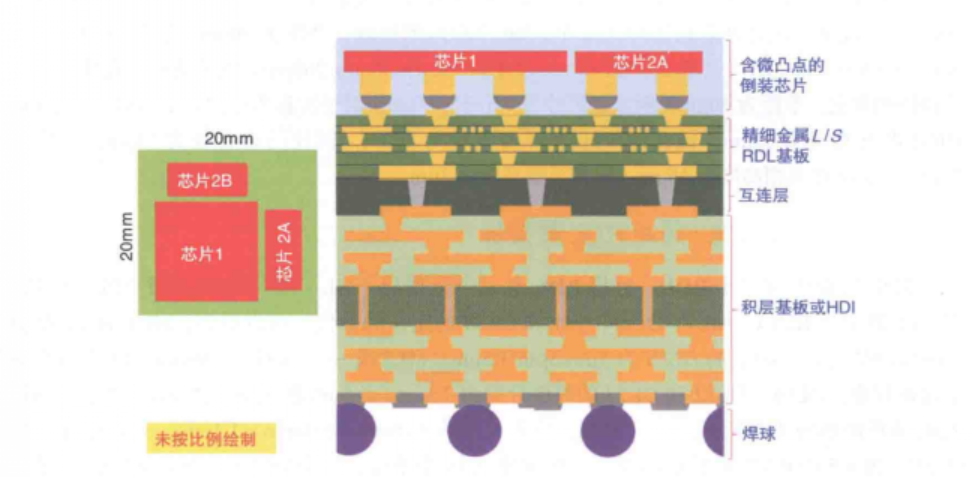
本文主要讲述基于互连层的2.3DIC集成。 基本结构 图1为高密度有机混合基板上芯粒异质集成的俯视图和截面图。它由4个主要部分组成:①含微凸点的芯片;②精细金属L/S RDL基板或有机转接板(约37um厚);③互连层(约60um厚);④HDI印制电路板(PCB)(约1mm厚),如图2所示。 测试芯片 使用的测试芯片如图3所示。可以看到,大芯片(芯片1)的尺寸为10mm×10mm×150um,其
韩国有个段子正在流传:2026年最抢手的相亲对象,不是医生、不是律师,而是SK海力士的员工。 社交媒体上,印着“SK Hynix”字样的工装夹克被捧为“终极相亲战袍”,韩国搞笑节目《SNL Korea》直接拍了个讽刺短片——奢侈品店员冷落衣着普通的顾客,一看对方衣服里露出海力士标志,脸色瞬间从“你是谁”切换成俯首帖耳的“海力士大人(Lord Hynix)”。 海力士员工内部还流传着另一条“社交密码
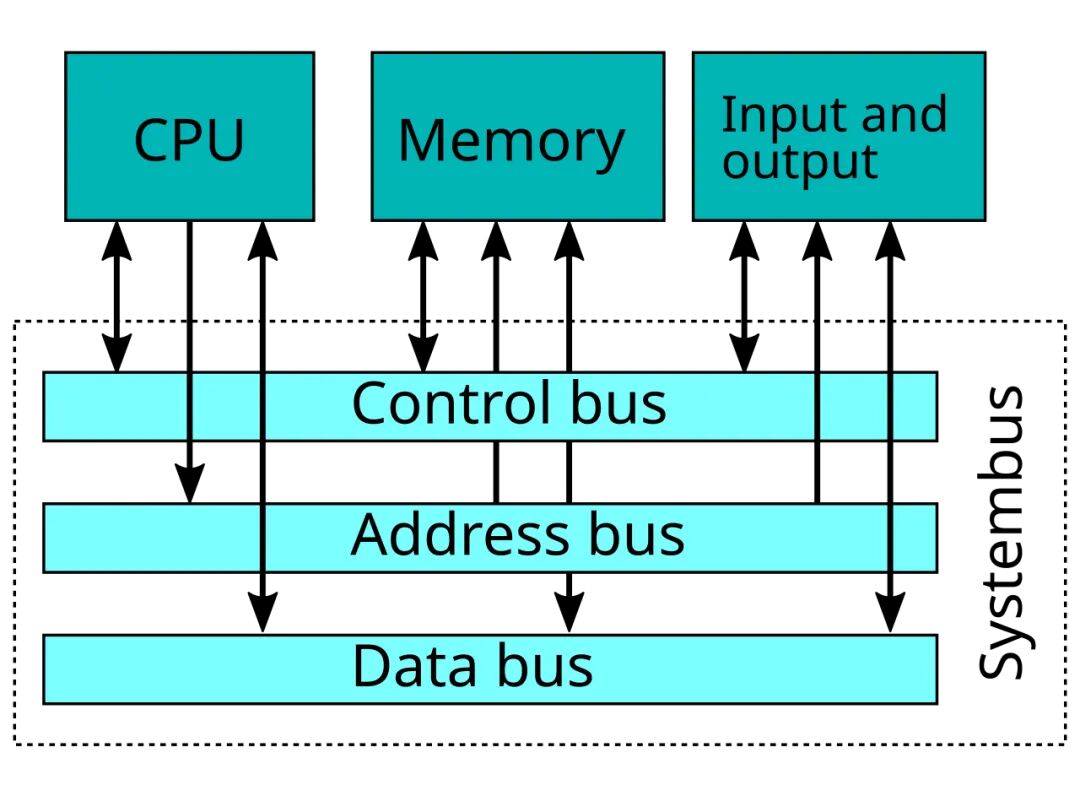
“内存墙”一词最早出现于20世纪90年代中期,当时弗吉尼亚大学的研究人员William Wulf和Sally McKee合著了“Hitting the Memory Wall: Implications of the Obvious”(撞上内存墙:显而易见的影响)一文。该研究揭示了由于处理器速度与动态随机存取存储器(DRAM)性能之间的差距而导致的内存带宽瓶颈问题。 这些发现指出了工程师们在过

5月8日消息,AMD正式发布Instinct MI350P PCIe GPU加速卡,这是AMD四年来首款PCIe接口的Instinct产品,基于CDNA 4架构和台积电3nm工艺,面向企业AI推理场景,主打"即插即用"的部署体验。 MI350P本质上是MI350X的砍半版本,采用4颗XCD(MI350X为8颗),搭配1颗基于台积电6nm的IO芯片。 核心规格包括128个计算单元(8192个流处理
航顺芯片的主要产品阵列包括基于 ARM Cortex-M0、M3、M4以及 RISC-V 等内核的二十九大家族 300 余款工业 / 商业 / 车规级、通用 / 专用 / 定制化 32 位 MCU,以下是部分具体产品家族: 超低价版 HK32F001家族(极致成本杀手,性价比**之巅,堪称32位**MCU终结者) 内核及主频:基于ARM Cortex-M0内核,主频最高24MHz。 存储容量:最大
本文介绍了扫描电镜中的二次电子掺杂衬度的物理机制。 二次电子(SE)发射强度是扫描电子显微镜(SEM)进行样品形貌表征时最常使用的信号,借助现代场发射电子源与高灵敏度探测器,高端SEM已可稳定实现亚纳米级的空间分辨率。 然而,SE信号在形貌表征中的压倒性应用,长期掩盖了其对材料本征物理属性的敏感响应能力,包括功函数、电子阻止本领以及电子平均自由程等。尤其值得关注的是,相邻区域之间的功函数差异可以被
本文介绍了IC芯片中聚合物基板的键合效果优化。 研究发现,在IC芯片上的有源区内进行热超声键合的最佳聚酰亚胺具有最高的弹性模量E,弹性模量即应力除以应变且需低于弹性极限。这一材料性能与聚合物的刚性相关,因此键合过程中材料形成的凹杯或压痕也与弹性模量有关。对于各向异性材料,压缩模量能更好地反映柔软性,但拉伸模量通常是唯一可测量的模量特性。键合过程中,无支撑的焊盘和聚合物的总形变见图1,这种形变会吸收
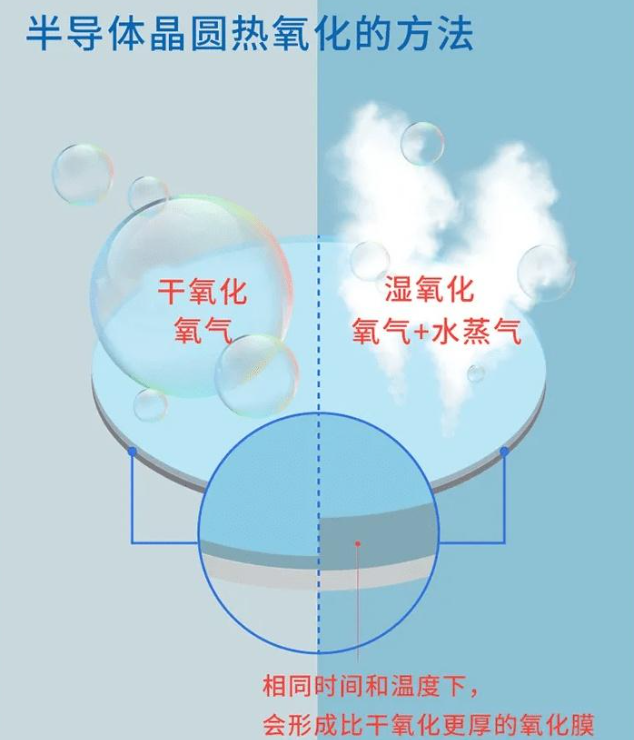
本文介绍了硅片的热氧工艺与退火。 为什么要给硅片“氧化”? 纯硅本身并不绝缘。要让电流在该走的时候走、不该走的时候停,必须在特定区域形成绝缘层。二氧化硅恰好是完美的天然选择:它与硅的晶格匹配良好、击穿强度高、化学性质稳定。氧化层在芯片中扮演三种角色: 栅介质:MOS晶体管中控制沟道开闭的核心绝缘层,厚度可薄至1-2纳米(仅几层原子)。 隔离层:像“围墙”一样隔开不同器件,防止电流串扰,典型

速芯微电子全新升级款FS112A,作为 FS112K 系列实力迭代新品,重新拉高了 TypeA 口快充协议芯片的性价比水准。它在原有协议基础上全面扩容,同时耐压规格升级、外围电路优化,兼容性更强,稳定性更高! 核心亮点 ✅1. 协议丰富兼容性强 支持QC3.0+/QC2.0、AFC、FCP、SCP、Apple 2.4A、BC1.2、高压/低压直充等主流协议; 不同型号(FS112AC / AD /
AI算力的边界在哪里?过去两年,AI大模型的军备竞赛让全球科技巨头疯狂抢购GPU。然而,英伟达CEO黄仁勋却不止一次指出:“未来十年,算力的天花板将由光传输效率决定。”这句话道出了一个被市场长期忽略的真相——即便你手握百万张GPU,如果数据在它们之间的流转速度跟不上,庞大的算力集群不过是一堆昂贵的电子砖头。AI基础设施的内部革命,正悄然转向一个更底层、更隐秘的战场。在这个战场上,一种名为磷化铟(I
Q1 基于“玲珑”峨眉VPU IP可以实现单独编码器或单独解码器吗? A 可以,“玲珑”峨眉是编解码合一架构,可配置为纯编码、纯解码、编解码合一三种形态,纯编码或纯解码形态面积更小。 Q2 基于“玲珑”峨眉VPU IP实现不同配置,交付时间是多久? A 通常情况下,不同配置的“玲珑”峨眉VPU IP可以2周内给到初始版本,1个月内完成最终交付,能够满足芯片开发的进度需求。 Q3 AI高清视频场景下
5月7日,2026新紫光集团创新峰会在北京隆重举行。峰会以“智链共生·聚创未来”为主题,锚定聚焦智能科技产业,推动“协同共赢+突破创新”核心战略,明确三大支柱领域与三大赋能举措,为新紫光集团高质量发展指明方向。作为集团旗下核心企业,紫光展锐紧随战略步伐,深耕端边AI赛道,发布多款端边AI产品和解决方案,携手全球伙伴共筑端侧AI终端新生态。 战略定力:新紫光集团聚焦智能科技产业 推动“协同共赢+突破

新品速递 TJA1410和TJF1410是符合10BASE-T1S规范的物理介质相关 (PMD) 收发器, 丰富了恩智浦的多节点以太网网络产品组合。这些器件专为在严苛环境确保卓越电磁兼容 (EMC) 性能而设计,支持通过以太网数据线,基于3引脚Open Alliance (OA) TC14-TC10远程唤醒标准接口实现通信。 TJA1410按照ISO 26262 ASIL B功能安全等级设计,满

i.MX 937片上系统 (SoC) 在可靠且可扩展的平台上平衡了高性能边缘AI与成本及功耗优化的设计。 边缘计算设计人员长期面临两难抉择:要么选择性能不足的入门级芯片,要么采用价格高昂的高端处理器。由于中间方案的缺失,无论是向上扩展还是向下简化设计,都变得困难重重且代价不菲。随着设计方案的变更与产品线的拓展,工程师亟需具备充分灵活性与可扩展性的微处理器 (MPU) 产品系列,以满足其持续发展的










